小 T 导读:在TDengine还没推出之前,「每人店」一直使用MySQL来存储平台各种硬件采集的数据。为了提高数据展示效果,后台再将采集到的愿数据进行各个维度的计算,这样的计算导致MySQL频繁读写,为了保证各个维度数据的一致性,采用了MySQL事务,性能大受影响,经常会出现事务死锁,后切换至TDengine,各个维度的数据都不需要再计算,直接统计结果,省去了很多步骤。
1 使用场景简介
1.1 业务场景介绍
每人店给客户提供的服务之一就是店铺的智能化管理,通过在各个门店安装我们的各类智能硬件传感设备,统计客流等信息并进行数据展示。一个非常常见的场景是进出店客户数统计,并进行实时状态显示和历史数据分析。智能设备采集会四个指标:采集数据的时间戳、1分钟内进店人数、1分钟内出店人数、滞留人数。通常我们每天的在线设备数在2.3万个左右,每分钟上报一次,每天有3312万条数据,数据都是永久保存,因此数据量积累起来是非常大的。终端设备原始数据字段如下:
| 采集字段 | 数据类型 | 说明 |
| data_time | TIMESTAMP | 数据采集时间 |
| data_in | INT | 进店人数 |
| data_out | INT | 出店人数 |
| data_create | BIGINT | 数据写入系统时间 |
| data_delay | BIGINT | 延时毫秒 |
注:延时毫秒(Kafka收到数据时间戳-设备统计时间戳),主要用来统计设备的网络稳定性和数据完整性
在TDengine还没有推出之前,我们一直使用的是MySQL来存储我们每人店平台的各种硬件采集的数据。数据展示时需要按照时间范围显示客流量,比如查询和显示安踏在深圳市某一个门店过去一个月每小时的客流量情况。为了提高数据展示效果和效率,我们后台将采集到的设备数据进行各个时间维度的计算,比如从MySQL中定时读出数据,按照小时、天、月统计后的结果再不断写入MySQL,这样的做法导致MySQL频繁地读写,同时还要设计复杂的按时间、商家等分库分表的逻辑,维护起来是非常麻烦的。为了保证各个维度数据的一致性,我们还使用到了MySQL事务,性能大受影响,经常会出现事务死锁的发生。
直到TDengine的出现,为之眼前一亮,我们只需要将接收到的每分钟客流采集数据,按照设备分表存储,并且给每个设备对应的表打上商家、门店编号、设备ID的标签即可。各个时间维度的数据都不需要我们再计算后存储一次了,直接通过TDengine的降采样interval语法来统计结果,省去了我们很多的步骤。目前我们已经将之前存入MySQL的设备数据写入TDengine,调整后的系统整体架构如下:
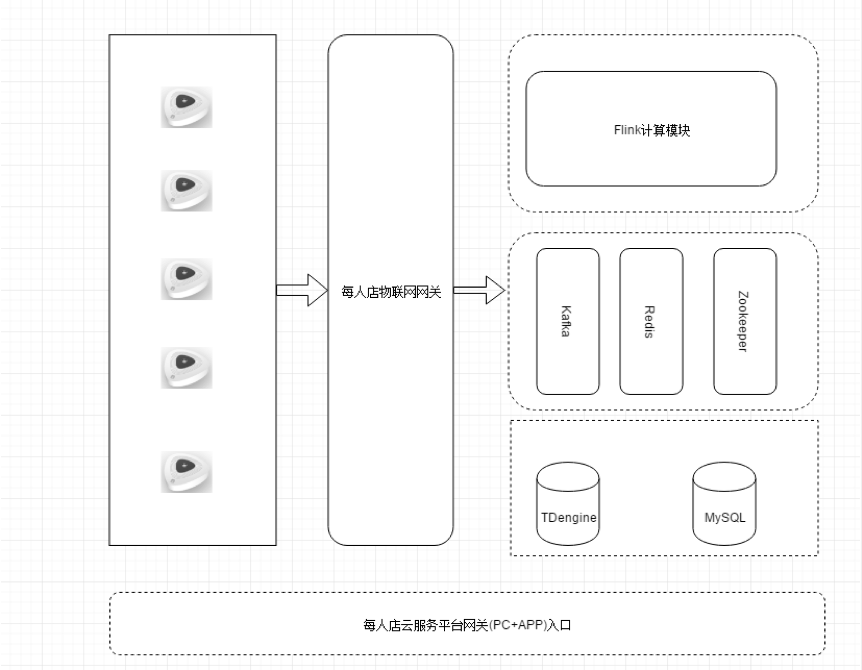
硬件设备采集的数据通过物联网网关传递过来,写入到Kafka(为什么用Kafka而不直接写入到TDengine中,因为原有架构已经上线,所以直接在计算模块上增加TDengine的写入)中,然后通过新增一个Flink计算模组来消费Kafka数据,并调用TDengine的写入接口再将数据写入到时序库。上层再接我们的用户交互APP以及其他数据服务API。
1.2 查询示例
项目正式上线在2020的1月初,线上时已经导入TDengine的数据存储规模大概在200G左右,每天的数据增量在16G左右。
应用系统的常规查询在24QPS左右,基本都是按照时间范围来查询。业务场景的需求不会要求用户时时刻刻对数据进行查询,大部分用户还是通过我们提供的API获取数据,然后结合自身的内部系统进行数据分析。整体查询的速度响应都在几十毫秒级别。
前面介绍过,我们最典型的一个查询场景是根据对某商户的某个门店进行一段时间内的客流统计。在MySQL中需要对每个设备提前做好计算并存入结果表,在TDengine中,数据存入后就可以直接查询,而且响应非常快。我们在TDengine中建立一个门进设备数据的超级表traffic_data,表结构如下:
Field | Type | Length | Note |==============================================================================data_time |TIMESTAMP | 8| |data_in |INT | 4| |data_out |INT | 4| |data_delay |BIGINT | 8| |merchant_id |BIGINT | 8|tag |instance_id |BIGINT | 8|tag |passageway_id |BIGINT | 8|tag |
其中data_time, data_in, data_out, data_delay我们在前面表格中有说明,这里重点说一下三个tag(TDengine超级表标签)。TDengine的设计思路是每个设备一张表,表中存储设备采集过来的数据,表上可以打标签,用来对设备进行描述。所有同类型设备的表会有相同的表结构,可以放到一张超级表下面,但这些子表会有不同的标签值。
对于我们的场景而言,我们对每个门店统计设备建立一张表,并打上三个标签商家信息merchant_id,门店信息instance_id,出入口信息passageway_id。在查询时,我们往往需要统计一段时间内的客流状况,比如查看过去一段时间内,某个门店按小时统计的进出客流量。
我们在没有使用TDengine前,数据的查询都依赖后台的Flink计算程序,需要后台的计算完成后才能展示给用户,这样会带来一定的延时性,毕竟多了一层应用就多了一层出错的可能。因此我们平台在设计之初就确定了几种固定的维度(5分钟,半小时,小时,天)来存储,这样的设计虽然能满足用户的需求,但是这样的设计让用户只能通过我们的确定的维度来查询,假设某个用户突然说需要一个我们平台没有设计的维度时就无法满足了,要满足就需要计算程序和存储模块一起修改,大大的增加了研发的工作量。而TDengine作为时序数据库的降采样功能interval的使用让我们就不需要担心这样的需求了。
下面简单的介绍下使用TDengine查询数据,就不去区分什么简单查询和聚合查询了,对于TDengine的使用也只能算是初入门不敢过多描述,以免贻笑大方。我们的数据主要是根据门店来划分的,即通过设备与门店的绑定来确定门店的数据,所以我们TDengine存储时超级表设计的标签也是:商户->门店->出入口。
这类查询在TDengine中可以用一条SQL语句搞定:
select sum(data_in) as data_in, sum(data_out) as data_out from traffic_data where ("$condition") and data_time >= "$start" and data_time <= "$end" interval($interval) group by instance_id order by data_time desc;
这个查询是对从$start时刻到$end时刻中,各个门店的每个$interval的时间窗口内的进店人数、出店人数。其中where语句中的$condition还可对商家(merchant_id)或者指定的几个店铺(instance_id)进行过滤筛选,实现的Java代码如下。
Connection connection = null;Statement ps = null;ResultSet resultSet = null;try {TDengineSettingDto setting = feignCoreService.getTDenginSetting(TDengineConf._TDENGINE_TYPE_DATA_TRAFFIC);if (setting != null) {DruidDataSource dataSource = TDengineDataSource.getDataTrafficDataSource(setting.getHost(), setting.getPort(), setting.getDatabase(), setting.getUsername(), setting.getPassword());connection = dataSource.getConnection();if (connection != null) {String condition = "";for (int i = 0; i < instanceIds.size(); i++) {long instanceId = instanceIds.get(i);if (i < (instanceIds.size() - 1)) {condition += " instance_id = " + instanceId + " or ";} else {condition += " instance_id = " + instanceId + " ";}}String interval = DataDimEnum.getInterval(dim);String sql = "select sum(data_in) as data_in, sum(data_out) as data_out from traffic_data where ("+condition+") and data_time >= "+start+" and data_time <= "+end+" interval("+interval+") group by instance_id order by data_time desc";logger.info("查询listWhereInstanceAndTimeGroupByInstanceAndTime客流SQL: " + sql);ps = connection.createStatement();resultSet = ps.executeQuery(sql);if (resultSet != null) {List<TrafficInstanceDto> list = new ArrayList<TrafficInstanceDto>();while (resultSet.next()) {TrafficInstanceDto vo = new TrafficInstanceDto();vo.setDataTime(resultSet.getLong("ts"));vo.setInstanceId(resultSet.getLong("instance_id"));int dataIn = resultSet.getInt("data_in");if(dataIn<0){dataIn = 0;}int dataOut = resultSet.getInt("data_out");if(dataOut<0){dataOut = 0;}vo.setTrafficIn(dataIn);vo.setTrafficOut(dataOut);list.add(vo);}return list;}}}} catch (SQLException e) {logger.error("查询TDengine门店客流数据失败: {}, {}, {}, {}", instanceIds, start, end, dim, e);} finally {try {if (resultSet != null) {resultSet.close();}} catch (SQLException e) {logger.error("关闭TDengine连接池ResultSet失败", e);}try {if (ps != null) {ps.close();}} catch (SQLException e) {logger.error("关闭TDengine连接池PreparedStatement失败", e);}try {if (connection != null) {connection.close();}} catch (SQLException e) {logger.error("关闭TDengine连接池Connection失败", e);}}
简简单单几行代码即可实现各种维度的数据查询,是不是相当简单,根本不需要修改任何架构。
但我们使用时也发现一个问题,使用TDengine做月数据查询时interval(1n)数据会不对,因为TDengine的月并非自然月,默认就是30天,而31天的月份数据会不全,所以我们对月份的查询单独做了处理,即先取到月份的开始日期和结束日期,然后再进行时间段sum,最后用程序来实现统计结果的展示,整体影响不大。
1.3 资源开销对比
整个系统自上线来,并发量不算很大,但是对查询的性能确实有显著的提升,用两张图来对比下一目了然。
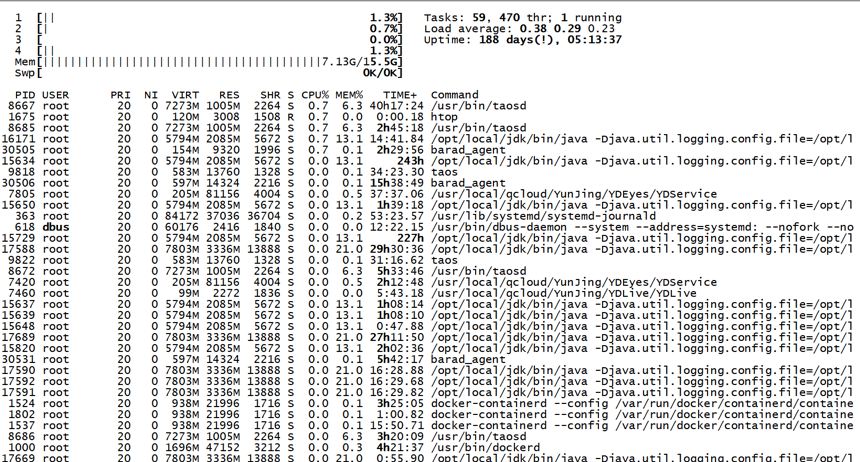
这个是使用TDengine后服务器的资源使用情况,服务器上还允许了好几个Java应用程序,一点压力没有,内存,CPU等都没有压力。
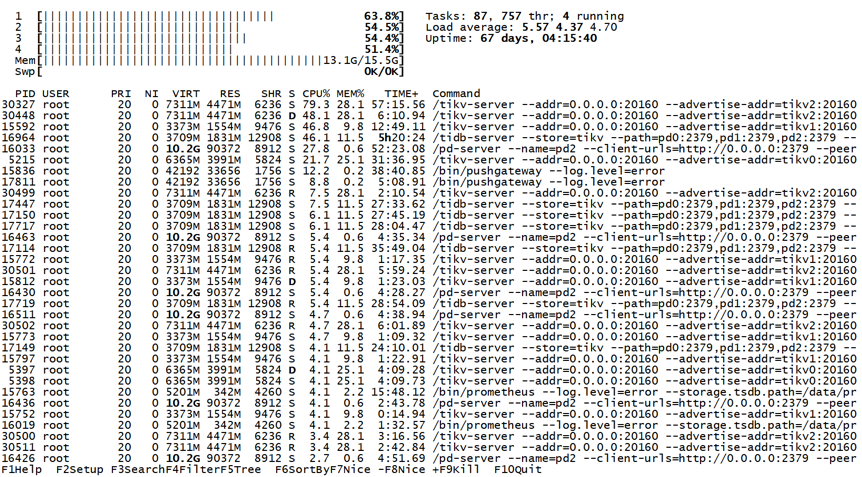
这个是之前相同数据负载情况下,但没有使用TD的时候服务器的压力:CPU,内存,LoadAverage等都一直居高不下,资源开销的节省一目了然。
2 采用TDengine带来的收益
使用TDengine后,确实在数据查询和性能上给我带了不少的惊喜。因为刚开始一直抱着先试用下的心态,所以并没有对整个平台的架构进行大的调整,直接在计算程序上加一个模块就完成了,这样的修改也简单,真正上线后发现确实强悍啊,1月份上线到现在也一直没管,也没有任何故障,之前使用MySQL时,经常数据库故障,处理起来非常的痛苦。
3 对社区的一些感想
一开始使用TDengine时,确实遇到不少的问题。最开始是在GitHub上看别人提的issue有没有,后来官方弄了个微信群,遇到问题可以直接在微信群里沟通,效率高了不少。在此特别感谢TDengine团队的廖博士耐心指导和关怀,期间几次遇到TDengine内存泄漏的问题,都是他远程解决的。目前线上运行的1.6.3.0还是根据他提供的文件编译的。
后面也会考虑将 TDengine 扩展到更多业务和场景中,比如看看如何应用TDengine到人脸识别这块业务中来。这块目前TDengine倒是满足,但是如果使用起来这个就庞大了,人脸识别将一个人视为一个终端设备,但是目前的开源版应该支撑不了那么大的量。
4 TDengine功能方面的期望与建议
通过这段时间的使用,对TD还是期望能开放集群版本的开源,毕竟这样性能等各方面都能更出色的体现出来。目前所在的行业是零售行业,只针对零售行业的使用存在的一些问题来说下:
1. 时间连贯性,零售行业的数据其实不是连贯的(有营业时间的划分),所以我们使用时其实是将设备的数据分开存储的,将设备所有的元数据存储到一个表中,然后将营业时间内的数据进行再存储到一个虚拟的设备中。但是营业时间外的数据又不可能丢弃。所以设备是会翻倍的。如果沿用TDengine的设计(一个设备一张表),这样统计数据时有时会不准。
2. 人脸识别应用,之前试过将人脸识别的记录存放到TD中,因为用的是开源版,发现一个人脸用户一张表,这个表的数量太庞大了,所以终止了人脸业务使用TDengine。
3. 热区采集,一个设备采集的坐标数据太大,一次采集就有8万个坐标点没有合适的数组字段类型可以存储,希望后面可以支持。
总体上讲,引入TDengine给我们的系统带来了不少优化的地方,后期我们还会针对性的删减掉一些不再必要的模块,进一步瘦身;也希望TDengine社区能持续繁荣,有不断的优化功能出来。
作者介绍:卢崇志,每人店研发经理,2014年加入深圳市晓舟科技有限公司研发部,工作至今,目前负责公司每人店产品的整体研发工作,包括WEB端与移动端的研发工作管理以及后端Java研发和架构设计。
公司介绍:深圳市晓舟科技有限公司是一家致力于为千万门店提供触手可及的平等IT及大数据服务的高新科技企业,公司以专注、极致、口碑、快为运营准则,旨在让开店者可以轻松的通过web、app等方式轻松找到新零售升级路径。这些路径并非简单的产品组合,而是通过各种有效创新软硬件,从而完成商品的生产、流通与销售过程的全系统改造,并通过运用大数据、人工智能等先进技术手段,重塑业态结构与生态圈,从而让顾客享受更佳的购物体验。产品正式销售两年多,公司系列产品已在全国上千个知名连锁品牌五万多家门店实现覆盖,这些知名品牌包含安踏、卡门、森马、依妙、天虹、重庆百货等。
最后
以上就是安详烧鹅最近收集整理的关于MySQL宕机?大数据驱动下的新零售,如何寻求存储计算的最优解?的全部内容,更多相关MySQL宕机?大数据驱动下内容请搜索靠谱客的其他文章。








发表评论 取消回复