Road Mapping and Localization using Sparse Semantic Visual Features
Cheng W, Yang S, Zhou M, et al. Road Mapping and Localization using Sparse Semantic Visual Features[J]. IEEE Robotics and Automation Letters, 2021. ICRA2021
单位:阿里巴巴
针对问题:
轻量级语义地图构建及定位。
提出方法:
文章采用了一种类似于关键点检测的方法,对典型路标进行典型关键点提取;对特定路标设计了不同的参数模型进行帧间优化,相较于无优化的点云叠加方式,该方法构建了特征间的数据关联,用于里程计自身的位姿估计同时也进行更精确的路标地图构建。
达到效果:
实现了KAIST数据集以及作者采集的数据集大场景范围内精确建图及定位。
存在问题:
文章所构建的定位模块在实现定位时采用GPS提供定位初值,再进行局部精搜索并使用PnP进行定位的策略,该方法在GPS信号较好且跳变较小时能实现较好效果,但在GPS-denied的场景使用受限,也许可以考虑结合HF-Net的方式进行初始定位。
Abstract
我们提出了一种新的方法,通过提取、建模和优化语义道路元素来实现自主车辆的视觉建图和定位。具体来说,我们的方法整合了级联深度模型来检测标准化的道路元素,而不是传统的点特征,以寻求提高位姿的准确性和地图表示的紧凑性。为了利用结构特征,我们通过其代表性的深层关键点为骨架和边界建立路灯和标志的模型,并通过piecewise cubic splines进行车道参数化。基于道路语义特征,我们建立了一个完整的建图和定位流程,其中包括a)图像处理前端,b)传感器融合策略,以及c)优化后端。在公共数据集和我们的测试平台上进行的实验证明了我们的方法的有效性和优势,其表现优于传统方法。
Main Contributions
一个卷积神经网络(CNN)支持的图像处理前端,以提取语义特征。
道路元素的参数化和损失函数的设计方法。
语义优化模块,可用于离线测绘和在线定位。
我们注意到,存在与我们的方法在概念上相似的方法,通过分割道路图像和选择稳定区域的点。然而,稳定语义区域中的点特征不一定是稳定和紧凑的,而且高水平的信息,例如曲线,也没有被利用。相比之下,我们的方法利用了多源语义信息,提供了更紧凑的表示,达到了更好的 "持久性 "和 "紧凑性"。
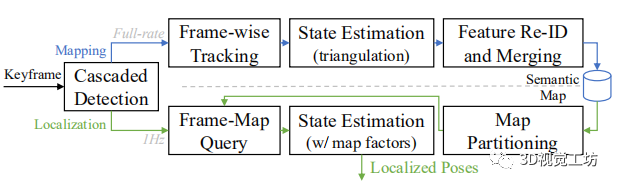
System Overview
我们的地图和定位系统的骨干是一个紧密耦合的状态优化框架,具有批量和滑动窗口策略。具体来说,我们的算法提出在离线情况下建立基于标准化道路实例的语义地图,并利用这种地图进行在线定位。所涉及的语义实例包括三种主要类型:水平物体、地面物体和车道。给予一个关键帧,感知模块执行级联深度检测,以提取实例和它们的代表点作为视觉特征.
在离线建图过程中,感知模块对每个关键帧都要执行。然后,对连续关键帧之间的检测结果进行跟踪,以建立多视角关联,共同估计相机轨迹和地标位置。随后,在以前访问过的路段上重新观察到的实例被重新识别,并通过循环检测进行合并。最后,这些优化的状态被序列化为地图资产用于定位。在在线地图辅助定位过程中,感知模块以较低的频率运行,以实现对计算单元的低成本消耗。因此,语义特征是通过混合检测和跟踪策略获得。这些特征与保存的地图相匹配,并由一个基于滑动窗口优化的测距系统使用,以减少全局漂移。
Selection of Road Features
考虑到地图的稀疏化和查询的有效性,城市道路上的以下标准化目标适合作为语义地标来检测:1)道路旁边电线杆顶部的灯和交通标志足够稳定和高,可以被前置摄像头捕捉。2)虽然有时会被车辆遮挡,但地面区域几乎占据了每张图像的一半,这使得那些涂在地面上的高对比度标志无法被忽略。3)与地面标志类似,涂有实线和虚线的车道也经常被观察到。实线车道提供了一个方向的运动约束,虚线车道的拐角可以被视为索引点地标。在这项工作中,我们选择上述语义类型作为目标对象,以建立我们的语义地图。
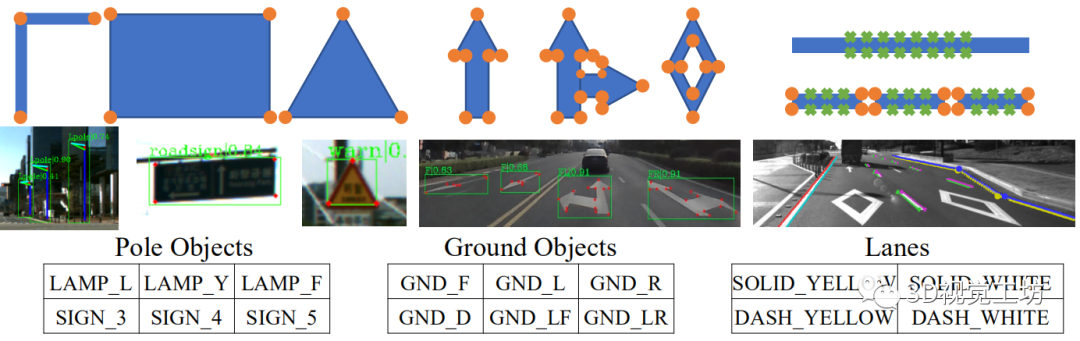
Detection of Road Features
我们的两阶段级联检测模块首先进行实例级检测,以获得实例作为盒子(即杆和地面)物体上的索引代表像素和车道轮廓上的样本像素。然后,沿着这些检测到的虚线车道,我们评估64×64的图像补丁,以级联检测有索引的虚线车道角。为了减少对特征提取等可共享过程的重复计算,我们参考了无锚检测方法CenterNet,该方法将低级特征提取过程与顶级头像分离,以使这些头像能够适应不同的任务。
Feature Tracking for Semantic Entities

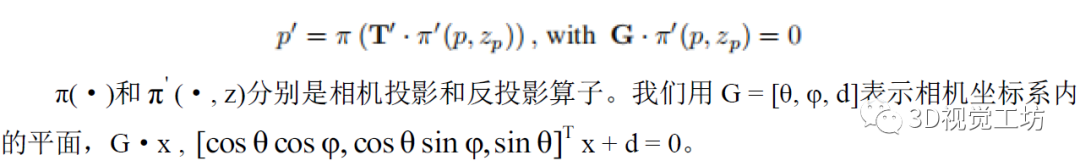
我们使用匈牙利匹配策略,在像素空间中以实例和像素的方式关联地面特征:1)在实例关联期间,我们计算交叉联合(IoU),对于常规物体的多边形和对于车道的5.0像素宽度的折线。2)在像素方面的关联中,我们计算其索引关键点的重投像素距离。IoU百分比<50%和像素距离>5.0的匹配被忽略。
对于在垂直物体(如电线杆)中检测到的关键点,我们使用光流方法进行帧间跟踪。在特征跟踪过程中,我们保留了由GFTT提取器和FREAK描述器提取、描述和跟踪的经典关键点,因为它们不仅是视觉-惯性测距的一部分,而且是值得纳入结构化物体的稳定跟踪的点特征。与输出掩码的分割不同,检测到的二维方框可能包含来自背景区域的GFTT特征关键点,特别是在极点实例中。因此,在II-F节讨论的状态初始化过程中,我们对这些背景特征关键点进行了离群剔除。
Representation and Initialization of Road Lanes

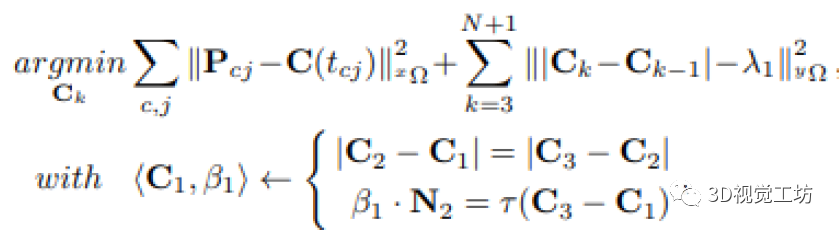
State Estimator Design
基于上述新的变量和每个图像帧C的原始帧位置TC,我们根据检测和跟踪的语义特征添加三种类型的约束包括:
1)Points observation factors:
我们倾向于像以前的方法一样,通过以下约束条件对常规关键点进行三角化和参数化。
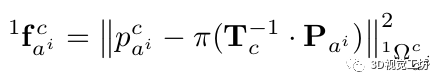
2)Spline observation factors:
我们使用下面的约束条件来动态地将样本和角点作为spline b的控制点的测量值。
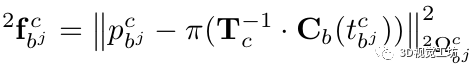
3)Coplanar prior factors:
垂直和水平共面先验都是通过以下形式的残差加入到优化中。
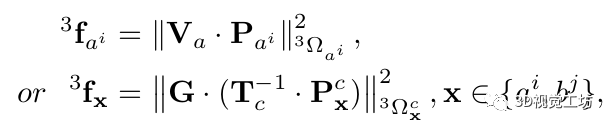
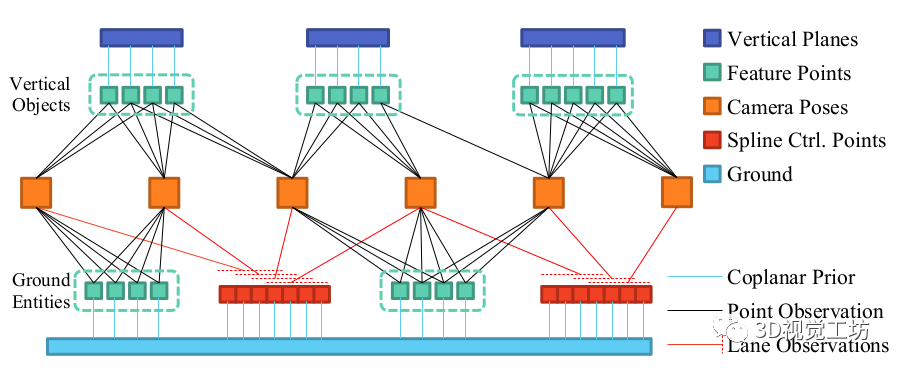
下图展示了这篇文章所构建的因子图,这篇文章针对场景中需要构建的各个不同种类的路标各自建立了不同的参数模型,并通过图优化的方式对各个路标进行状态更新。
Initialization of ground and pole objects:
下面介绍上述的5个参数模型的初始化方法:
1.当GNSS-VIO轨迹给定时,通过三角化特征点的方式获取位姿估计。
2.我们使用它们所包含的deep points在XOY平面上进行二维线拟合。
3.之后,如果没有检测到地面初始化的地面标志,我们就使用每一帧中检测到的车道凸包内的传统特征点,并应用RANSAC三维平面拟合策略来去除移动车辆上的关键点。
Inilization of splines:

Offline mapping case
在这些变量被初始化后,我们根据常见的视觉-惯性测距约束推导出一个因子图优化,为了数值稳定,在上述因子上添加了Cauchy损失函数,并将第一帧的位姿固定。所有的关键帧和检测到的实例都参与到最后的BA调整中,以共同解决位姿和位置问题。
Online localization case
在在线定位过程中,我们从语义地图中反序列化固定的语义地标,即spline的控制点和常规的三维点,并将它们固定在公式4和5中,以增加对摄像机和地图坐标之间的相对位置的约束。在这个阶段,不再需要像公式6那样的共面约束。我们将在第II-I节中进一步介绍这些因素是如何通过提议的地图查询策略构建的。
Re-Identification and Feature Merging
我们进行3D-3D关联来重新识别语义对象,而不是进行框架式的词包查询。原因是重复对象的密度(几十米)相对于测绘过程中GNSS-VIO测距的定位不确定性要稀疏一些,而且这些标准化的道路元素之间的视觉外观过于相似,无法区分。在实例化的物体和车道关联过程中,我们将其中心点之间的距离小于5.0米(或车道为0.5米)的三角形物体视为相同的物体,然后以匈牙利策略逐级合并其包含的深层点和经典点的观测结果。深层点的语义类型被用于拒绝不匹配。而对于每个伴随的GFTT点,我们使用它们在多帧中的FREAK描述符进行投票。我们使用union-find算法来合并它们的观察结果,并进行另一轮全局状态优化。
Data Structure of Semantic Maps
对于每个观测c,我们在全局坐标TC中存储其估计姿态,以及用于在线GPS查询的最近的GNSS测量。对于每个分层语义地标,我们存储语义标签和所包含的深度和GFTT点的三维位置。在我们的语义地图中,既不存储FREAK描述符,也不存储框架性描述符。
Localization Based on Semantic Maps
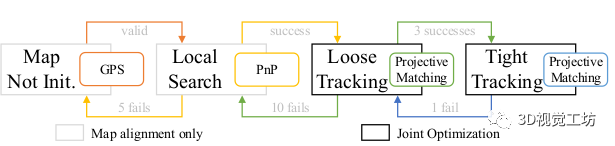
我们使用上图所示的状态机来评估在线定位的位姿质量,并相应地执行不同的策略。从地图未初始化的状态开始,在这个状态下,从地图坐标到当前全局坐标TM的全局变换是未知的,我们使用粗略的GPS测量来检索相应的地图分区,以获得相应的观测。
在局部搜索模式下,我们可以获得地标子集LM=G(OM),用于通过索引的深层物体关键点建立二维三维PnP-Ransac关联。要接受这样一个估计的PnP姿态是有效的,至少需要来自5个不同实例的12个传入点,以切换到两个跟踪状态并初始化TM。
我们使用两个阶段的跟踪状态,根据其位姿质量应用不同的阈值。在这两种跟踪状态下,重建的关联将通过公式4和5被添加到滑动窗口优化中,其中帧到全局变换的原始TC被帧到地图变换的TCM取代,而TM被视为优化过程中的一个额外的可优化变量。
在这样的两种跟踪模式中,我们将所有的地图实例投射到在线检测的帧c上,并使用以下标准,通过匈牙利式匹配接受投影关联,如。
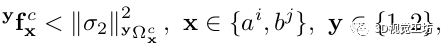
Experimental Evaluation
Datasets
本文所构建的系统在KAIST数据集以及作者自己录制的两个数据集上进行了测试。
Performance
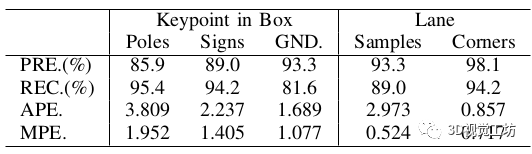
结果显示了我们训练的深度模型在KAIST数据集上的表现,由于它们在图像上的不同表现,盒子里的物体被分为三个有代表性的子类型(电线杆、交通标志和地面标志)。我们在测试集上分别评估这些任务,得出它们的分类精度、检测召回率,另外,表中的提取像素误差,下图为像素误差的分布直方图。

Evaluations on Localization and Mapping
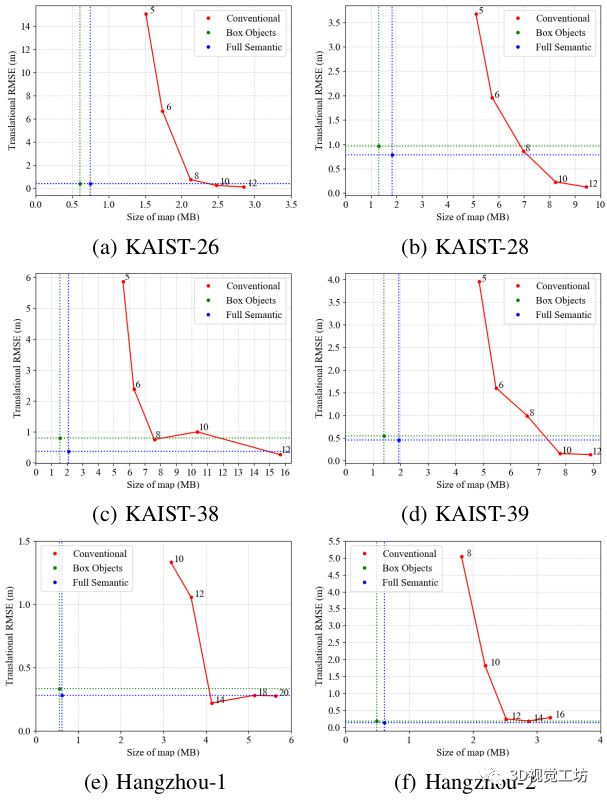
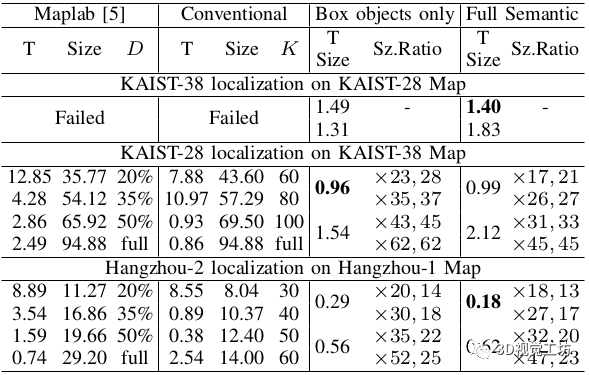
在这个测试中,我们对每个序列运行两次,分别进行测绘和地图辅助定位。图7列出了测试序列的结果。我们提出的方法所产生的语义图需要的文件大小要少得多,同时提供了有竞争力的定位性能。例如,KAIST-38的语义地图占据了1.54MB的磁盘空间来达到0.46米的定位精度,而传统的地图在设置K=8时需要7.60MB来达到0.75米。对杭州序列的测试也反映了同样的趋势。总的来说,我们提出的方法中的语义图要比那些设定的覆盖点特征图小近5倍,才能达到类似的定位性能。
Cross-Relocalization
下表显示了这种对等的交叉定位结果。可以看出,我们提出的含有方框物体和道路车道的语义地图的方法在所有交叉验证测试中都完成了成功的定位。对于传统地图,我们用包括全尺寸地图在内的多种设置进行测试。不幸的是,由于在不同季节和时间段捕获的视觉特征的严重变化,在28序列的地图上运行KAIST-38序列的定位始终失败。因此,集合覆盖稀疏化需要应用更大的K值来进行交叉重定位,以保持足够可靠的特征。对于Maplab来说,由于保留的信息量大的三维点通常与更多的局部视觉描述符有关,因此结果的地图大小比预期的要大。相比之下,我们提出的方法依赖于从标准化和持久化的道路元素中提取的深层特征。总之,这种语义替换在交叉定位上比传统地图和Maplab都有更大的优势,对杭州序列的实验也反映了同样的趋势,这表明在紧凑性和定位精度上都有优势。
Modular and Efficiency Analysis
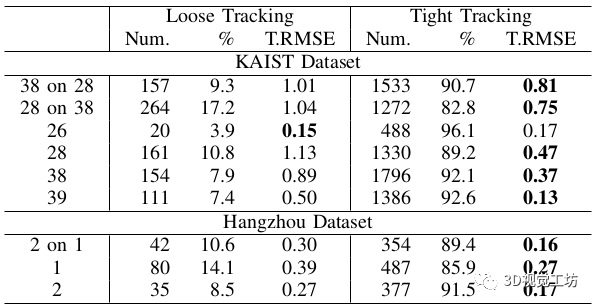
下表表示我们的定位所涉及的两种跟踪状态的统计数据。在大多数情况下,我们的方法在紧密跟踪模式下运行,这反映了更好的定位精度。
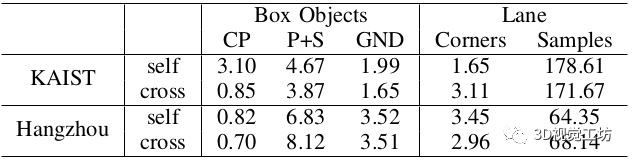
下表显示了来自不同语义实例的平均用点数量。由于相机可以观察和检测到比地面物体相对较远的有效的电线杆和标志物,这些物体对定位的贡献最大。
我们还分析了不同定位模式下语义对象关联的时间消耗。在在线定位期间,感知和地图查询模块都在一个独立的线程中运行。在感知模块中,如果单独检测,车道需要17.6毫秒/693MB,车道线检测需要7.5毫秒/422MB,其他物体和关键点检测需要17.3毫秒/1177MB。在地图查询模块中,本地搜索模式的平均时间消耗约为300毫秒,而对于占主导地位的松耦合跟踪或紧耦合跟踪模式,它减少到不到1毫秒。总体时间消耗低于我们设计的定位查询频率(1Hz)。
Stability of Semantic Mapping
下表显示了经典和语义建图方法中的建图误差。这表明引入语义对象并不明显影响建图的质量

Conclusion
本文提出了一个语义建图和定位流程。包括电杆、标志和公路车道在内的实例被检测到并被参数化,以形成一个紧凑的语义图,从而实现高效和准确的定位。
备注:作者也是我们「3D视觉从入门到精通」特邀嘉宾:一个超干货的3D视觉学习社区
原创征稿
初衷
3D视觉工坊是基于优质原创文章的自媒体平台,创始人和合伙人致力于发布3D视觉领域最干货的文章,然而少数人的力量毕竟有限,知识盲区和领域漏洞依然存在。为了能够更好地展示领域知识,现向全体粉丝以及阅读者征稿,如果您的文章是3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、硬件选型、求职分享等方向,欢迎砸稿过来~文章内容可以为paper reading、资源总结、项目实战总结等形式,公众号将会对每一个投稿者提供相应的稿费,我们支持知识有价!
投稿方式
邮箱:vision3d@yeah.net 或者加下方的小助理微信,另请注明原创投稿。

▲长按加微信联系

▲长按关注公众号
最后
以上就是高贵戒指最近收集整理的关于利用稀疏的语义视觉特征进行道路建图和定位(ICRA2021)的全部内容,更多相关利用稀疏内容请搜索靠谱客的其他文章。







![[论文阅读]Road Mapping and Localization using Sparse Semantic Visual Features速读以下是精读部分](https://www.shuijiaxian.com/files_image/reation/bcimg18.png)
发表评论 取消回复