【论文笔记】Any Way You Look at It: Semantic Crossview Localization and Mapping With LiDAR
~~~ ~~~~ 目前,GPS 是目前最流行的全球定位方法。但是,它并不总是在所有环境中都可靠或准确。 SLAM 方法支持局部状态估计,但没有提供将局部地图注册到全局地图的方法,这对于机器人间协作或人类交互很重要。在这项工作中,我们提出了一种实时方法,利用语义来全局定位机器人,仅使用以自我为中心的 3D 语义标记 LiDAR 和 IMU,以及从卫星或空中机器人获得的自上而下的 RGB 图像。此外,当它运行时,我们的方法会构建一个全局注册的环境语义图。我们在 KITTI 以及我们自己的具有挑战性的数据集上验证了我们的方法,并显示出优于 10 m 的精度、高度的鲁棒性以及在最初未知的情况下动态估计自上而下地图比例的能力。
方法
~~~
~~~~
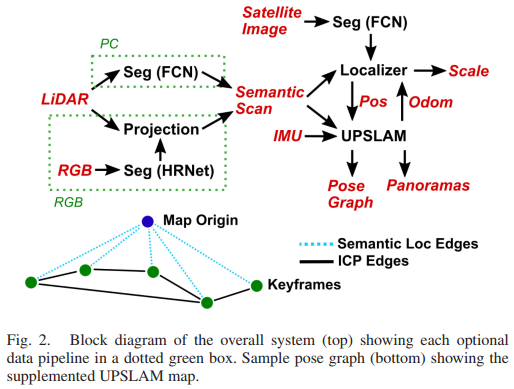
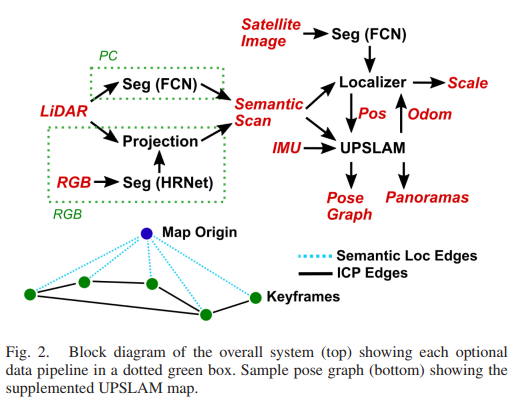
我们的方法由两个主要组件组成:基于 ICP 的 LiDAR SLAM 系统——全景 SLAM 联合 [32](UPSLAM)——和基于粒子滤波器的语义定位器,如图 2 所示。这里我们详细介绍了两者的目的和实现这些系统中。
我们在这项工作中的贡献如下:
1) 我们提出了一个实时跨视图定位和映射框架,使用语义点云定位到一个高架地图。如果航空地图未知但有界,我们的方法也能够估计它的比例。
2) 我们使用 SemanticKITTI [17] 以及我们自己在包括农村和城市环境在内的各种位置的数据集来验证我们提出的方法。另外使用推断的、嘈杂的、真实的分割数据执行验证。
3) 我们发布数据集和本地化代码,以便更广泛的研究社区在该领域进一步开展工作。
我们的框架只需要单个卫星或环境鸟瞰图,使其适用于更多应用。
https://github.com/iandouglas96/cross_view_slam
定位
~~~
~~~~
受蒙特卡罗方法在机器人定位方面取得成功的启发 [10]、[22]、[29],我们采用粒子滤波器作为定位管道的主干。粒子滤波器特别擅长处理多模态分布,这在机器人定位问题中经常出现。然而,这是以计算成本为代价的,我们通过采用定制的优化策略来减轻这种成本。
1) 问题公式:对于 2D 地图定位,我们的系统状态 x 由元组 (p ∈ SE(2), s ∈ [smin, smax]) 组成,其中 p 是机器人在地图上的方向和位置(以米为单位), s(以 px/m 为单位)是地图比例尺,在其边界上有一些先验。我们另外还有输入 u ∈ SE(3),即来自 UPSLAM 或任何其他里程计源的最后一帧(以米为单位)的机器人刚体变换。然后我们面临为每个时间步长 t 定义运动模型 P(xt | xt−1, ut−1) 的问题。此外,在每个 t 我们从我们的 LiDAR 和相机获得语义扫描 zt。为了定义我们的粒子滤波器,我们还必须定义测量模型 P(zt | xt)。
2) 运动模型:我们不假设可以访问机器人的控制输入,而是依赖于来自 UPSLAM 的帧到帧运动估计。因为 UPSLAM 在 3D 中运行,我们首先将帧到帧的运动投影到局部 x-y 地平面上,我们将这个操作表示为 proj(u) ∈ SE(2)。此外,我们仅使用来自 UPSLAM 的初始 ICP 解决方案进行运动估计,忽略来自闭环的优化姿态以避免里程计的不连续性。最后,我们假设每个估计的协方差为常数的正态分布噪声,尺度噪声存在于对数空间中。总之,
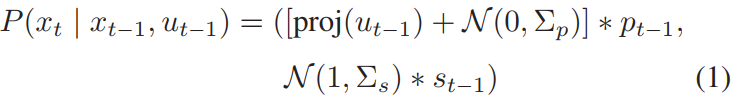
我们另外用与起始位置的距离的倒数来缩放 Σs,以促进自然收敛。一旦状态中的尺度方差低于阈值,我们就修复 s。
3) 测量模型:我们的测量值 z 是一个语义点云,我们可以将其表示为机器人框架中带有相关标签的点位置列表:z = {(p1, l1), (p2, l2), … . .(pn, ln)}。然后我们可以将这些点投影到地平面上。此外,对于任何给定的粒子状态,我们可以查询自上而下的航空地图 L,以获取机器人框架中任何点的预期类别。计算具有姿势 d 的特定粒子的成本的一种简单方法是
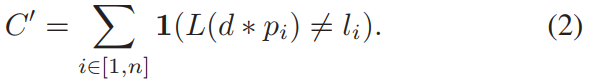
为了通过扩大局部最小值来提高收敛性,我们选择了一个更软的成本函数。我们不是以二元方式评估成本,而是惩罚特定类别的点与航空地图上同一类别的最近点的(阈值)距离。成本函数则变为
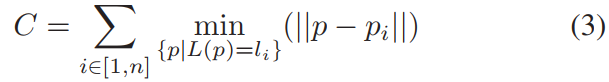
最后,我们通过反转 C 和归一化来计算临时概率。我们另外引入了一个每类加权因子 αl。那是,
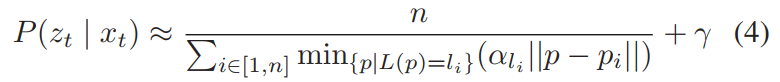
其中 γ 是引入缓慢收敛的正则化常数。所有粒子的概率最终被归一化,使得它们在所有粒子上的总和为 1。我们注意到这是一个临时措施,并且在实践中通过实验调整常数。然而,这对于基于蒙特卡罗的定位方法(例如 [29])并不少见。
4)性能优化:天真地实现,等式。 3 的计算成本非常高,因为它相当于对一系列(非凸)最小化的结果求和。我们通过为航空语义地图预先计算按类别截断的距离场 (TDF) 来优化这一点。计算的实现非常天真,大约需要一分钟,但每个地图只需执行一次。该图对从每个点到该类最近点的阈值距离进行编码,从而使方程 3 的最小化。 3 进入一个简单的固定时间查找。此外,我们不是对所有点求和,而是首先将语义 LiDAR 扫描离散为极坐标段,并计算每个段中每个类的点数。本地按类别截断的距离场以相同的方式呈现。然后我们可以近似方程。 3 通过对这两个图像的元素乘积求和,得出每个类的一个内积运算,这是一种可以高效执行的计算。我们发现对于 100 × 25 像素的极坐标图,每个粒子大约需要 500 微秒,几乎所有时间都用于查找极坐标 TDF。这个过程如图 3 所示。
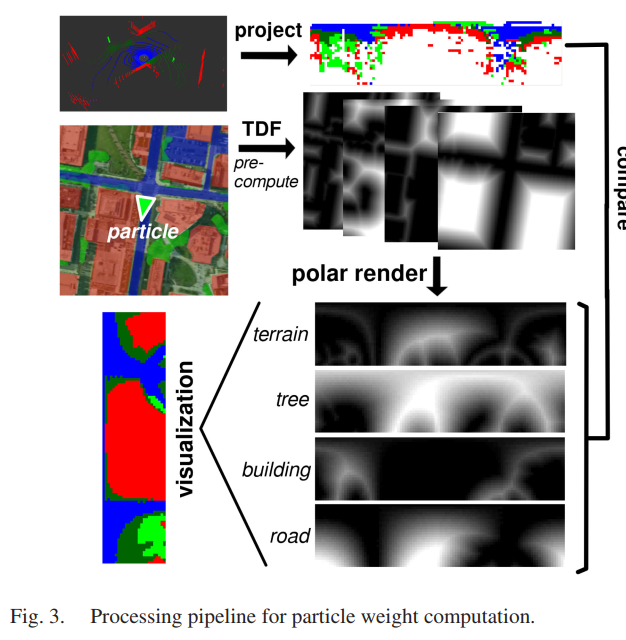
此外,在极坐标表示中旋转地图相当于索引偏移并且非常快,这是我们在初始化期间利用的事实。我们在地图道路上随机采样点,因为我们有很强的先验知识,我们开始在道路上。对于每个点,我们初始化 ks 粒子在 smin 和 smax 之间均匀变化的尺度(我们的实验为 1 和 10 px/m)。对于每个粒子,我们统一采样 kθ 可能的方向,我们可以通过索引偏移非常有效地做到这一点。我们选择最佳方向并将其用作我们的初始粒子。
为了进一步加速我们的算法,我们将跨 CPU 内核的每个粒子的成本计算并行化。我们还根据适合粒子分布的高斯混合模型 (GMM) 的协方差椭圆的面积总和自适应地选择粒子数。我们预计将粒子权重计算移到 GPU 上可以获得较大的性能提升,但将此留作未来的工作。
语义分割
~~~
~~~~
1) 卫星分割:我们训练两个稍加修改的全卷积网络 (FCN) [33] 版本,使用在 ImageNet 上预训练的 ResNet-34 [34] 主干来分割卫星图像。图片直接从谷歌地球拍摄。我们使用 4 个类:道路、地形、植被和建筑物。为了分析卫星图像,256 × 256 px RGB 图像作为输入传递到图像分割网络。该网络在来自表 I 数据集中的三个手动标记的卫星图像上进行了训练。图像被随机缩放、旋转、裁剪和翻转以生成更多的训练样本。卫星图像的随机缩放还允许模型更好地概括从多个高度收集的图像。我们网络的示例输出和训练数据可以在图 5 中看到。 尽管我们的模型尽管只训练了 3 张图像,但表现良好似乎令人惊讶,但每张图像都包含许多对象实例,而且训练图像来自相同的city 作为测试图像,需要最少的泛化。

2) 扫描分割:我们使用图 2 中绿色框所示的两个不同管道来根据数据集生成语义点云。通过使用这些不同的分割方法进行测试,我们表明我们的方法可以在不同的传感系统之间很好地泛化,前提是最终输出是逐点标记的点云。
PC:对于 KITTI 数据集,我们使用与卫星分割相同的 FCN 结构(也经过 ImageNet 预训练),但对 LiDAR 扫描进行操作,该扫描表示为大小为 (64, 2048) 的 2D Polar Grid Map,具有 X、Y、Z 和深度通道(我们不使用强度)。我们在 SemanticKITTI 上训练并使用 {10} 和 {00, 02, 09} 作为验证和测试分割,其余数据在训练分割中。我们还在用于卫星分割的类集中添加了额外的车辆和其他类,作为自上而下投影过程的一部分,车辆被转换为道路。
RGB:对于我们自己的 Morgantown 和 UCity 数据集,我们使用与 KITTI(Ouster OS-1)不同的 LiDAR 传感器,因此不能将 SemanticKITTI 用于训练数据。我们改为使用在 Cityscapes [35] 上训练的 HRNets [13] 对校准到 LiDAR 的 RGB 图像进行分割。使用我们计算的外部函数,我们可以将 LiDAR 点云投影到相机帧上,并为来自 RGB 分割的每个点分配适当的类。
建图
~~~
~~~~
我们使用 [32] 中描述的 UPSLAM 映射器,但在此处简要概述了我们的相关更改。 UPSLAM 使用迭代最近点 (ICP) 估计 LIDAR 传感器的运动,并根据附加到关键帧的全景深度图集合来表示整体几何形状,关键帧相互连接以形成姿势图。对于这项工作,我们扩展了 UPSLAM 以额外集成从图像中提取的语义标签以形成语义全景图。值得注意的是,UPSLAM 根本不使用语义进行扫描匹配,它只是使用估计的刚体变换来整合语义信息。因此,因为我们不需要每次扫描都需要语义数据,所以我们可以以低于 LiDAR 的速率运行我们的推理,而无需移除 ICP 数据以提高地图质量。样本深度、正常和语义全景图如图 4 所示。

除了对粒子滤波器运动模型使用 UPSLAM 自我运动估计之外,我们还计算每次更新时后验粒子滤波器估计的协方差和均值。一旦协方差低于阈值 Σt,我们使用相对于开销图的估计位置作为姿态图中的先验因素,将相应的全景图锚定到全局图上。最终生成的姿态图如图 2 所示。通过这种方式,我们允许图优化还基于全局定位对全局地图进行地理配准。我们的实验表明,添加这些语义边缘可以消除漂移,有效地在每个关键帧处为全局地图创建语义循环闭包。这使映射器能够在没有循环的情况下处理更大的轨迹,同时保持全局一致。
评估数据集
~~~
~~~~
我们首先在 SemanticKITTI [17] 上评估我们的系统,这是来自 KITTI 里程计基准 [36] 的手动逐点标记的 LiDAR 扫描数据集。在这项工作中,我们测试了里程计数据集的运行 00、02 和 09。
除了 SemanticKITTI,我们还在宾夕法尼亚州费城和摩根敦收集了我们自己的数据集,以便在更多样化的环境中进行测试。这些数据集是使用 Ouster OS-1-64 LiDAR 和 4 个 PointGrey Flea3 RGB 相机收集的。相机是与 Ouster 同步的硬件,并使用我们在 [37] 中提出的方法进行校准。表 I 概述了我们用于评估的数据集。我们还使用了一个额外的数据集 ucity’,它遵循与 ucity 相同的轨迹,但在几个月前被采用。我们另外启动 kitti2 50 秒和 kitti9 10 秒,以避免在数据集开始时 UPSLAM 失败的区域。
结果
推断性能
~~~
~~~~
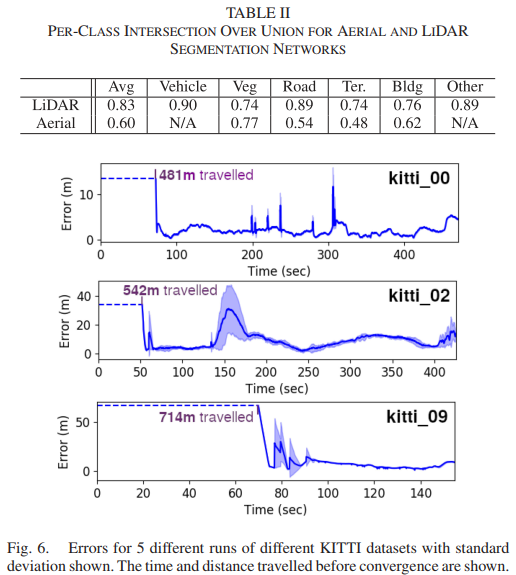
我们首先评估推理网络的性能,其结果如表 II 所示。对于 LiDAR 网络,测试集为 KITTI 00、02 和 09。对于航拍网络,模型在每张训练图像的 3/4 上进行训练;最后的 1/4 用于评估。我们注意到这并不能很好地测试对其他城市的泛化,但强大的多城市空中分割不是这项工作的重点。然而,我们强调,我们的定位器能够在分割数据中的显着真实噪声下表现良好,无论是在 LiDAR 扫描还是航拍图像中
准确性
~~~
~~~~
我们通过在 KITTI 00、02 和 09 上对每个轨迹运行 5 次进行测试,使用主动尺度估计以及使用固定的地面实况尺度。一次此类运行的结果图如图 5 所示。
图 6 显示了在自动检测到收敛后整个数据集中的像素位置误差。对于这些运行,向系统提供了真实值比例。除了 kitti9 之外,所有运行的所有参数都是固定的,我们将角过程噪声增加了 10 倍,因为 UPSLAM 的估计噪声更大。平均误差分别为 2.0、9.1 和 7.2 米。对于后来的数据集,误差集中在几个局部区域,这些区域通常是 UPSLAM 挣扎的区域(通常在几何结构较少的树的隧道状区域),因此运动先验不那么准确。我们将这些结果与表 III 中的 [20] 和 [29] 进行比较。通过合并更丰富的语义数据,我们能够在 kitti0 上的性能超过 [29] 10 倍。金等人。 [20] 获得与我们相当的定位精度,尽管使用单个 RGB 相机而不是 LiDAR,并且需要在卫星图像上的网格上预先计算深度嵌入。
这些在 KITTI 上的实验完全实时进行,包括分割、定位和映射,在 AMD Ryzen 9 3900X CPU 和 NVidia GeForce RTX 2080 GPU 上运行。这种级别的计算可以很容易地安装在车辆或中等大小的地面机器人上。我们还期望通过进一步优化我们的方法,例如将粒子权重函数移动到 GPU,我们可以在计算资源更受限的平台上实时运行。
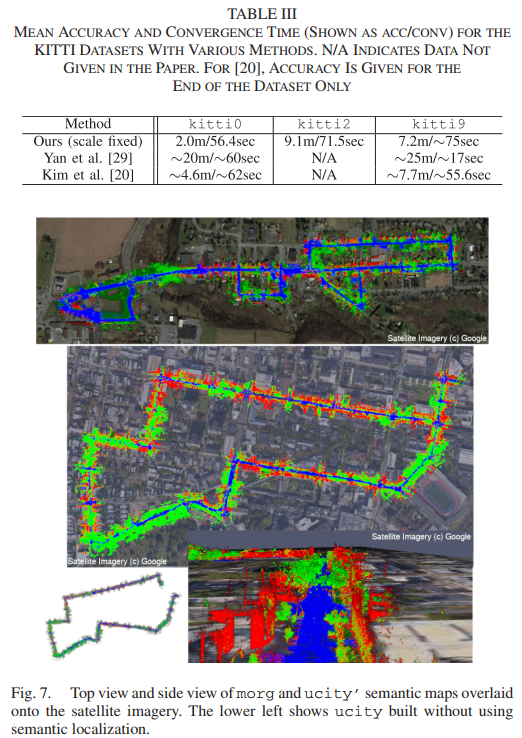
此外,我们定性地检查了图 7 中 ucity’ 和 morg 的结果。我们注意到,通过将全局边合并到映射器位姿图中,我们不仅能够在自上而下的图像中全局定位机器人,还可以改进全局地图一致性。在长循环过程中,UPSLAM 本身由于漂移无法找到闭环,从而导致全局不一致的映射。结合语义定位器的全局边缘可以减轻这种漂移,使 UPSLAM 能够成功找到闭环。
收敛性
~~~
~~~~
我们通过在整个数据集中以均匀间隔开始运行,对 UCity、Morgantown 和 KITTI 0 和 2 数据集执行收敛分析。我们不分析 kitti9,因为它相对较短。我们将正确收敛率定义为收敛后前 20 秒的平均误差小于 10 米的检测到的收敛的分数。图 8 显示了正确收敛到整体检测到的收敛的频率。我们忽略粒子过滤器在运行结束之前没有收敛的运行,这种情况发生在数据集中剩余时间小于收敛时间的开始时间。除了在固定尺度情况下将正则化项 γ 加倍外,所有运行都使用相同的参数。
从这些结果我们得出结论,在估计规模时收敛更困难,这与我们的直觉一致。我们在这两种情况下使用相同数量的粒子,使样本贫化的可能性更大。 ucity 对我们的系统来说明显更难,我们将其归因于环境更接近于一个统一的网格,其结构不太明显,以帮助定位。为了改进定位,我们在几个月前拍摄的相同轨迹 (ucity’) 的数据集上运行我们的定位器,并使用生成的地图来优化原始卫星分割。这个过程的结果如图 10 所示。使用这个新的细化地图 ucity ref,我们能够显着提高正确的收敛速度,这表明先前的运行,尽管早了几个月,但能够为地图。金等人。 [20] 和严等人。 [29] 在表 III 中获得可比时间,但无法估计规模。对于 kitti9,由于数据集较短,我们只从头开始。请注意,这些工作仅从数据集开始计算收敛时间,而我们从各个点开始计算收敛时间。
最后,对图 9 中我们系统的估计尺度的分析表明,在大多数情况下,我们的方法可以准确地估计尺度,大约为真实值的 0.05 倍。
消融研究
~~~ ~~~~ 注意到地图细化对于提高收敛性非常有帮助,我们调查了我们的定位器在多大程度上仅仅依赖于道路形状和轨迹,以及它在多大程度上使用了来自建筑物和树木的额外线索。我们消除了树木和建筑物的成本,并在图 11 中报告了这些发现。对于所有运行,我们假设一个固定的已知规模。我们得出结论,对于道路结构复杂的环境和轨迹,简单地利用轨迹并将其与道路模式匹配就足够了。然而,对于更像曼哈顿的结构,建筑物和树木等局部细节变得更加相关。有趣的是,对于 ucity,仅移除树木比同时移除建筑物和树木略差。我们假设这是因为在密集的城市环境中,两侧几乎总是有建筑物,因此它们在道路之外添加的结构很少,并且在噪音的情况下可能是有害的。然而,对于城市而言,树木显然提供了强有力的有用线索。
结论
~~~ ~~~~ 我们提出了一个系统,用于在卫星或自上而下的无人机图像中进行实时语义定位和映射。此外,我们还展示了在各种环境中使用不同传感器收集的多个数据集的定量和定性结果。在所有这些实验中,我们的系统都表现得稳健而准确。未来,我们 [25] 计划将我们的系统部署在异构机器人团队上,以实现分散映射和更高级别的自治。
最后
以上就是温婉胡萝卜最近收集整理的关于【论文笔记】Any Way You Look at It: Semantic Crossview Localization and Mapping With LiDAR【论文笔记】Any Way You Look at It: Semantic Crossview Localization and Mapping With LiDAR的全部内容,更多相关【论文笔记】Any内容请搜索靠谱客的其他文章。



![[论文阅读]Road Mapping and Localization using Sparse Semantic Visual Features速读以下是精读部分](https://www.shuijiaxian.com/files_image/reation/bcimg18.png)


![[学习SLAM]分析总结常见的几种移动机器人底盘类型及其运动学 两轮差速底盘(Differential Drive robot)三轮全向轮底盘(Three-wheel omnidirectional wheel robot)四轮全向轮底盘(Four-wheel omnidirectional wheel robot)四轮麦克纳姆轮底盘(Four-wheeled Mecanum wheel robot)四轮滑移底盘(Four-wheel sliding robot)四轮阿克曼底盘(Four-wh](https://www.shuijiaxian.com/files_image/reation/bcimg21.png)

发表评论 取消回复