三角测量是为了解决单目图像无法获取深度的问题,本博客是代码解释所以不解释三角测量的原理。先上全部代码:
#include <iostream>
int main ( int argc, char** argv )
{
if ( argc != 3 )
{
cout<<"usage: triangulation img1 img2"<<endl;
return 1;
}
//-- 读取图像
Mat img_1 = imread ( argv[1], CV_LOAD_IMAGE_COLOR );
Mat img_2 = imread ( argv[2], CV_LOAD_IMAGE_COLOR );
vector<KeyPoint> keypoints_1, keypoints_2;
vector<DMatch> matches;
find_feature_matches ( img_1, img_2, keypoints_1, keypoints_2, matches );//这部分完成特征点的提取与匹配
cout<<"一共找到了"<<matches.size() <<"组匹配点"<<endl;
//-- 估计两张图像间运动,2d-2d函数可以求解R与t
Mat R,t;
pose_estimation_2d2d ( keypoints_1, keypoints_2, matches, R, t );
//-- 三角化
vector<Point3d> points;//将三角测量之后的3d坐标存储在points中
triangulation( keypoints_1, keypoints_2, matches, R, t, points );//完成特征点之间的三角测量获取深度
//-- 验证三角化点与特征点的重投影关系
Mat K = ( Mat_<double> ( 3,3 ) << 520.9, 0, 325.1, 0, 521.0, 249.7, 0, 0, 1 );//内参K
for ( int i=0; i<matches.size(); i++ )
{
Point2d pt1_cam = pixel2cam( keypoints_1[ matches[i].queryIdx ].pt, K );
Point2d pt1_cam_3d(
points[i].x/points[i].z, //三角化得到的3d坐标除以其深度信息来计算其归一化坐标
points[i].y/points[i].z
);
cout<<"point in the first camera frame: "<<pt1_cam<<endl;
cout<<"point projected from 3D "<<pt1_cam_3d<<", d="<<points[i].z<<endl;
// 第二个图
Point2f pt2_cam = pixel2cam( keypoints_2[ matches[i].trainIdx ].pt, K );
Mat pt2_trans = R*( Mat_<double>(3,1) << points[i].x, points[i].y, points[i].z ) + t;
pt2_trans /= pt2_trans.at<double>(2,0);
cout<<"point in the second camera frame: "<<pt2_cam<<endl;
cout<<"point reprojected from second frame: "<<pt2_trans.t()<<endl;
cout<<endl;
}
return 0;
}
void triangulation(
const vector<KeyPoint>& keypoint_1,
const vector<KeyPoint>& keypoint_2,
const std::vector< DMatch >& matches,
const Mat& R, const Mat& t,
vector<Point3d>& points
);
void triangulation(
const vector<KeyPoint>& keypoint_1,
const vector<KeyPoint>& keypoint_2,
const std::vector< DMatch >& matches,
const Mat& R, const Mat& t,
vector<Point3d>& points)
{
Mat T1 = (Mat_<double> (3,4) << //T1是初始矩阵,就是R+t(这里我认为是参考位姿矩阵)
1,0,0,0,
0,1,0,0,
0,0,1,0);
Mat T2 = (Mat_<double> (3,4) << //T2是对极约束求出的R和t的外参参数矩阵
R.at<double>(0,0), R.at<double>(0,1), R.at<double>(0,2), t.at<double>(0,0),//获取R矩阵(0,0)位置的数据,(0,1)位置的数据以及(0,2)
R.at<double>(1,0), R.at<double>(1,1), R.at<double>(1,2), t.at<double>(1,0),
R.at<double>(2,0), R.at<double>(2,1), R.at<double>(2,2), t.at<double>(2,0)//Mat.at实现对图像矩阵中某个值的获取和改变。
);
Mat K = ( Mat_<double> ( 3,3 ) << 520.9, 0, 325.1, 0, 521.0, 249.7, 0, 0, 1 );//相机内参矩阵K
vector<Point2d> pts_1, pts_2;
for ( DMatch m:matches )//遍历DMatch中匹配的特征点
{
//将像素坐标转换至归一化成像平面
pts_1.push_back ( pixel2cam( keypoint_1[m.queryIdx].pt, K) );//pixel2cam(这不是opencv提供的),用来将像素坐标通过相机内参转化为归一化成像平面坐标
pts_2.push_back ( pixel2cam( keypoint_2[m.trainIdx].pt, K) );//train图像的特征点进行坐标转化
}
Mat pts_4d;
cv::triangulatePoints( T1, T2, pts_1, pts_2, pts_4d );
//函数接受的参数是两个相机位姿和特征点在两个相机坐标系下的坐标,输出三角化后的特征点的3D坐标。
//输出的3D坐标是齐次坐标,共四个维度(所以变量名为pts_4d),因此需要将前三个维度除以第四个维度以得到非齐次坐标xyz
// 转换成非齐次坐标
for ( int i=0; i<pts_4d.cols; i++ )
{
Mat x = pts_4d.col(i);
x /= x.at<float>(3,0); // 归一化
Point3d p(
x.at<float>(0,0),
x.at<float>(1,0),
x.at<float>(2,0)
);
points.push_back( p );
}
}
三角测量的内容如下:
三角测量的步骤是根据对极约束求到的R与t,使用OpenCV提供的triangulatePoints得出3D坐标。这样子我们就获取到了深度。
void triangulation(
const vector<KeyPoint>& keypoint_1,
const vector<KeyPoint>& keypoint_2,
const std::vector< DMatch >& matches,
const Mat& R, const Mat& t,
vector<Point3d>& points)
{
Mat T1 = (Mat_<double> (3,4) << //T1是初始矩阵,就是R+t(这里我认为是参考位姿矩阵)
1,0,0,0,
0,1,0,0,
0,0,1,0);
Mat T2 = (Mat_<double> (3,4) << //T2是对极约束求出的R和t的外参参数矩阵
R.at<double>(0,0), R.at<double>(0,1), R.at<double>(0,2), t.at<double>(0,0),//获取R矩阵(0,0)位置的数据,(0,1)位置的数据以及(0,2)
R.at<double>(1,0), R.at<double>(1,1), R.at<double>(1,2), t.at<double>(1,0),
R.at<double>(2,0), R.at<double>(2,1), R.at<double>(2,2), t.at<double>(2,0)//Mat.at实现对图像矩阵中某个值的获取和改变。
);
Mat K = ( Mat_<double> ( 3,3 ) << 520.9, 0, 325.1, 0, 521.0, 249.7, 0, 0, 1 );//相机内参矩阵K
vector<Point2d> pts_1, pts_2;
for ( DMatch m:matches )//遍历DMatch中匹配的特征点
{
//将像素坐标转换至归一化成像平面
pts_1.push_back ( pixel2cam( keypoint_1[m.queryIdx].pt, K) );//pixel2cam(这不是opencv提供的),用来将像素坐标通过相机内参转化为归一化成像平面坐标
pts_2.push_back ( pixel2cam( keypoint_2[m.trainIdx].pt, K) );//train图像的特征点进行坐标转化
}
Mat pts_4d;
cv::triangulatePoints( T1, T2, pts_1, pts_2, pts_4d );
//函数接受的参数是两个相机位姿和特征点在两个相机坐标系下的坐标,输出三角化后的特征点的3D坐标。
//输出的3D坐标是齐次坐标,共四个维度(所以变量名为pts_4d),因此需要将前三个维度除以第四个维度以得到非齐次坐标xyz
// 转换成非齐次坐标
for ( int i=0; i<pts_4d.cols; i++ )
{
Mat x = pts_4d.col(i);
x /= x.at<float>(3,0); // 归一化
Point3d p(
x.at<float>(0,0),
x.at<float>(1,0),
x.at<float>(2,0)
);
points.push_back( p );
}
}
cv::triangulatePoints( T1, T2, pts_1, pts_2, pts_4d );
这行代码就是灵魂所在,可以看到此代码之前的所有都是为了这个三角测量函数而做准备工作。
openCV是这样定义该代码的:
void cv::trangulatePoints( InputArray projMatr1,
InputArray projMatr2,
InputArray projPoints1,
InputArray projPoints2,
OutputArray points4D
)
points4D=cv.triangulatePoints(projMatr1, projMatr2, projPoints1, projPoints2[, points4D])
参数解释:
projMatr1:3x4 projection matrix of the first camera.(相机的投影矩阵,3*4,就是把相机外参去掉最后一行就OK了)上面例子的T1对应projMatr1
projMatr2:3x4 projection matrix of the second camera(第二个相机的34投影矩阵)对应代码中的T2,T2便是把对极约束得到的R与t组合成了34的增广矩阵。
projPoints1:2xN array of feature points in the first image. In case of c++ version it can be also a vector of feature points or two-channel matrix of size 1xN or Nx1.(第一张图像中的2xN个特征点阵列。对于c++版本,它也可以是特征点的向量或大小为1xN或Nx1的双通道矩阵。)对应于代码中的pts_1。
pts_1是归一化后的相机坐标集合矩阵。
projPoints2 同理
为了使该函数返回正常数值,所有的输入数据类型应该是float类型,且输出数据的类型也应该被当做float来使用,如果使用了double类型,会有bug.
这里面还涉及到一个函数pixel2cam(意思是pixel to camera)该函数的功能是完成两幅图像中匹配特征点的像素坐标到相机坐标的转换。最终的结果是得到一个2d的相机坐标(x,y),该坐标存储在pts_1与pts_2中。
pts_1.push_back ( pixel2cam( keypoint_1[m.queryIdx].pt, K) );//pixel2cam(这不是opencv提供的),用来将像素坐标通过相机内参转化为归一化成像平面坐标
pts_2.push_back ( pixel2cam( keypoint_2[m.trainIdx].pt, K) );//train图像的特征点进行坐标转化
该函数的原函数如下:
Point2d pixel2cam ( const Point2d& p, const Mat& K )
{
return Point2d
(
( p.x - K.at<double> ( 0,2 ) ) / K.at<double> ( 0,0 ),
( p.y - K.at<double> ( 1,2 ) ) / K.at<double> ( 1,1 )
);
}
调用这个函数会返回一个cv::Point2d类的变量,而Point2d类的变量会存储一个2d点的xy坐标(这里是不是就跟projpoints对应起来了),即有两个成员变量.x和.y,类型为double。在此函数中,直接return了一个通过Point2d构造的变量。
p是像素平面的坐标(x,y), 像素平面坐标: u=p.x; v=p.y
根据像素平面到归一化相机平面的推导:x=(u-u0)*z/fx; y=(v-v0)*z/fy
归一化:x/z=(u-uo)/fx y/z=(v-v0)/fy
u=p.x; v=p.y
u0=K(0,2) v0=K(1,2)
fx=K(0,0) fy=K(1,1)
u0、v0、fx、fy都是根据相机的内参矩阵得到的。
如果要弄明白这里的原理,就得明白相机模型之间各个坐标的转换。
当然在这里只涉及到像素坐标系到相机平面坐标系的内参之间的转换。
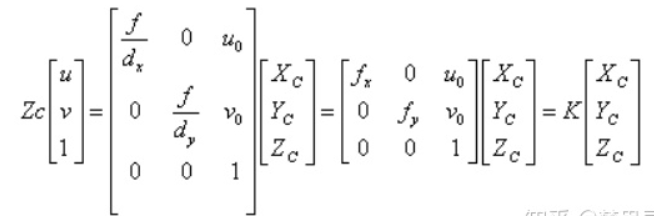
自己推一推就能得出上面函数中的公式了。
最后
以上就是端庄母鸡最近收集整理的关于《SLAM十四讲》7.6 三角测量 triangulation.cpp的全部内容,更多相关《SLAM十四讲》7.6内容请搜索靠谱客的其他文章。








发表评论 取消回复