ClickHouse基础
- 一、clickhouse-简介
- 1、ClickHouse优点
- 2、ClickHouse缺点
- 3、应用场景
- 4 核心概念
- (1) 数据分片
- (2)列式存储
- (3) 向量化
- (4) 表
- (5) 分区
- (6) 副本
- (7) 引擎 必须指定引擎
- 二、ClickHouse部署
- 1、单节点部署
- 2、CK目录介绍
- (1)/etc/clickhouse-server
- (2)/var/lib/clickhouse
- (3)/var/log/clickhouse-server
- (4)/usr/bin 默认添加进系统环境变量中
- 3、CK服务启动
- (1)修改数据、日志文件目录(也可不修改)
- (2)启动服务
- (3)连接客户端
- (4)使用 idea 远程连接
- 三、clickhouse基础入门
- 1、基本语法展示
- 2、数据类型
- (一)数值类型
- (1)IntX和UIntX
- (2)FloatX
- (3)Decimal
- (二)字符串类型
- (1)String
- (2)FixedString
- (3)UUID
- (三)时间类型
- (1) Date
- (2) DateTime
- (3)DateTime64
- (4)三种日期类型都支持插入时间戳
- (四)复杂类型
- (1)Enum 枚举
- (2)Array(T) 数组
- (3)Tuple 元组
- (4)Nested 嵌套
- (5)Map 键值对
- (6)GEO
- (7)IPV4 域名
- (8)Boolean和Nullable
- (9)强制类型转换
一、clickhouse-简介
ClickHouse是俄罗斯的Yandex于2016年开源的一个用于联机分析(OLAP:Online Analytical Processing)的列式数据库管理系统(DBMS:Database Management System) , 主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告。 ClickHouse的全称是Click Stream,Data WareHouse,简称ClickHouse

ClickHouse是一个完全的列式分布式数据库管理系统(DBMS),允许在运行时创建表和数据库,加载数据和运行查询,而无需重新配置和重新启动服务器,支持线性扩展,简单方便,高可靠性,容错。它在大数据领域没有走 Hadoop 生态,而是采用 Local attached storage (本地连接存储)作为存储,这样整个 IO 可能就没有 Hadoop 那一套的局限。它的系统在生产环境中可以应用到比较大的规模,因为它的线性扩展能力和可靠性保障能够原生支持 shard + replication 这种解决方案。它还提供了一些 SQL 直接接口,有比较丰富的原生 client。
补充OLAP概念
OLAP基础概念篇 https://blog.csdn.net/qq_37933018/article/details/111535904
OLAP开源组件篇 https://blog.csdn.net/qq_37933018/article/details/111537128
1、ClickHouse优点
-
灵活的MPP(大规模并行处理)架构 ,支持线性扩展,简单方便,高可靠性
-
多服务器分布式处理数据 ,完备的DBMS(数据库管理)系统
-
底层数据列式存储,支持压缩,优化数据存储,优化索引数据,优化底层存储
-
容错跑分快:比Vertica快5倍,比Hive快279倍,比MySQL快800倍,其可处理的数据级别已达到10亿级别
-
功能多:支持数据统计分析各种场景,支持类SQL查询,异地复制部署
-
海量数据存储,分布式运算,快速闪电的性能,几乎实时的数据分析 ,友好的SQL语法,出色的函数支持
2、ClickHouse缺点
- 不支持事务,不支持真正的删除/更新 (批量)
- 不支持高并发,官方建议qps为100(qps:每秒请求数,就是说服务器在一秒的时间内处理了多少个请求),可以通过修改配置文件增加连接数,但是在服务器足够好的情况下
- 不支持二级索引
- 不擅长多表join(一般都设计为大宽表)
- 元数据管理需要人为干预
- 尽量做1000条以上批量的写入,避免逐行insert或小批量的insert,update,delete操作
3、应用场景
- 绝大多数请求都是用于读访问的, 要求实时返回结果
- 数据需要以大批次(大于1000行)进行更新,而不是单行更新;或者根本没有更新操作
- 数据只是添加到数据库,没有必要修改
- 读取数据时,会从数据库中提取出大量的行,但只用到一小部分列
- 表很“宽”,即表中包含大量的列
- 查询频率相对较低(通常每台服务器每秒查询数百次或更少)
- 对于简单查询,允许大约50毫秒的延迟
- 列的值是比较小的数值和短字符串(例如,每个URL只有60个字节)
- 在处理单个查询时需要高吞吐量(每台服务器每秒高达数十亿行)
- 不需要事务
- 数据一致性要求较低 [原子性 持久性 一致性 隔离性]
- 每次查询中只会查询一个大表。除了一个大表,其余都是小表
- 查询结果显著小于数据源。即数据有过滤或聚合。返回结果不超过单个服务器内存大小
4 核心概念
(1) 数据分片
数据分片是将数据进行横向切分,这是一种在面对海量数据的场 景下,解决存储和查询瓶颈的有效手段,是一种分治思想的体现。 ClickHouse支持分片,而分片则依赖集群。每个集群由1到多个分片组成,而每个分片则对应了ClickHouse的1个服务节点。分片的数量上限取决于节点数量(1个分片只能对应1个服务节点)。ClickHouse并不像其他分布式系统那样,拥有高度自动化的分片功能。ClickHouse提供了本地表(Local Table)与分布式表(Distributed Table)的概念。一张本地表等同于一份数据的分片。而分布式表本身不存储任何数据,它是本地表的访问代理,其作用类似分库中间件。借助分布式表,能够代理访问多个数据分片,从而实现分布式查询。这种设计类似数据库的分库和分表,十分灵活。例如在业务系统上线的初期,数据体量并不高,此时数据表并不需要多个分片。所以使用单个节点的本地表(单个数据分片)即可满足业务需求,待到业务增长、数据量增大的时候,再通过新增数据分片的方式分流数据,并通过分布式表实现分布式查询。这就好比一辆手动挡赛车,它将所有的选择权都交到了使用者的手中!
(2)列式存储
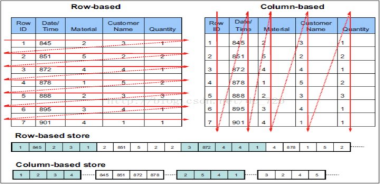
1)如前所述,分析场景中往往需要读大量行但是少数几个列。在行存模式下,数据按行连续存储,所有列的数据都存储在一个block中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO cost,加速了查询。
2)同一列中的数据属于同一类型,压缩效果显著。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
3)更高的压缩比意味着更小的data size,从磁盘中读取相应数据耗时更短。
4)自由的压缩算法选择。不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法。
5)高压缩比,意味着同等大小的内存能够存放更多数据,系统cache效果更好。
官方数据显示,通过使用列存,在某些分析场景下,能够获得100倍甚至更高的加速效应。
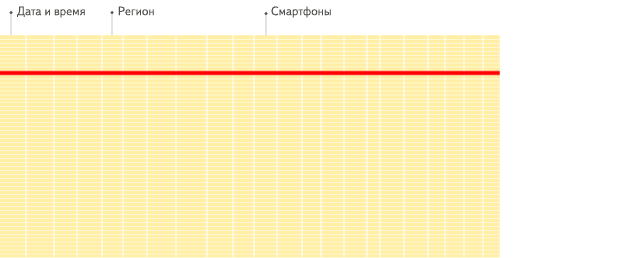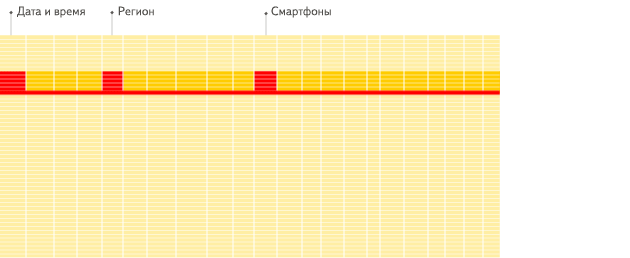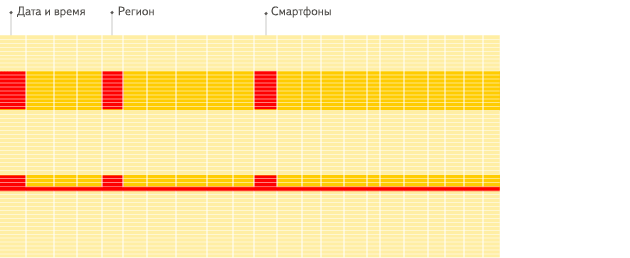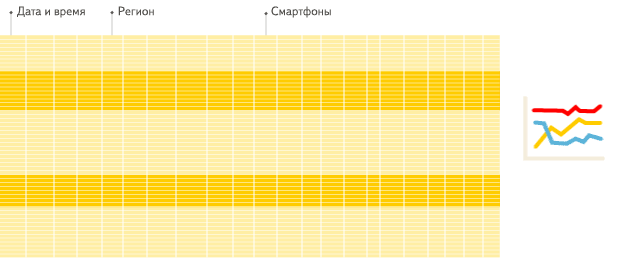
(3) 向量化
ClickHouse不仅将数据按列存储,而且按列进行计算。传统OLTP数据库通常采用按行计算,原因是事务处理中以点查为主,SQL计算量小,实现这些技术的收益不够明显。但是在分析场景下,单个SQL所涉及计算量可能极大,将每行作为一个基本单元进行处理会带来严重的性能损耗:
1)对每一行数据都要调用相应的函数,函数调用开销占比高;
2)存储层按列存储数据,在内存中也按列组织,但是计算层按行处理,无法充分利用CPU cache的预读能力,造成CPU Cache miss严重;
3)按行处理,无法利用高效的SIMD指令;
ClickHouse实现了向量执行引擎(Vectorized execution engine),对内存中的列式数据,一个batch(批量)调用一次SIMD指令(而非每一行调用一次),不仅减少了函数调用次数、降低了cache miss,而且可以充分发挥SIMD指令的并行能力,大幅缩短了计算耗时。向量执行引擎,通常能够带来数倍的性能提升。
(SIMD全称Single Instruction Multiple Data,单指令多数据流,能够复制多个操作数,并把它们打包在大型寄存器的一组指令集。以同步方式,在同一时间内执行同一条指令。)
(4) 表
上层数据的视图展示概念 ,包括表的基本结构和数据
(5) 分区
ClickHouse支持PARTITION BY子句,在建表时可以指定按照任意合法表达式进行数据分区操作,比如通过toYYYYMM()将数据按月进行分区、toMonday()将数据按照周几进行分区、对Enum类型的列直接每种取值作为一个分区等。数据以分区的形式统一管理和维护一批数据!
(6) 副本
数据存储副本,在集群模式下实现高可用 , 简单理解就是相同的数据备份,在CK(ClickHouse缩写)中通过复制集,我们实现保障了数据可靠性外,也通过多副本的方式,增加了CK查询的并发能力。这里一般有2种方式:
(1)基于ZooKeeper的表复制方式;
(2)基于Cluster的复制方式。
由于我们推荐的数据写入方式本地表写入,禁止分布式表写入,所以我们的复制表只考虑ZooKeeper的表复制方案。
(7) 引擎 必须指定引擎
不同的引擎决定了表数据的存储特点,位置和表数据的操作行为:
-
决定表存储在哪里以及以何种方式存储
-
支持哪些查询以及如何支持
-
并发数据访问
-
索引的使用
-
是否可以执行多线程请求
-
数据是否存储副本
-
并发操作 insert into tb_x select * from tb_x ;
表引擎决定了数据在文件系统中的存储方式,常用的也是官方推荐的存储引擎是MergeTree系列,如果需要数据副本的话可以使用ReplicatedMergeTree系列,相当于MergeTree的副本版本。读取集群数据需要使用分布式表引擎Distribute。
二、ClickHouse部署
ClickHouse支持运行在主流64位CPU架构(X86、AArch和 PowerPC)的Linux操作系统之上,可以通过源码编译、预编译压缩包、Docker镜像和RPM等多种方法进行安装。
1、单节点部署
yum -y install yum-utils
rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG
yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/clickhouse.repo
yum -y install clickhouse-server clickhouse-client
/etc/init.d/clickhouse-server start -- 启动服务
2、CK目录介绍
程序在安装的过程中会自动构建整套目录结构,接下来分别说明它们的作用。
(1)/etc/clickhouse-server
服务端的配置文件目录,包括全局配置config.xml 和用户配置users.xml等。

(2)/var/lib/clickhouse
默认的数据存储目录(通常会修改默认路径配置,将数据保存到大容量磁盘挂载的路径)。
(3)/var/log/clickhouse-server
默认保存日志的目录(通常会修改路径配置,将日志保存到大容量磁盘挂载的路径)。

(4)/usr/bin 默认添加进系统环境变量中
在/usr/bin下搜索命令
find ./ -name "clickhouse*"
clickhouse:主程序的可执行文件。
clickhouse-client:一个指向ClickHouse可执行文件的软链接,供客户端连接 使用。
clickhouse-server:一个指向ClickHouse可执行文件的软链接,供服务端启动 使用。
clickhouse-compressor:内置提供的压缩工具,可用于数据的正压反解。
3、CK服务启动
(1)修改数据、日志文件目录(也可不修改)
vi /etc/clickhouse-server/config.xml
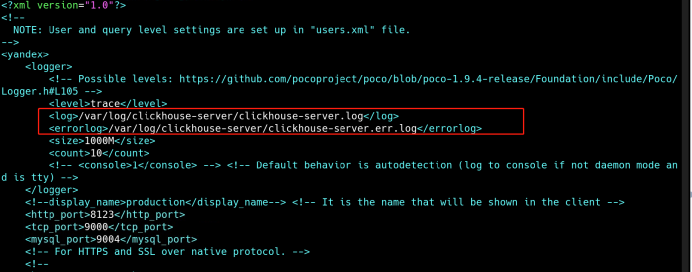
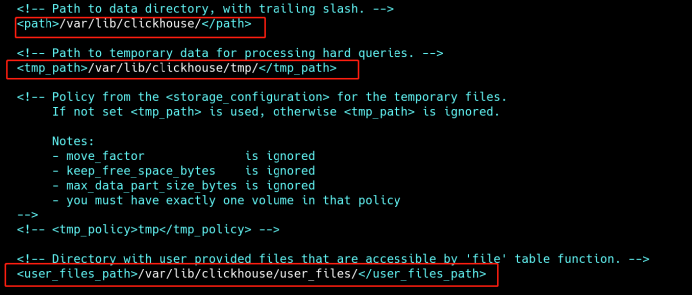
<path>/chbase/data/</path>
<tmp_path>/chbase/data/tmp/</tmp_path>
<user_files_path>/chbase/data/user_files/</user_files_path>
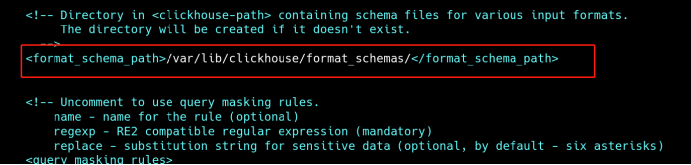
<format_schema_path>/chbase/data/format_schemas/</format_schema_path>
(2)启动服务
ClickHouse的底层访问接口支持TCP和HTTP两种协议,其中,TCP 协议拥有更好的性能,其默认端口为9000,主要用于集群间的内部通信及CLI客户端;而HTTP协议则拥有更好的兼容性,可以通过REST服务的形式被广泛用于JAVA、Python等编程语言的客户端,其默认端口为8123。通常而言,并不建议用户直接使用底层接口访问ClickHouse,更为推荐的方式是通过CLI和JDBC这些封装接口,因为它们更加简单易用!
# 启动
/etc/init.d/clickhouse-server start
# 停止
/etc/init.d/clickhouse-server stop
查看9000端口
netstat -nltp | grep 9000
tcp6 0 0 :::9000 :::* LISTEN 1354/clickhouse-ser
(3)连接客户端
交互式客户端
clickhouse-client -u default --password -m
默认用户即为 default ,默认不设置密码,所以以上命令可以简写为
clickhouse-client -m
一些其他命令:
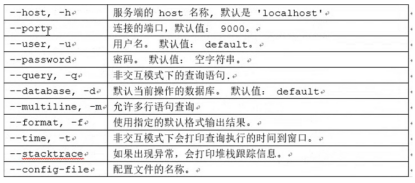
(1)–host/-h:服务端的地址,默认值为localhost。如果修改了 config.xml内的listen_host,则需要依靠此参数指定服务端 地址
(2)–port:服务端的TCP端口,默认值为9000。如果要修改config.xml内的tcp_port,则需要使用此参数指定。
(3)–user/-u:登录的用户名,默认值为default。如果使用非 default的其他用户名登录,则需要使用此参数指定,例如下 面所示代码。关于自定义用户的介绍将在后面介绍或者关注博客地址。 https://blog.csdn.net/qq_37933018?t=1
(4)–password:登录的密码,默认值为空。如果在用户定义中未设置 密码,则不需要填写(例如默认的default用户)。
(5)–database/-d:登录的数据库,默认值为default。
(6)–query/-q:只能在非交互式查询时使用,用于指定SQL语句。
(7)–multiquery/-n:在非交互式执行时,允许一次运行多条SQL语 句,多条语句之间以分号间隔。
(8)–time/-t:在非交互式执行时,会打印每条SQL的执行时间
(9)-m:允许换行
非交互式客户端
非交互式执行方式一般只执行一次 ,不进入到客户中的非操作方式 ,用户测试,数据导入, 数据导出非常方便 !
clickhouse-client -n -q
clickhouse-client -q -n 'show databases; use test1;' ;
-n 支持同时执行多个SQL语句 ,语句之间使用;号分割
-q 执行SQL语句
(4)使用 idea 远程连接
修改 /etc/clickhouse-server/config.xml 配置文件,使其支持远程连接

将 <listen_host>::</listen_host> 放开。其中 :: 的意思是任何机器都可以访问。
重启clickHouse
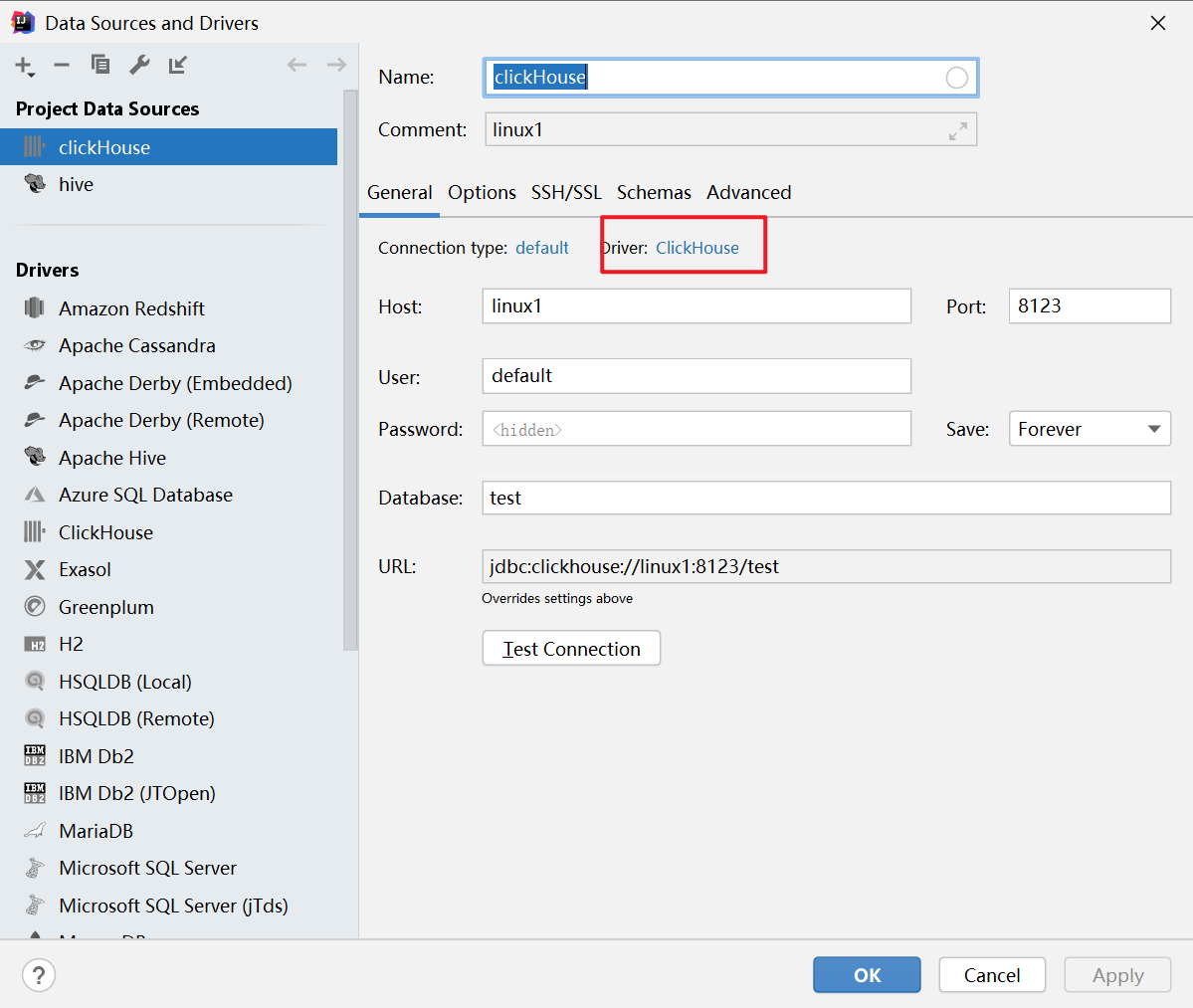
下载 ClickHose 驱动,输入主机、用户名即可连接
连接不成功检查以下几点:
- ClickHose 服务是否启动
- 域名映射是否正确
- 防火墙是否关闭
- 该服务是否允许远程连接
三、clickhouse基础入门
1、基本语法展示
-- 展示所有数据库
show databases ;
-- 创建数据库
create database if not exists test1 ;
-- 选择数据库
use test1 ;
-- 查看当前数据库
select currentDatabase() ;
-- 删除数据库
drop database test1 ;
-- 查看当前库下所有表
show tables ;
--查看建表语句:
show create table tb_orders3;
2、数据类型
注意在CK中关键字严格区分大小写,字符串用单引号
建表的时候一般情况下要指定引擎!!!表不同的引擎决定了数据存储的位置 数据存储的特点,以及上层操作的方式
create table tb_test1(
id Int8 ,
name String
)engine=Memory;
(一)数值类型
(1)IntX和UIntX
以前我们常用Tinyint、Smallint、Int和Bigint指代整数的不同取值范围。而ClickHouse则直接使用Int8、Int16、Int32和Int64指代4种大小的Int类型,其末尾的数字正好表明了占用字节的大小(8位=1字节)

ClickHouse支持无符号的整数,使用前缀U表示

create table test_int(
id Int8 ,
age UInt8 ,
cdId Int32
)engine=Memory ;
(2)FloatX

注意: 和我们以前的认知是一样的,这种数据类型在数据特别精准的情况下可能出现数据精度问题!
Select 8.0/0 -->inf 正无穷
Select -8.0/0 -->inf 负无穷
Select 0/0 -->nan 非数字
(3)Decimal
如果要求更高精度的数值运算,则需要使用定点数。ClickHouse提供了Decimal32、Decimal64和Decimal128三种精度的定点数。可以通过两种形式声明定点:
简写方式有Decimal32(S)、Decimal64(S)、 Decimal128(S)三种
原生方式为Decimal(P,S),其中:
P代表精度,决定总位数(整数部分+小数部分),取值范围是1 ~38;S代表规模,决定小数位数,取值范围是0~P
Decimal 总位数(P)多一位报错 小数部分(S)多一位自动抹去

在使用两个不同精度的定点数进行四则运算的时候,它们的小数点位数S会发生变化。
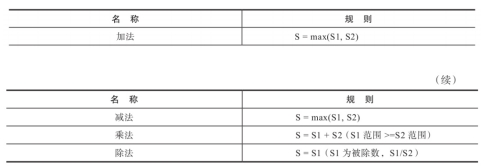
在进行加法运算时,S取最大值。例如下面的查询,toDecimal64(2,4)与toDecimal32(2,2)相加后S=4:
在进行减法运算时,S取最大值。例如下面的查询,toDecimal64(2,4)与toDecimal32(2,2)相减后S=4:
在进行乘法运算时,S取最和。例如下面的查询,toDecimal64(2,4)与toDecimal32(2,2)相乘后S=4+2:
在进行除法运算时,S取最大值。例如下面的查询,toDecimal64(2,4)与toDecimal32(2,2)相除后S=4:但是要保证被除数的S大于除数的S,否则会报错
create table test_decimal(
id Int8 ,
sal Decimal(5,2) -- 5 总位数 2 小数位 确定2
)engine=Memory ;
(二)字符串类型
字符串类型可以细分为String、FixedString和UUID三类。从命名来看仿佛不像是由一款数据库提供的类型,反而更像是一门编程语言的设计,没错CK语法具备编程语言的特征(数据+运算)
(1)String
字符串由String定义,长度不限。因此在使用String的时候无须声明大小。它完全代替了传统意义上数据库的Varchar、Text、Clob和Blob等字符类型。String类型不限定字符集,因为它根本就没有这个概念,所以可以将任意编码的字符串存入其中。但是为了程序的规范性和可维护性,在同一套程序中应该遵循使用统一的编码,例如“统一保持UTF-8编码”就是一种很好的约定。所以在对数据操作的时候我们不在需要区关注编码和乱码问题!
(2)FixedString
FixedString类型和传统意义上的Char类型有些类似,对于一些字符有明确长度的场合,可以使用固定长度的字符串。定长字符串通过FixedString(N)声明,其中N表示字符串长度。但与Char不同的是, FixedString使用null字节填充末尾字符,而Char通常使用空格填充。比如在下面的例子中,字符串‘abc’虽然只有3位,但长度却是5,因为末尾有2位空字符填充 !
create table test_str(
name String ,
job FixedString(4) -- 最长4个字符
)engine=Memory ;
(3)UUID
UUID是一种数据库常见的主键类型,在ClickHouse中直接把它作为一种数据类型。UUID共有32位,它的格式为8-4-4-4-12。如果一个UUID类型的字段在写入数据时没有被赋值,则会依照格式使用0填充
CREATE TABLE test_uuid
(
`uid` UUID,
`name` String
)
ENGINE = Log ;
DESCRIBE TABLE test_uuid
┌─name─┬─type───┬
│ uid │ UUID │
│ name │ String │
└──────┴────────┴
--以下两种写法等价
insert into test_uuid select generateUUIDv4() , 'zss' ;
insert into test_uuid values (generateUUIDv4() , 'zss') ;
select * from test_uuid ;
┌──────────────────────────────────uid─┬─name─┐
│ 47e39e22-d2d6-46fd-8014-7cd3321f4c7b │ zss │
└──────────────────────────────────────┴──────┘
-------------------------UUID类型的字段默认补位0-----------------------------
insert into test_uuid (name) values('hangge') ;
┌──────────────────────────────────uid─┬─name─┐
│ 47e39e22-d2d6-46fd-8014-7cd3321f4c7b │ zss │
└──────────────────────────────────────┴──────┘
┌──────────────────────────────────uid─┬─name───┐
│ 00000000-0000-0000-0000-000000000000 │ hangge │
└──────────────────────────────────────┴────────┘
(三)时间类型
(1) Date
Date类型不包含具体的时间信息,只精确到天,支持字符串形式写入:
CREATE TABLE test_date
(
`id` int,
`cd` Date
)
ENGINE = Memory ;
DESCRIBE TABLE test_date ;
┌─name─┬─type──┬
│ id │ Int32 │
│ ct │ Date │
└──────┴───────┴
insert into test_date vlaues(1,'2021-09-11'),(2,now()) ;
select id , ct from test_date ;
┌─id─┬─────────ct─┐
│ 1 │ 2021-09-11 │
│ 2 │ 2021-05-17 │
└────┴────────────┘
(2) DateTime
DateTime类型包含时、分、秒信息,精确到秒,支持字符串形式写入:
create table testDataTime(ctime DateTime) engine=Memory ;
insert into testDataTime values('2021-12-27 01:11:12'),(now()) ;
select * from testDataTime ;
(3)DateTime64
DateTime64可以记录亚秒(毫秒),它在DateTime之上增加了精度的设置
create table testDataTime64(ctime DateTime64) engine=Memory ;
insert into testDataTime64 values('2021-12-27 01:11:12.189'),(now()) ;
select * from testDataTime64 ;
(4)三种日期类型都支持插入时间戳
注意:Date 、Date32、DateTime 都只支持单位为秒的时间戳,单位为毫秒的时间戳在这三个类型中解析出的时间会出错
DateTime64 支持单位为毫秒的时间戳
create table tb_date(
cdate01 Date ,
cdate02 Date32 ,
cdate03 DateTime ,
cdate04 DateTime64
)engine = Memory ;
insert into tb_date values (1632628849 , 1632628849 ,1632628849 ,1632628849189) ;
┌────cdate01─┬────cdate02─┬─────────────cdate03─┬─────────────────cdate04─┐
│ 2021-09-26 │ 2021-09-26 │ 2021-09-26 12:00:49 │ 2021-09-26 12:00:49.189 │
└────────────┴────────────┴─────────────────────┴─────────────────────────┘
(四)复杂类型
(1)Enum 枚举
ClickHouse支持枚举类型,这是一种在定义常量时经常会使用的数据类型。ClickHouse提供了Enum8和Enum16两种枚举类型,它们除了取值范围不同之外,别无二致。枚举固定使用(String:Int)Key/Value键值对的形式定义数据,所以Enum8和Enum16分别会对应(String:Int8)和(String:Int16)!
create table test_enum(id Int8 , color Enum('red'=1 , 'green'=2 , 'blue'=3)) engine=Memory ;
insert into test_enum values(1,'red'),(1,'red'),(2,'green');
--也可以使用这种方式进行插入数据:
insert into test_enum values(3,3) ;
-- 报错 枚举定义的时候没有这个值 限制值的使用
insert into t_enum values(4,'PINK');
在定义枚举集合的时候,有几点需要注意。首先,Key和Value是不允许重复的,要保证唯一性。其次,Key和Value的值都不能为Null,但Key允许是空字符串。在写入枚举数据的时候,只会用到Key字符串部分,
注意: 其实我们可以使用字符串来替代Enum类型来存储数据,那么为什么是要使用枚举类型呢?这是出于性能的考虑。因为虽然枚举定义中的Key属于String类型,但是在后续对枚举的所有操作中(包括排序、分组、去重、过滤、底层存储等),会使用Int类型的Value值 ,提高处理数据的效率!
- 限制枚举类型字段的值
- 底层存储的是对应的Int类型的数据 , 使用更小的存储空间
- 可以使用String来替代枚举 / 没有值的限定
- 插入数据的时候可以插入指定的字符串 也可以插入对应的int值
(2)Array(T) 数组
CK支持数组这种复合数据类型 , 并且数据在操作在今后的数据分析中起到非常便利的效果!数组的定义方式有两种 : array(e1,e2…)或[e1,e2…]
数组中的数据类型必须是一致的!
CK数组取元素 角标从1开始
-- 数组的定义
[1,2,3,4,5]
array('a' , 'b' , 'c')
create table test_array(
id Int8 ,
hobby Array(String)
)engine=Memory ;
insert into test_array values(1,['eat','drink','la']),(2,array('sleep','palyg','sql'));
select id , hobby , toTypeName(hobby) from test_array ;
┌─id─┬─hobby───────────────────┬─toTypeName(hobby)─┐
│ 1 │ ['eat','drink','la'] │ Array(String) │
│ 2 │ ['sleep','palyg','sql'] │ Array(String) │
└────┴─────────────────────────┴───────────────────┘
--数组一些相关函数 arr代表数组名
-- 数组取值 注意,角标从1开始
arr[index]
arrayElement(arr,index)
--数组长度
length(arr)
arr.size0
--数组的高阶函数
arrayMap(函数,数组名) --对数组中的每个数据处理
select id , name , arrayMap(e->upper(e) , fs) from t_friend ;
(3)Tuple 元组
元组类型由1~n个元素组成,每个元素之间允许设置不同的数据类型,且彼此之间不要求兼容。元组同样支持类型推断,其推断依据仍然以最小存储代价为原则。与数组类似,元组也可以使用两种方式定义,tuple(…)、(…) 。元组中可以存储多种数据类型,但是要注意数据类型的顺序
select tuple(1,'asb',12.23) as x , toTypeName(x) ;
┌─x───────────────┬─toTypeName(tuple(1, 'asb', 12.23))─┐
│ (1,'asb',12.23) │ Tuple(UInt8, String, Float64) │
└─────────────────┴────────────────────────────────────┘
---简写形式
SELECT (1, 'asb', 12.23) AS x,toTypeName(x)
┌─x───────────────┬─toTypeName(tuple(1, 'asb', 12.23))─┐
│ (1,'asb',12.23) │ Tuple(UInt8, String, Float64) │
└─────────────────┴────────────────────────────────────┘
--注意:建表的时候使用元组的需要制定元组的数据类型
CREATE TABLE test_tuple (
c1 Tuple(UInt8, String, Float64)
) ENGINE = Memory;
- col Tuple(Int8,Int8,String) – 定义泛型
select tupleElement(c1 , 2) from test_tuple; -- 获取元组指定位置的值
(4)Nested 嵌套
Nested是一种嵌套表结构。一张数据表,可以定义任意多个嵌套类型字段,但每个字段的嵌套层级只支持一级,即嵌套表内不能继续使用嵌套类型。对于简单场景的层级关系或关联关系,使用嵌套类型也是一种不错的选择。
create table test_nested(
uid Int8 ,
name String ,
props Nested(
pid Int8,
pnames String ,
pvalues String
)
)engine = Memory ;
desc test_nested ;
┌─name──────────┬─type──────────┬
│ uid │ Int8 │
│ name │ String │
│ props.pid │ Array(Int8) │
│ props.pnames │ Array(String) │
│ props.pvalues │ Array(String) │
└───────────────┴───────────────┴
嵌套类型本质是一种多维数组的结构。嵌套表中的每个字段都是一个数组,并且行与行之间数组的长度无须对齐。需要注意的是,在同一行数据内每个数组字段的长度必须相等。
可以对多个数组的元素的个数进行每行统一
insert into test_nested values(1,'hadoop',[1,2,3],['p1','p2','p3'],['v1','v2','v3']);
-- 行和行之间的属性的个数可以不一致 ,但是当前行的Nested类型中的数组个数必须一致
insert into test_nested values(2,'spark',[1,2],['p1','p2'],['v1','v2']);
SELECT *
FROM test_nested
┌─uid─┬─name───┬─props.pid─┬─props.pnames─────┬─props.pvalues────┐
│ 1 │ hadoop │ [1,2,3] │ ['p1','p2','p3'] │ ['v1','v2','v3'] │
└─────┴────────┴───────────┴──────────────────┴──────────────────┘
┌─uid─┬─name──┬─props.pid─┬─props.pnames─┬─props.pvalues─┐
│ 2 │ spark │ [1,2] │ ['p1','p2'] │ ['v1','v2'] │
└─────┴───────┴───────────┴──────────────┴───────────────┘
SELECT
uid,
name,
props.pid,
props.pnames[1]
FROM test_nested;
┌─uid─┬─name───┬─props.pid─┬─arrayElement(props.pnames, 1)─┐
│ 1 │ hadoop │ [1,2,3] │ p1 │
└─────┴────────┴───────────┴───────────────────────────────┘
┌─uid─┬─name──┬─props.pid─┬─arrayElement(props.pnames, 1)─┐
│ 2 │ spark │ [1,2] │ p1 │
└─────┴───────┴───────────┴───────────────────────────────┘
和单纯的多个数组类型的区别是: 每行数据中的每个属性数组的长度一致
(5)Map 键值对
create table t_map(
id Int8 ,
m Map(String,UInt8)
)engine = Memory ;
-- 插入数据 有两种方式
insert into t_map values(1 , map('zss',23,'lss',33,'ww',44)) ;
insert into t_map values(2 , {'zss':23,'lss':33,'ww':44}) ,(3, {'zss':23,'lss':33,'ww':44}) ;
select * from t_map;
┌─id─┬─m───────────────────────────┐
│ 1 │ {'zss':23,'lss':33,'ww':44} │
└────┴─────────────────────────────┘
//map取值也可以用arrayElement
select arrayElement(m,'zss') from t_map;
┌─arrayElement(m, 'zss')─┐
│ 23 │
└────────────────────────┘
(6)GEO
(7)IPV4 域名
域名类型分为IPv4和IPv6两类,本质上它们是对整型和字符串的进一步封装。IPv4类型是基于UInt32封装的,IPv6类型是基于FixedString(16)封装的
使用域名类型好处
- 出于便捷性的考量,例如IPv4类型支持格式检查,格式错误的IP数据是无法被写入的,例如:
INSERT INTO IP4_TEST VALUES ('www.51doit.com','192.0.0')
//报错
Code: 441. DB::Exception: Invalid IPv4 value.
- 出于性能的考量,同样以IPv4为例,IPv4使用UInt32存储,相比String更加紧凑,占用的空间更小,查询性能更快。IPv6类型是基于FixedString(16)封装的,它的使用方法与IPv4别无二致, 在使用Domain(域名)类型的时候还有一点需要注意,虽然它从表象上看起来与String一样,但Domain类型并不是字符串,所以它不支持隐式的自动类型转换。如果需要返回IP的字符串形式,则需要显式调用 IPv4NumToString或IPv6NumToString函数进行转换。
create table test_domain(
id Int8 ,
ip IPv4
)engine=Memory ;
insert into test_domain values(1,'192.168.133.2') ;
insert into test_domain values(1,'192.168.133') ; 在插入数据的会进行数据的检查所以这行数据会报错
-- Exception on client:
-- Code: 441. DB::Exception: Invalid IPv4 value.
-- Connecting to database doit1 at localhost:9000 as user default.
-- Connected to ClickHouse server version 20.8.3 revision 54438.
(8)Boolean和Nullable
ck中没有Boolean类型 ,使用1和0来代表true和false
Nullable 某种数据类型允许为null , 或者是没有给值的情况下模式是NULL
create table test_null(
id Int8 ,
age Int8
)engine = Memory ;
create table test_null2(
id Int8 ,
age Nullable(Int8)
)engine = Memory ;
(9)强制类型转换
使用 cast(v , dataType) 函数强制类型转换
SELECT cast(12.23 + 3, 'Int8')
┌─CAST(plus(12.23, 3), 'Int8')─┐
│ 15 │
└──────────────────────────────┘
cast函数的三种写法
select cast(12.23 + 3, 'Int8')
select cast(12.23 + 3 as Int8)
select (12.23 + 3) :: Int8 ;
使用cast实现拉链操作
-- 拉链操作
SELECT CAST(([1, 2, 3], ['Ready', 'Steady', 'Go']), 'Map(UInt8, String)') AS map;
┌─map───────────────────────────┐
│ {1:'Ready',2:'Steady',3:'Go'} │
└───────────────────────────────┘
SELECT CAST(([1, 2, 3], ['Ready', 'Steady', 'Go']), 'Map(UInt8, String)') AS map , mapKeys(map) as ks , mapValues(map) as vs;
┌─map───────────────────────────┬─ks──────┬─vs──────────────────────┐
│ {1:'Ready',2:'Steady',3:'Go'} │ [1,2,3] │ ['Ready','Steady','Go'] │
└───────────────────────────────┴─────────┴─────────────────────────┘
最后
以上就是自然大叔最近收集整理的关于ClickHouse基础一、clickhouse-简介二、ClickHouse部署三、clickhouse基础入门的全部内容,更多相关ClickHouse基础一、clickhouse-简介二、ClickHouse部署三、clickhouse基础入门内容请搜索靠谱客的其他文章。








发表评论 取消回复