一.分析需求
1、对于沪深两市的各只股票,获取其:‘股票代码’, ‘股票名称’, ‘最高’, ‘最低’, ‘涨停’, ‘跌停’, ‘换手率’, ‘振幅’, '成交量’等信息;
2、将获取的信息存放在Excel文件中,股票信息属性作为表头,每只股票信息作为表格的一行,每个单元格存放一个信息。
二.运行结果展示
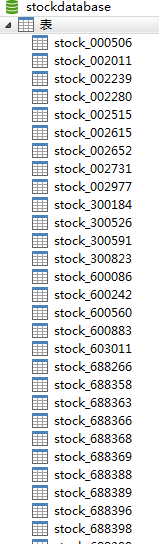
1.存储到数据库
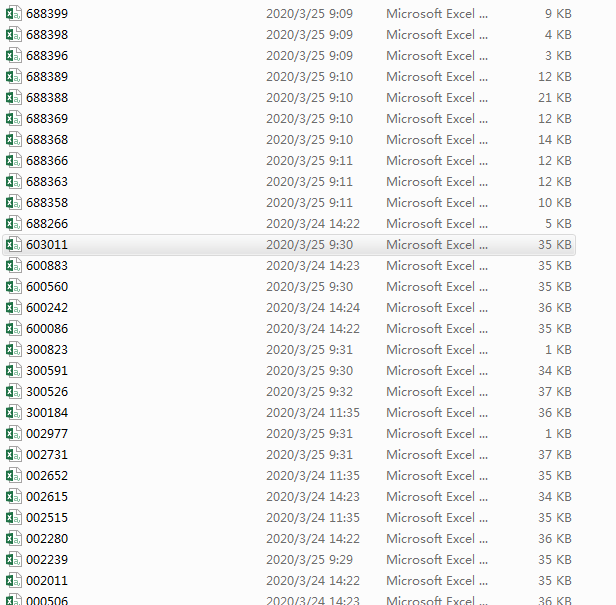
2.存储到Excel表格
三.第三方库
1.urllib.request
2.datetime
3.pandas
4.pymysql
5.os
6.re
四.模块解析
1.当前时间转化为字符串
def date_str():
#获取当时时间年份
year = datetime.now().year
#获取当时时间月份
month = datetime.now().month
#获取当前时间天数
day = datetime.now().day
#如何天数小于10,在十位添加“0”
if month < 10:
month = '0' + str(month)
if day < 10:
day = '0' + str(day)
#时间转化为字符串
localtime = str(year) + str(month) + str(day)
# print(localtime)
return localtime
2.查找股票代码
def data_code(i):
'''
查找股票代码
:param i:
:return:
'''
# date=driver.find_element_by_xpath("html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr[%d]/td[2]/a"%i)
date_code = driver.find_element_by_xpath('//*[@id="table_wrapper-table"]/tbody/tr[%d]/td[2]/a' % i)
return date_code.text
3.查找公司名称
ef data_name(i):
'''
查询公司名字
:param i:
:return:
'''
# //*[@id="table_wrapper-table"]/tbody/tr[1]/td[3]/a
date_name = driver.find_element_by_xpath('//*[@id="table_wrapper-table"]/tbody/tr[%d]/td[3]/a' % i)
return date_name
4.下载所需的上市公司代码
def data_code_false(date_code):
'''
下载所需的公司上市代码
:return:
'''
# http://quotes.money.163.com/trade/lsjysj_688266.html
driver.get("http://quotes.money.163.com/trade/lsjysj_" + date_code + '.html')
date_false_code = driver.find_element_by_xpath('/html/body/div[2]/div[1]/div[3]/table/tbody/tr/td[1]/h1/a')
date_false_code = date_false_code.get_attribute('href')[-12:-5]
# print(date_false_code)
driver.back()
return date_false_code
5.下载股票数据
def TO_Save_CSV(date_str):
'''
下载文件
:return:
'''
for i in range(1, 11):
data_code_false(data_code(i))
# url = 'http://quotes.money.163.com/service/chddata.html?code=0' + data_code(
# i) +"&start=20190102"+ '&end=' + date_str + '&fields=TCLOSE;HIGH;LOW;TOPEN;LCLOSE;CHG;PCHG;TURNOVER;VOTURNOVER;VATURNOVER;TCAP;MCAP'
url = 'http://quotes.money.163.com/service/chddata.html?code=' + data_code_false(data_code(
i)) + "&start=20190102" + '&end=' + date_str + '&fields=TCLOSE;HIGH;LOW;TOPEN;LCLOSE;CHG;PCHG;TURNOVER;VOTURNOVER;VATURNOVER;TCAP;MCAP'
urllib.request.urlretrieve(url, filepath + data_code(i) + '.csv')
time.sleep(5)
6.创建数据库、数据库表并插入数据
def TO_database():
name = 'root' # 数据库账号
password = 'chnsys' # 数据库密码
db = pymysql.connect('localhost', name, password, charset='utf8') # 建立本地数据库连接
cursor = db.cursor()
# 创建数据库
sqlSentencel = "create database if not exists stockDataBase"
# 查询数据库是否存在
select_database_count = "select count(*) from information_schems.schemata where schema_name ='stockDataBase'"
if select_database_count == 0:
cursor.execute(sqlSentencel)
sqlSentence2 = 'use stockDataBase'
cursor.execute(sqlSentence2)
# 获取本地文件列表
filelist = os.listdir(filepath)
# 依次对每个数据文件进行存储
for fileName in filelist:
# print(fileName)
data = pd.read_csv(filepath + fileName, encoding='gbk')
try:
# 创建数据表,如果数据表已经存在,会跳过继续执行下面的步骤print('创建数据表stock_%s'% fileName[0:6])
sqlSentence3 = "create table stock_%s" % fileName[
0:6] + "(日期 date, 股票代码 VARCHAR(10), 名称 VARCHAR(10),收盘价 float, "
"最高价 float, 最低价 float, 开盘价 float, 前收盘 float, 涨跌额 "
"float, 涨跌幅 float, 换手率 float, 成交量 bigint, 成交金额 bigint, 总市值 bigint, 流通市值 bigint)"
cursor.execute(sqlSentence3)
except:
print("数据表已存在")
# 迭代读取表中每行数据,依次存储
# print('正在存储stock_%s'%fileName[0:6])
length = len(data)
# print(length)
for i in range(0, length):
record = tuple(data.loc[i])
# print(record)
# 插入语句
if select_data(fileName[0:6],record[0]):
try:
sqlSentence4 = "insert into stock_%s" % fileName[0:6] + "(日期, 股票代码, 名称, 收盘价, 最高价, 最低价, 开盘价, 前收盘, 涨跌额, 涨跌幅, 换手率,
成交量, 成交金额, 总市值, 流通市值) values ('%s',%s','%s',%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)" % record
# 获取的表中数据很乱,包含缺少值、None、none等,插入数据库数据需要处理成空值
sqlSentence4 = sqlSentence4.replace('nan', 'null').replace("None", 'null').replace('none', 'null')
cursor.execute(sqlSentence4)
print(record[0])
except:
print("插入异常")
continue
cursor.close()
db.commit()
db.close()
7.预防插入日期相同的数据
def select_data(stock_code,date):
try:
db=pymysql.connect('localhost',name,password,db='stockDataBase')
# 字典
curror=db.cursor(pymysql.cursors.DictCursor)
sql='show tables;'
curror.execute(sql)
tables=[curror.fetchall()]
table_list=re.findall("'(.*?')",str(tables))
table_list = [re.sub("'",'',each) for each in table_list]
table_name="stock_"+str(stock_code)
if table_name in table_list:
curror.execute('select 日期 from stock_%s'%stock_code)
result=curror.fetchall()
for row in result:
print()
# print(row['日期']
if date!=row['日期']:
return True
else:
return False
else:
return True
except:
return True
五.完整代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @time :2020/3/20 9:15
# @File : demo0320.py
# @software : PyCharm
# @author :Administrator
# @Emial : mayh@chnsys.com.cn
# @Version :V1.1.0
"""
文件说明:
"""
from selenium import webdriver
import urllib.request
from datetime import datetime
import time
import pandas as pd
import pymysql
import os
import re
filepath = 'F:\data\'
url = 'http://quote.eastmoney.com/stocklist.html'
driver = webdriver.Chrome()
driver.maximize_window()
driver.get(url)
time.sleep(5)
name = 'root' # 数据库账号
password = 'chnsys' # 数据库密码
def date_str():
year = datetime.now().year
month = datetime.now().month
day = datetime.now().day
if month < 10:
month = '0' + str(month)
if day < 10:
day = '0' + str(day)
localtime = str(year) + str(month) + str(day)
# print(localtime)
return localtime
def data_code(i):
'''
查找股票代码
:param i:
:return:
'''
# date=driver.find_element_by_xpath("html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr[%d]/td[2]/a"%i)
date_code = driver.find_element_by_xpath('//*[@id="table_wrapper-table"]/tbody/tr[%d]/td[2]/a' % i)
return date_code.text
def data_name(i):
'''
查询公司名字
:param i:
:return:
'''
# //*[@id="table_wrapper-table"]/tbody/tr[1]/td[3]/a
date_name = driver.find_element_by_xpath('//*[@id="table_wrapper-table"]/tbody/tr[%d]/td[3]/a' % i)
return date_name
def data_code_false(date_code):
'''
下载所需的公司上市代码
:return:
'''
# http://quotes.money.163.com/trade/lsjysj_688266.html
driver.get("http://quotes.money.163.com/trade/lsjysj_" + date_code + '.html')
date_false_code = driver.find_element_by_xpath('/html/body/div[2]/div[1]/div[3]/table/tbody/tr/td[1]/h1/a')
date_false_code = date_false_code.get_attribute('href')[-12:-5]
# print(date_false_code)
driver.back()
return date_false_code
def TO_Save_CSV(date_str):
'''
下载文件
:return:
'''
for i in range(1, 11):
data_code_false(data_code(i))
# url = 'http://quotes.money.163.com/service/chddata.html?code=0' + data_code(
# i) +"&start=20190102"+ '&end=' + date_str + '&fields=TCLOSE;HIGH;LOW;TOPEN;LCLOSE;CHG;PCHG;TURNOVER;VOTURNOVER;VATURNOVER;TCAP;MCAP'
url = 'http://quotes.money.163.com/service/chddata.html?code=' + data_code_false(data_code(
i)) + "&start=20190102" + '&end=' + date_str + '&fields=TCLOSE;HIGH;LOW;TOPEN;LCLOSE;CHG;PCHG;TURNOVER;VOTURNOVER;VATURNOVER;TCAP;MCAP'
urllib.request.urlretrieve(url, filepath + data_code(i) + '.csv')
time.sleep(5)
def TO_database():
name = 'root' # 数据库账号
password = 'chnsys' # 数据库密码
db = pymysql.connect('localhost', name, password, charset='utf8') # 建立本地数据库连接
cursor = db.cursor()
# 创建数据库
sqlSentencel = "create database if not exists stockDataBase"
# 查询数据库是否存在
select_database_count = "select count(*) from information_schems.schemata where schema_name ='stockDataBase'"
if select_database_count == 0:
cursor.execute(sqlSentencel)
sqlSentence2 = 'use stockDataBase'
cursor.execute(sqlSentence2)
# 获取本地文件列表
filelist = os.listdir(filepath)
# 依次对每个数据文件进行存储
for fileName in filelist:
# print(fileName)
data = pd.read_csv(filepath + fileName, encoding='gbk')
try:
# 创建数据表,如果数据表已经存在,会跳过继续执行下面的步骤print('创建数据表stock_%s'% fileName[0:6])
sqlSentence3 = "create table stock_%s" % fileName[
0:6] + "(日期 date, 股票代码 VARCHAR(10), 名称 VARCHAR(10),收盘价 float, "
"最高价 float, 最低价 float, 开盘价 float, 前收盘 float, 涨跌额 "
"float, 涨跌幅 float, 换手率 float, 成交量 bigint, 成交金额 bigint, 总市值 bigint, 流通市值 bigint)"
cursor.execute(sqlSentence3)
except:
print("数据表已存在")
# 迭代读取表中每行数据,依次存储
# print('正在存储stock_%s'%fileName[0:6])
length = len(data)
# print(length)
for i in range(0, length):
record = tuple(data.loc[i])
# print(record)
# 插入语句
if select_data(fileName[0:6],record[0]):
try:
sqlSentence4 = "insert into stock_%s" % fileName[0:6] + "(日期, 股票代码, 名称, 收盘价, 最高价, 最低价, 开盘价, 前收盘, 涨跌额, 涨跌幅, 换手率,
成交量, 成交金额, 总市值, 流通市值) values ('%s',%s','%s',%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)" % record
# 获取的表中数据很乱,包含缺少值、None、none等,插入数据库数据需要处理成空值
sqlSentence4 = sqlSentence4.replace('nan', 'null').replace("None", 'null').replace('none', 'null')
cursor.execute(sqlSentence4)
print(record[0])
except:
print("插入异常")
continue
cursor.close()
db.commit()
db.close()
def select_data(stock_code,date):
try:
db=pymysql.connect('localhost',name,password,db='stockDataBase')
# 字典
curror=db.cursor(pymysql.cursors.DictCursor)
sql='show tables;'
curror.execute(sql)
tables=[curror.fetchall()]
table_list=re.findall("'(.*?')",str(tables))
table_list = [re.sub("'",'',each) for each in table_list]
table_name="stock_"+str(stock_code)
if table_name in table_list:
curror.execute('select 日期 from stock_%s'%stock_code)
result=curror.fetchall()
for row in result:
print()
# print(row['日期']
if date!=row['日期']:
return True
else:
return False
else:
return True
except:
return True
if __name__ == "__main__":
TO_Save_CSV(date_str())
TO_database()
driver.close()
最后
以上就是坚定红牛最近收集整理的关于python爬取所有股票信息并存储的全部内容,更多相关python爬取所有股票信息并存储内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复