Beautifulsoup库:
就是Python的一个HTML的解析库,可以用它来方便地从网页中提取数据。借助网页的结构和属性等特性来解析网页。
解析器:
Beautiful Soup在解析时实际上依赖解析器,它除了支持Python标准库中的HTML解析器外,还支持一些第三方解析器(比如lxml)
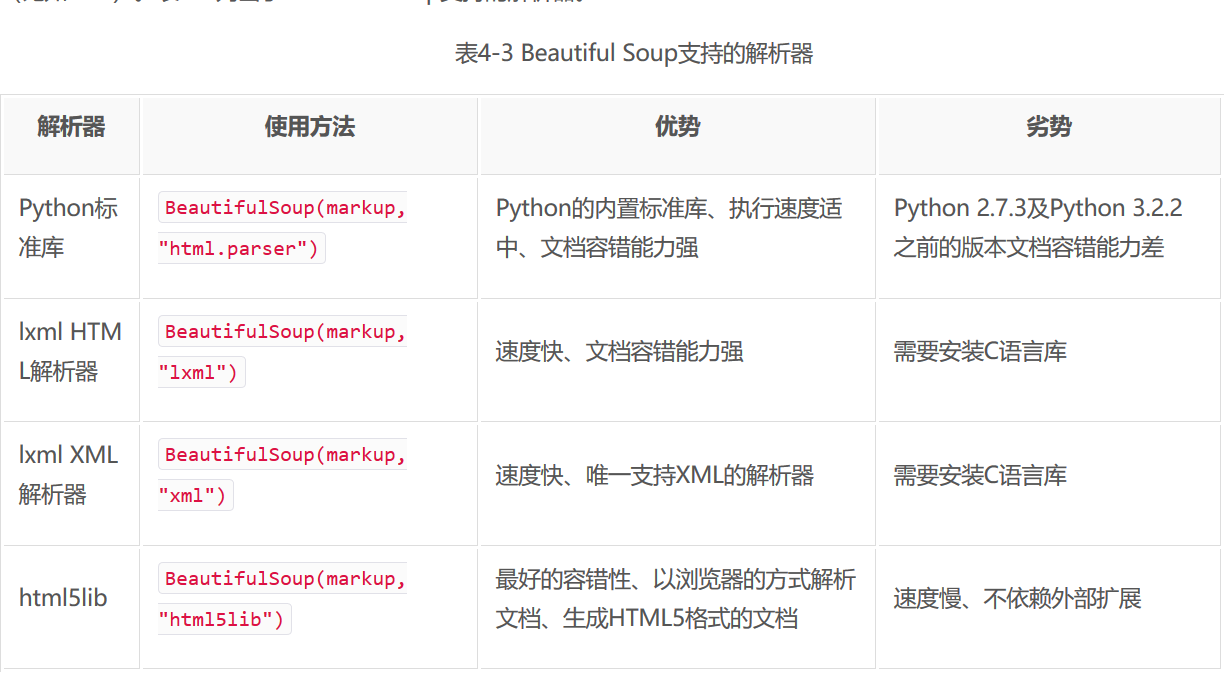
选择器:
1、节点选择器
2、方法选择器
3、css选择器
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
1)tag:HTML 中的一个个标签,两个重要的属性,name 和 attrs :
2)NavigableString:得到了标签的内容用 .string 即可获取标签内部的文字,会输出注释
3)BeautifulSoup:BeautifulSoup 对象表示的是一个文档的全部内容,是一个特殊的 Tag
4)Comment:Comment 对象是一个特殊类型的 NavigableString 对象,不会输出注释
其中,BeautifulSoup是Tag对象的具体化;Comment是Navigablestring对象的具体化。
1、BeautifulSoup的节点选择器:
直接调用节点的名称就可以选择节点元素,再调用string属性就可以得到节点内的文本了,这种选择方式速度非常快。如果单个节点结构层次非常清晰,可以选用这种方式来解析。
选择元素
|
提取信息:获取名称 获取属性 获取内容
|
嵌套选择:继续调用节点进行下一步的选择
|
关联选择:有时候不能做到一步就选到想要的节点元素,需要先选中某一个节点元素,然后以它为基准再选择 它的子节点、父节点、兄弟节点等。
实例;
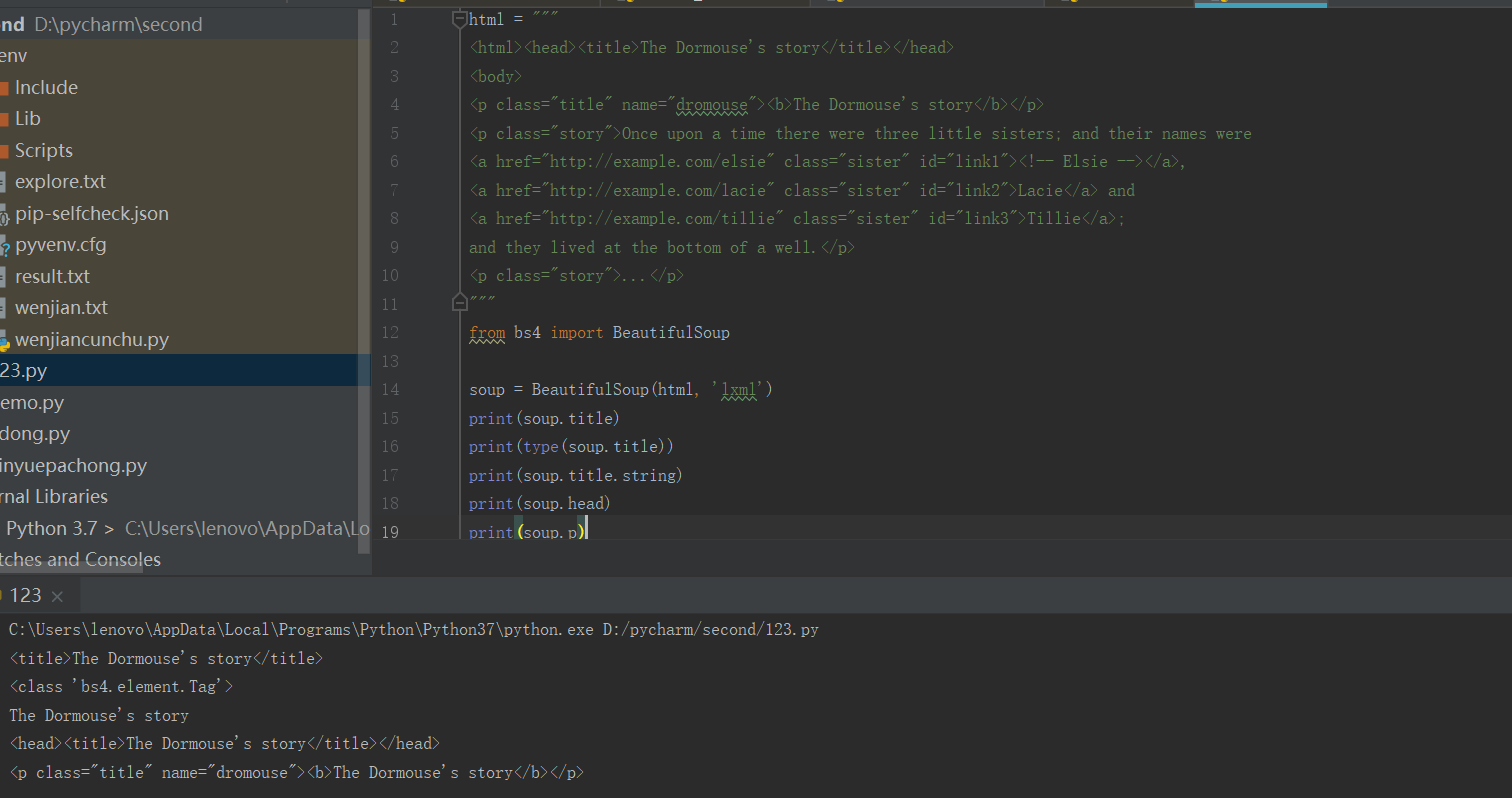 1)、打印输出title节点的选择结果,输出结果正是title节点加里面的文字内容
1)、打印输出title节点的选择结果,输出结果正是title节点加里面的文字内容
2)、输出它是bs4.element.Tag类型
3)、选择了p节点。不过这次情况比较特殊,我们发现结果是第一个p节点的内容,后面的几个p节点并没有选到。也就是说,当有多个节点时,这种选择方式只会选择到第一个匹配的节点,其他的后面节点都会忽略。
2、BeautifulSoup的方法选择器:
find_all(name , attrs , recursive , text , **kwargs)与find
name:根据节点名查询元素
attrs:根据节点属性查询元素
text:用来匹配节点的文本,传入的形式可以是字符串,可以是正则表达式对象
find_all,顾名思义,就是查询所有符合条件的元素。给它传入一些属性或文本,就可以得到符合条件的元素,它的功能十分强大。
实例:
1)、name我们可以根据节点名来查询元素,
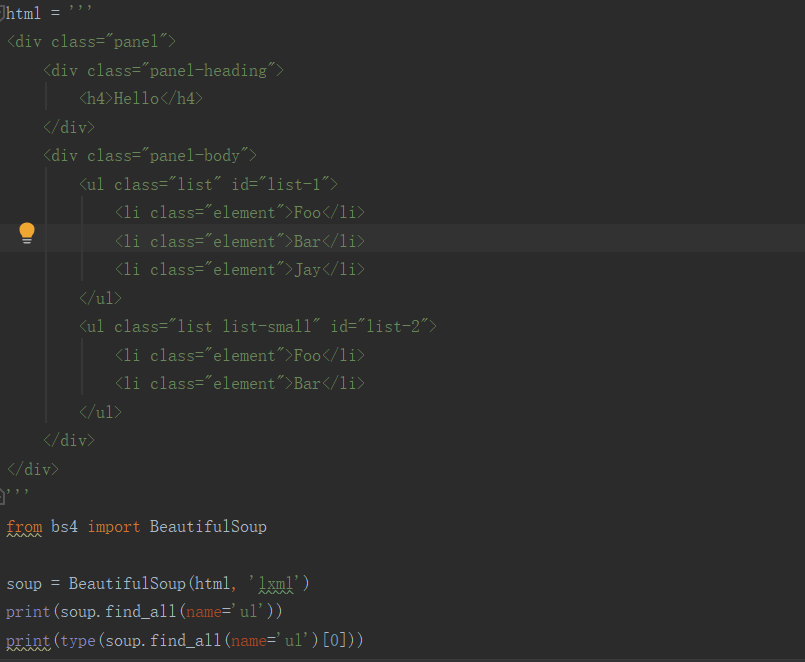
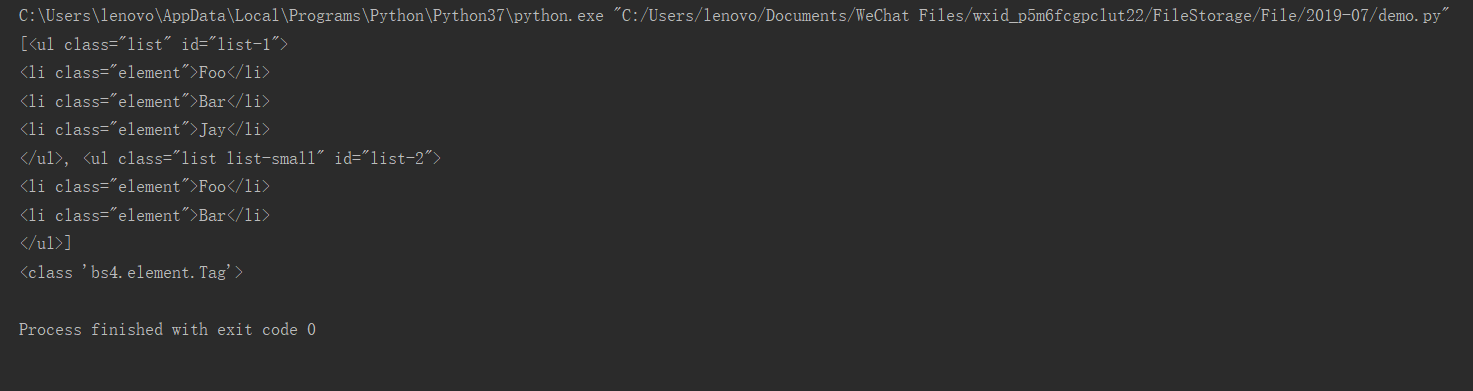 这里我们调用了find_all()方法,传入name参数,其参数值为ul。查询所有ul节点,返回结果是列表类型,长度为2,每个元素依然都是bs4.element.Tag类型。
这里我们调用了find_all()方法,传入name参数,其参数值为ul。查询所有ul节点,返回结果是列表类型,长度为2,每个元素依然都是bs4.element.Tag类型。
2)、attrs节点名查询,我们也可以传入一些属性来查询,示例如下:
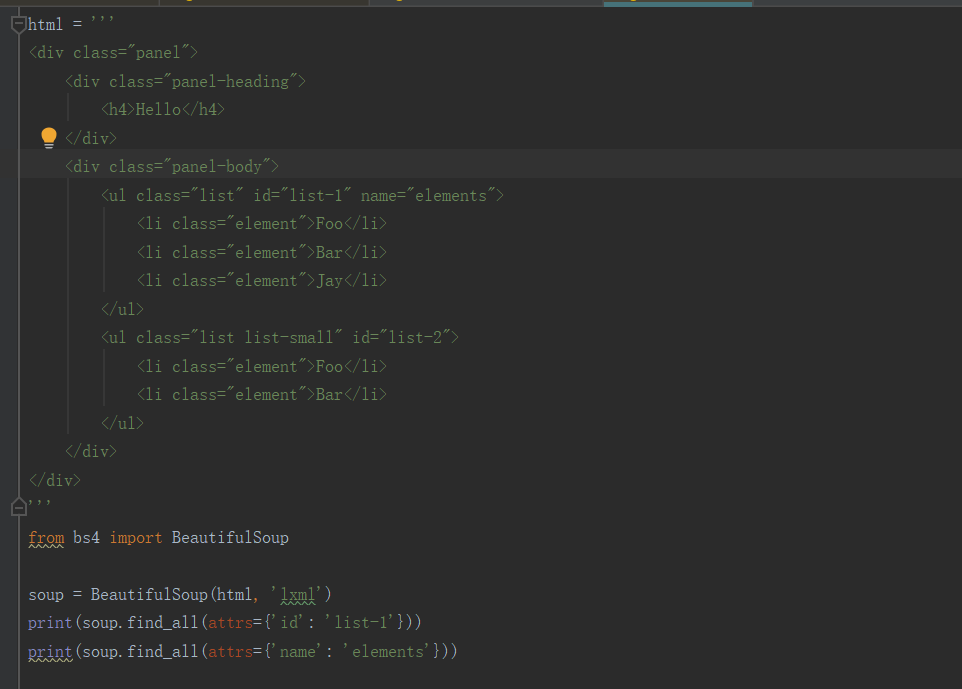
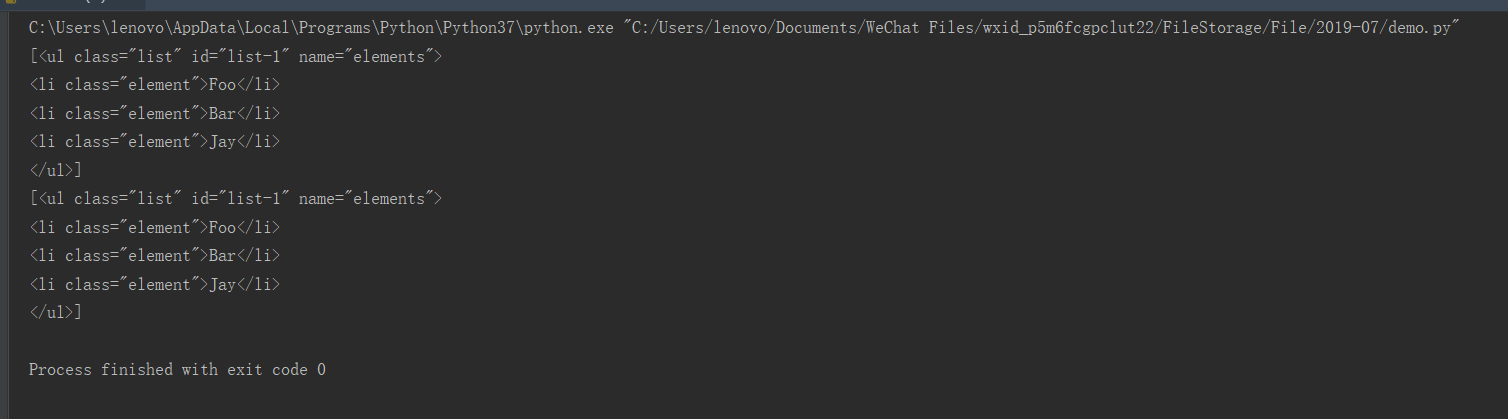 查询的时候传入的是attrs参数,参数的类型是字典类型.查询id为list-1的节点,可以传入attrs={‘id’: ‘list-1’}的查询条件,得到的结果是列表形式,包含的内容就是符合id为list-1的所有节点。在上面的例子中,符合条件的元素个数是1,所以结果是长度为1的列表。
查询的时候传入的是attrs参数,参数的类型是字典类型.查询id为list-1的节点,可以传入attrs={‘id’: ‘list-1’}的查询条件,得到的结果是列表形式,包含的内容就是符合id为list-1的所有节点。在上面的例子中,符合条件的元素个数是1,所以结果是长度为1的列表。
3、BeautifulSoup的css选择器:(比较难)
在 CSS中 ,标签名不加任何修饰,类名前加点,id名前加 #,在这里我们也可以利用类似的方法来筛选元素,用到的方法是 soup.select(),返回类型是 list。
通过标签名查找:
通过类名查找:
通过 id 名查找:
属性查找:
教程网址:https://blog.csdn.net/qq_21933615/article/details/81171951
或:http://www.w3school.com.cn/cssref/css_selectors.asp
- 创建 BeautifulSoup 对象
首先导入库 bs4 lxml requests
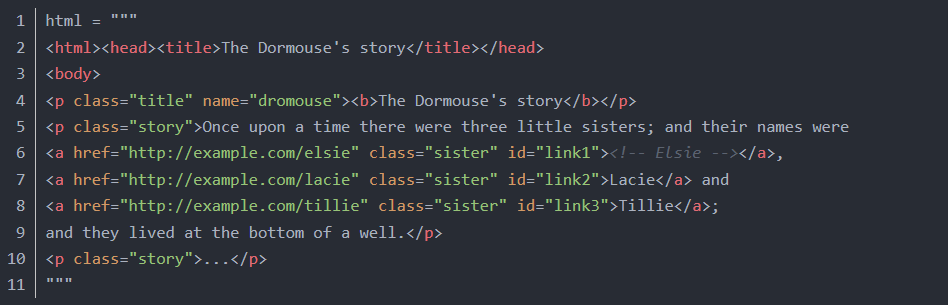
 网页代码:
网页代码:
创建 beautifulsoup 对象:

还可以用本地 HTML 文件来创建对象:

打印一下 soup 对象的内容,格式化输出:

文件存储
有三点:
1、TXT文件存储:
2、csv文件存储:
3、json数据:
1、TXT文件存储:
文件打开方式:
r:以只读方式打开文件。
rb:以二进制只读方式打开一个文件。
w:以写入方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。
wb:以二进制写入方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。
a:以追加方式打开一个文件。如果该文件已存在,文件指针将会放在文件结尾。也就是说,新的内容将会被 写入到已有内容之后。如果该文件不存在,则创建新文件来写入。
ab:以二进制追加方式打开一个文件。如果该文件已存在,则文件指针将会放在文件结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,则创建新文件来写入。
r+(读写)/rb+(二进制读写) w+/wb+ a+/ab+
实例:
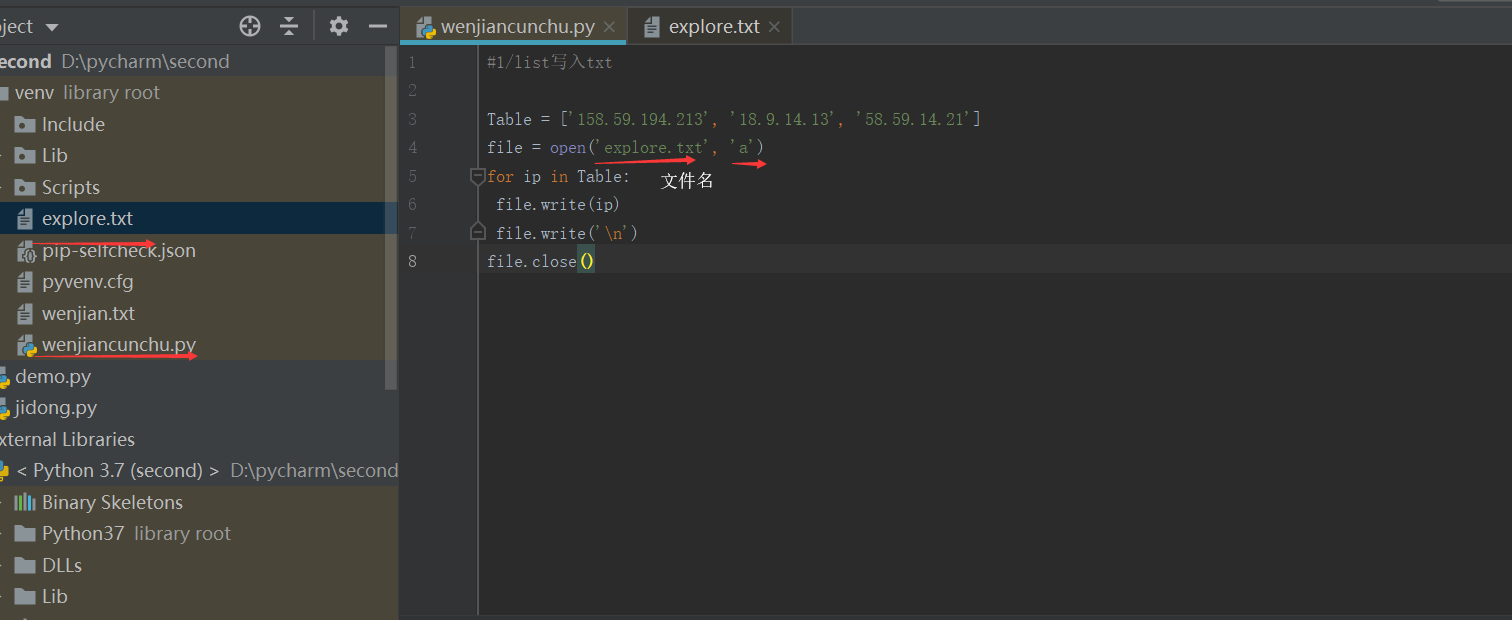
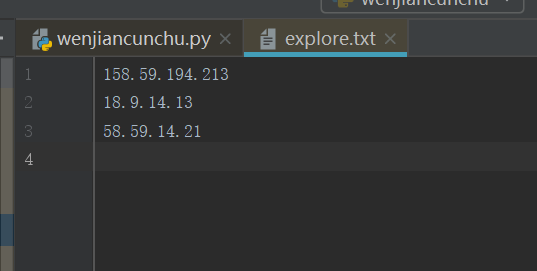 不错教程:https://cuiqingcai.com/5560.html
不错教程:https://cuiqingcai.com/5560.html
2、csv文件存储:
CSV,全称为Comma-Separated Values,中文可以叫作逗号分隔值或字符分隔值,其文件以纯文本形式存储表格数据。它比Excel文件更加简介,XLS文本是电子表格,它包含了文本、数值、公式和格式等内容,而CSV中不包含这些内容,就是特定字符分隔的纯文本,结构简单清晰,最广泛的应用是在程序之间转移表格数据。
CSV和excel的区别:
1).CSV是纯文本文件,excel不是纯文本,excel包含很多格式信息在里面。
2).CSV文件的体积会更小,创建分发读取更加方便,适合存放结构化信息
3、json数据:
jsob数据:JavaScript对象标记,通过对象和数组的组合来表示数据,构造简洁但是结构化程度非常高,是一种轻量级的数据交换格式
对象:使用花括号{}包裹起来的内容
数组:使用方括号[]包裹起来的内容
例:合天网安首页实验 http://www.hetianlab.com/onlineExperiment.jsp
jsob的读取:
Python为我们提供了简单易用的库来实现JSON文件的读写操作,我们可以调用库的loads()方法将JSON文本字符串转为JSON对象,可以通过dumps()方法将JSON对象转为文本字符串。
关于爬虫基础很详细:
https://cuiqingcai.com/tag/爬虫
最后
以上就是完美香菇最近收集整理的关于7.30--Python爬虫的Beautifulsoup库和文件存储的全部内容,更多相关7.30--Python爬虫内容请搜索靠谱客的其他文章。








发表评论 取消回复