Redis基本数据类型
String字符串类型
Redis中的字符串是可以修改的字符串,在内存中它是以字节数组(byte[])的形式存在。
用途:JPEG图像或序列化的对象信息。
在C语言中字符串是以NULL作为结束符,但是在Redis里面字符串不是这么表示。因为在获取NULL结尾的字符串的长度使用的是C语言的strlen标准库函数,这个函数算法复杂度是O(n),它需要对字节数组进行遍历扫描,作为单线程的Redis承受不了。
Redis的字符串是SDS(simple dynamic String)。
它的结构是带长度信息的字节数组。
struct SDS<T> {
T capacity; // 数组容量
T len; // 数组长度
byte flags; // 特殊标识位,不理睬它 byte[] content; // 数组内容
}
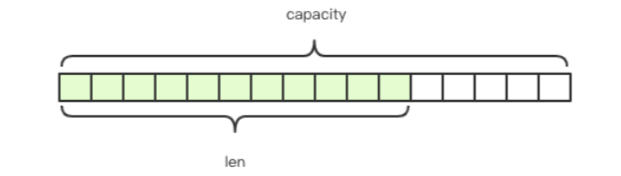
如代码所示,content里存储了真正的字符串内容,capacity则表示所分配数组的长度,len表示字符串的实际长度。由于redis的字符串是可以修改,要支持append操作。如果数组没有冗余的空间时,追加操作必然涉及到分配新数组,然后将酒内容复制过来,再append新内容。如果字符串的长度非常长,这样的内存分配和复制开销机会非常大。
SDS结构使用了范型T,使用范型是因为当字符串比较小的时候,len和capacity可以使用byte和short表示,根据字符串的长度使用不同的数据类型表示,这样对内存起到优化的作用。
Redis规范字符串的长度不得超过512M字节。创建字符串时len和capacity一样长,不会多余分配冗余空间。
embstr 与 raw
Redis的字符串两种存储方式,在长度特别短时,使用emb形式存储,当长度超过44时,使用raw形式存储。
当使用debug object 时,输出的encoding字段,将可以查询存储形式。
所有的Redis对象都有结构头,如下:
struct RedisObject {
int4 type; // 4bits 存储类型
int4 encoding; // 4bits 存储形式
int24 lru; // 24bits
int32 refcount; // 4bytes 引用计数器
void *ptr; // 8bytes,64-bit system ptr指针
} robj;
不同的对象具有不同的类型,同一个类型会有不同的存储形式,为了记录对象的lru信息,每个对象都会有个引用计数,引用计数器为空时,对象会被销毁,内存被回收。ptr指针将指向对象内容的具体存储位置。
SDS结构体:
在字符串比较小时,SDS对象头大小时capacity+3,至少是3.意味着分配一个字符串的最小空间是占有19个字节(16+3)
struct SDS {
int8 capacity; // 1byte
int8 len; // 1byte
int8 flags; // 1byte
byte[] content; // 内联数组,长度为 capacity
}
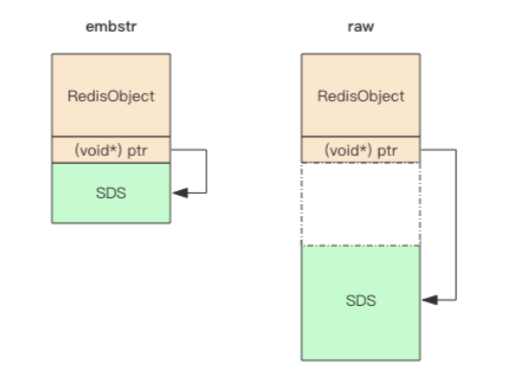
如图所示,embstr存储形式是将redisObject对象头和SDS对象连续存储在一起,使用malloc方法(动态分配内存空间函数)一次分配;而raw存储形式,它需要两次,两个对象头在内存地址上一般不连续。
而内存分配器jemalloc/tcmalloc等分配内存大小的单位都是2,4,8,16,32,64等等,为了容纳完整的embstr对象时,jemalloc最少会分配32个字节空间。如果总体超出了64个字节,redis认为是一个大字符串,不再使用embstr形式存储,而使用raw。
根据上面所述,留给content的长度最多只有45(64-19)字节。字符串又是以�结尾,所以embstr最大能容纳字符串长度是44。
扩容策略
字符串在长度小于1M之前,扩容空间采用加倍策略,也是保留100%的冗余空间。当长度超过1M之后,为了避免加倍后的冗余空间过大而导致浪费,每次扩容只会多分配1M大小的冗余空间。
list(列表)
list列表内部实现是链表不是数组,因此插入操作非常快,时间复杂度为O(1),但是索引定位很慢,时间复杂度O(n)。
list列表类型可以存储有序,可重复的元素。
list元素个数最多为2^32-1个(40亿)
应用场景:
1,作为栈或队列使用
2,可用于各种列表,如热点商品列表,评论列表等。
hash(散列表)
Redis hash 是一个String类型的field和value的映射,它提供了字段和字段值的映射。
与字符串不同,字符串需要一次性全部序列化整个对象,
hash可以对用户结构中的每个字段单独存储。这样当我们需要获取用户信息时,可以进行部分获取。
每个 hash 可以存储 2^32 - 1 键值对(40多亿)。
hash缺点:hash结构的存储消耗高于单个字符串。
应用场景:
对象的存储 ,表数据的映射
set(集合)
它内部的键值对是无序的唯一的。它的内部实现相当于一个特殊的字典,字典内部的所有value都是一个值null。有去重功能,所以是唯一元素,集合中最大成员数为2^32-1。
应用场景:
适用于不能重复的且不需要顺序的数据结构
比如:关注的用户,还可以通过spop进行随机抽奖
sorted set(zset有序集合)
SortedSet(ZSet) 有序集合: 元素本身是无序不重复的 。每个元素关联一个分数(score) 可按分数排序,分数可重复。score 是Double.MIN_VALUE,用来垫底的。
内部实现是一种跳跃列表的数据结构。
bitmap(位图类型)
位图不是特殊的数据结构,也是普通的字符串,也是byte数组。可以使用普通的get/set直接获取和设置位图的内容。也可以使用位图操作getbit/setbit将byte数组看成数组来处理。
用于解决存储空间。
使用场景:存储用户一年的签到记录,如果使用普通的key/value,每个用户就需要365个,当用户量上亿的时候,需要的存储空间就是惊人。使用位图数据结构时,每天记录只占一个位,365天只用365个位,46个字节就可以完全容纳。
geo地理位置类型
业界比较通用的地理位置排序算法,将二维的经纬度数据映射到一维的整数,这样所有的元素都在挂在到一条线上,距离靠近的二维坐标映射到一维后的点之间也会很接近。使用二刀法来做映射算法。
redis3.2版本增加的地理位置GEO模块;
实现了附近的Mobile和附近餐馆功能。
stream数据流类型
Redis5.0添加的一种数据结构,它是一个新的强大的支持多播的可持久化的消息列表。
几乎满足了消息队列具备的全部内容,包括:
消息ID的序列化生成
消息遍历
消息的阻塞和非阻塞读取
消息的分组消费
未完成消息的处理
消息队列监控
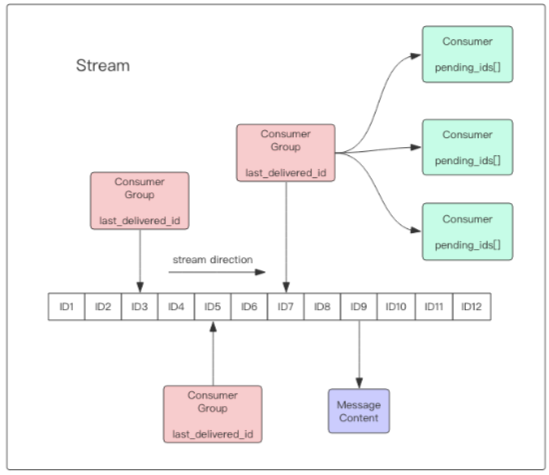
Redis Stream 的结构如上图所示,它有一个消息链表,将所有加入的消息都串起来,每 个消息都有一个唯一的 ID 和对应的内容。消息是持久化的,Redis 重启后,内容还在。
每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消 息时自动创建。
每个 Stream 都可以挂多个消费组,每个消费组会有个游标 last_delivered_id 在 Stream 数组之上往前移动,表示当前消费组已经消费到哪条消息了。
每个消费组都有一个 Stream 内唯一的名称,消费组不会自动创建,它需要单独的指令 xgroup create 进行创建,需要指定 从 Stream 的某个消息 ID 开始消费,这个 ID 用来初始化 last_delivered_id 变量。
每个消费组 (Consumer Group) 的状态都是独立的,相互不受影响。也就是说同一份 Stream 内部的消息会被每个消费组都消费到。
同一个消费组 (Consumer Group) 可以挂接多个消费者 (Consumer),这些消费者之间是 竞争关系,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。每个消费者有 一个组内唯一名称。
消费者 (Consumer) 内部会有个状态变量 pending_ids,它记录了当前已经被客户端读取 的消息,但是还没有 ack。如果客户端没有 ack,这个变量里面的消息 ID 会越来越多,一 旦某个消息被 ack,它就开始减少。这个 pending_ids 变量在 Redis 官方被称之为 PEL,也 就是 Pending Entries List,这是一个很核心的数据结构,它用来确保客户端至少消费了消息一 次,而不会在网络传输的中途丢失了没处理。
最后
以上就是拼搏汽车最近收集整理的关于Redis数据类型的全部内容,更多相关Redis数据类型内容请搜索靠谱客的其他文章。








发表评论 取消回复