最近在做一个关于可配置爬虫的项目,里面涉及到一些针对爬取内容自定义解析的需求,为了实现这个需求需要能够对html(针对网页)和json(针对app)实现字段定位,在经过一些调研以及参考了部分爬虫框架后,发现了XPath和JsonPath这两种描述语言。
XPath
XPath,全称 XML Path Language,即 XML 路径语言,它是一门可用来在 XML 文档中对元素和属性进行遍历的语言。XPath 最初设计是用来搜寻XML文档的,但是它同样适用于 HTML 文档的搜索。
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
XPath语法
下面的语法选取一下xml作为示例:
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
选取节点
下面列出了一些最有用的路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
| text() | 获取节点文本 |
在下面的表格中,列出了一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点 |
| /bookstore | 选取根元素 bookstore 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置 |
| //@lang | 选取名为 lang 的所有属性。 |
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点,被嵌在方括号中。
在下面的表格中,列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position() < 3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=‘eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
| bookstore/book[1]/price/text() | 获取bookstore第一个book子节点的price的子节点的值 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 路径表达式 | 结果 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
在下面的表格中,列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
选取若干路径
通过在路径表达式中使用"|"运算符,可以选取若干个路径。
XPath用于html
XSoup
jsoup是一款Java的HTML解析器,主要用来对HTML解析,但是他只支持针对css的selector语法,但不支持XPath,因此我采用了WebMagic里面使用的XSoup,Xsoup是基于Jsoup开发的一款XPath解析器,发展到现在,已经支持爬虫常用的语法。具体语法可见WebMagic作者文档:http://webmagic.io/docs/zh/posts/ch4-basic-page-processor/xsoup.html。
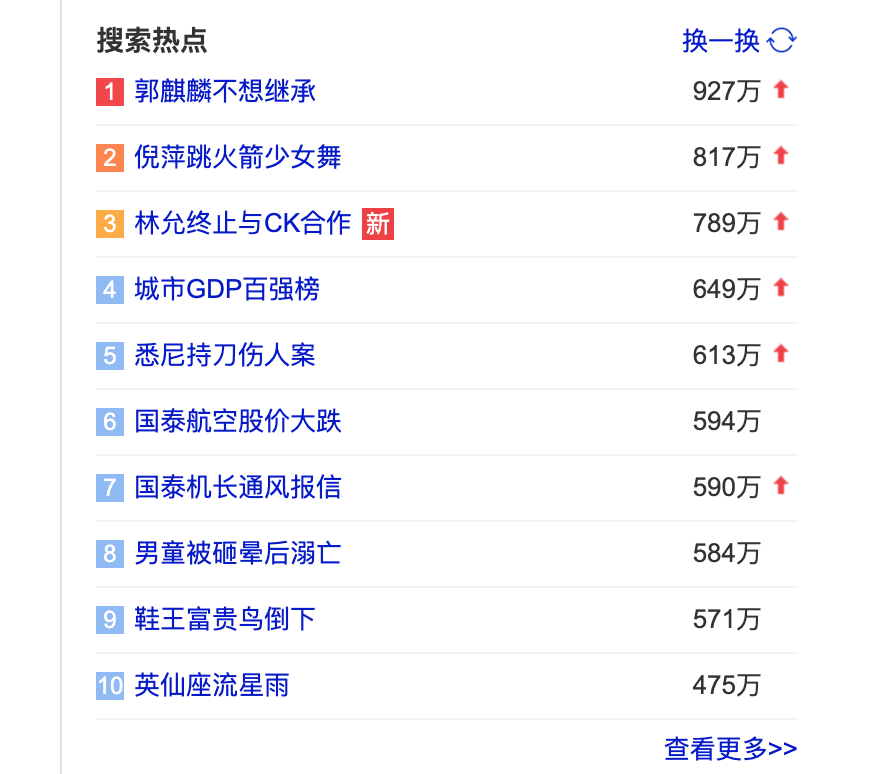
在此实例中我爬取的是百度搜索页中的搜索热点里面的文本内容,一共10条。
public class XPathDemo {
public static void main(String[] args) {
XPathDemo xPathDemo = new XPathDemo();
xPathDemo.xPathTest();
}
public void xPathTest() {
try {
String filePath = XPathDemo.class.getClassLoader().getResource("file/test.html")
.getPath();
Document document = Jsoup.parse(new File(filePath), "utf-8");
Elements dataElement = Xsoup
.compile(
"//*[@id="con-ar"]/div/div/div/table/tbody[position()<3]//tr/td[1]/span[1]/a")
.evaluate(document).getElements();
List<String> data = Xsoup
.compile("//*[@id="con-ar"]/div/div/div/table//tbody//tr/td[1]/span[1]/a/text()")
.evaluate(document).list();
System.out.println(dataElement);
System.out.println(data);
} catch (IOException e) {
e.printStackTrace();
}
}
private String getHtml() {
return "";
}
}
JsonPath
JsonPath 是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,能够快速定位Json中的指定字段。
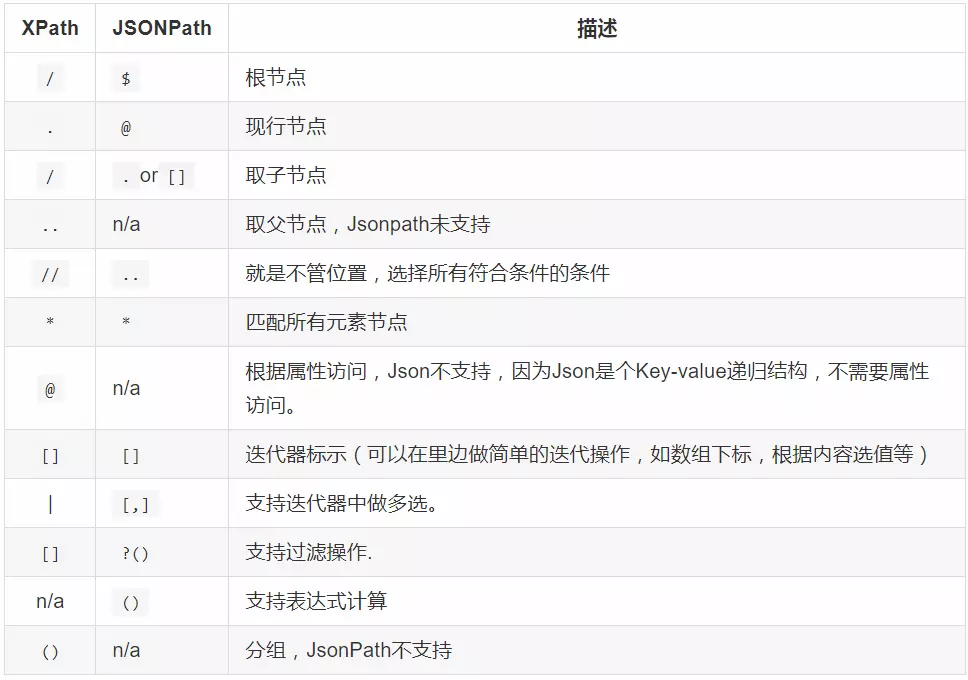
下图是从网上找到的JsonPath和XPath对应的语法表达式:
下面给出如下的Json串:
{
"errcode": 0,
"msg": "ok",
"data": {
"cities": [
{
"id": 97,
"url": "https://oss.jojotoo.com/resources/city/v3/shanghai.png?x-oss-process=style/webp",
"name": "上海"
},
{
"id": 99,
"url": "https://oss.jojotoo.com/resources/city/v3/beijing.png?x-oss-process=style/webp",
"name": "北京"
},
{
"id": 100,
"url": "https://oss.jojotoo.com/resources/city/v3/hangzhou.png?x-oss-process=style/webp",
"name": "杭州"
},
{
"id": 101,
"url": "https://oss.jojotoo.com/resources/city/v3/nanjing.png?x-oss-process=style/webp",
"name": "南京"
},
{
"id": 103,
"url": "https://oss.jojotoo.com/resources/city/v3/chengdu.png?x-oss-process=style/webp",
"name": "成都"
},
{
"id": 107,
"url": "https://oss.jojotoo.com/resources/city/v3/guangzhou.png?x-oss-process=style/webp",
"name": "广州"
},
{
"id": 108,
"url": "https://oss.jojotoo.com/resources/city/v3/shenzhen.png?x-oss-process=style/webp",
"name": "深圳"
},
{
"id": 109,
"url": "https://oss.jojotoo.com/resources/city/v3/chongqing.png?x-oss-process=style/webp",
"name": "重庆"
},
{
"id": 110,
"url": "https://oss.jojotoo.com/resources/city/v3/xi'an.png?x-oss-process=style/webp",
"name": "西安"
},
{
"id": 113,
"url": "https://oss.jojotoo.com/resources/city/v3/tianjin.png?x-oss-process=style/webp",
"name": "天津"
},
{
"id": 114,
"url": "https://oss.jojotoo.com/resources/city/v3/wuhan.png?x-oss-process=style/webp",
"name": "武汉"
},
{
"id": 117,
"url": "https://oss.jojotoo.com/resources/city/v3/changsha.png?x-oss-process=style/webp",
"name": "长沙"
},
{
"id": 135,
"url": "https://oss.jojotoo.com/resources/city/v3/suzhou.png?x-oss-process=style/webp",
"name": "苏州"
}
],
"current_city": {
"id": 97,
"url": "https://oss.jojotoo.com/resources/city/v3/shanghai.png?x-oss-process=style/webp",
"name": "上海"
}
}
}
针对此Json串,下面给出JsonPath示例获取每个城市的name字段。
public class JsonPathDemo {
public static void main(String[] args) {
JsonPathDemo jsonPathDemo = new JsonPathDemo();
jsonPathDemo.testJsonPath();
}
private void testJsonPath() {
String jsonStr = getJson();
List<String> targetList = JsonPath.read(jsonStr, "$.data.cities[*].name");
System.out.println(targetList);
}
}
最后
以上就是文艺奇迹最近收集整理的关于XPath和JsonPath的全部内容,更多相关XPath和JsonPath内容请搜索靠谱客的其他文章。





![[VB.NET]轻松控制Excel](https://www.shuijiaxian.com/files_image/reation/bcimg21.png)


发表评论 取消回复