Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.(下面用bs简称)
1.Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种
BeautifulSoup:将文档类型分成四种类型: Tag: 标签及其内容,只能拿到第一个 NavigableString:标签里的内容(字符串) BeautifulSoup:表示整个文档 Comment注释,符号会自动替换掉,是一种特殊的NavigableString,注释符号自动去掉
2.
使用BeautifulSoup解析html文件,能够得到一个 BeautifulSoup 的对象,并能按照标准的缩进格式的结构输出:
"html.parser"是html的解析器
可以利用bs的方法简单浏览标签内容
bs.title(获取title) bs.title.name(获取title的名字) bs.title.string(获取title中的文本内容) soup.title.parent.name(获取title父母节点的名字)....类似还有点可以去看官方文档方法介绍
Beautiful Soup 4.4.0 文档 — Beautiful Soup 4.2.0 中文 文档
3.文档的搜索
操作文档树最简单的方法就是告诉它你想获取的tag的name.例如想获取 <head> 标签,只要用 soup.head 会返回第一个搜索到的目标,如果想要全部查询可以使用bs.findAll()
例如想要查询全部的<a>标签可以使用bs.findAll('a')做到
返回的类型为列表类型,可以使用for循环进行输出可以让格式整齐点
t_list=bs.findAll('a')
print(t_list)
这是不用for循环的格式:(太长了所以放到txt里看的直观一点)
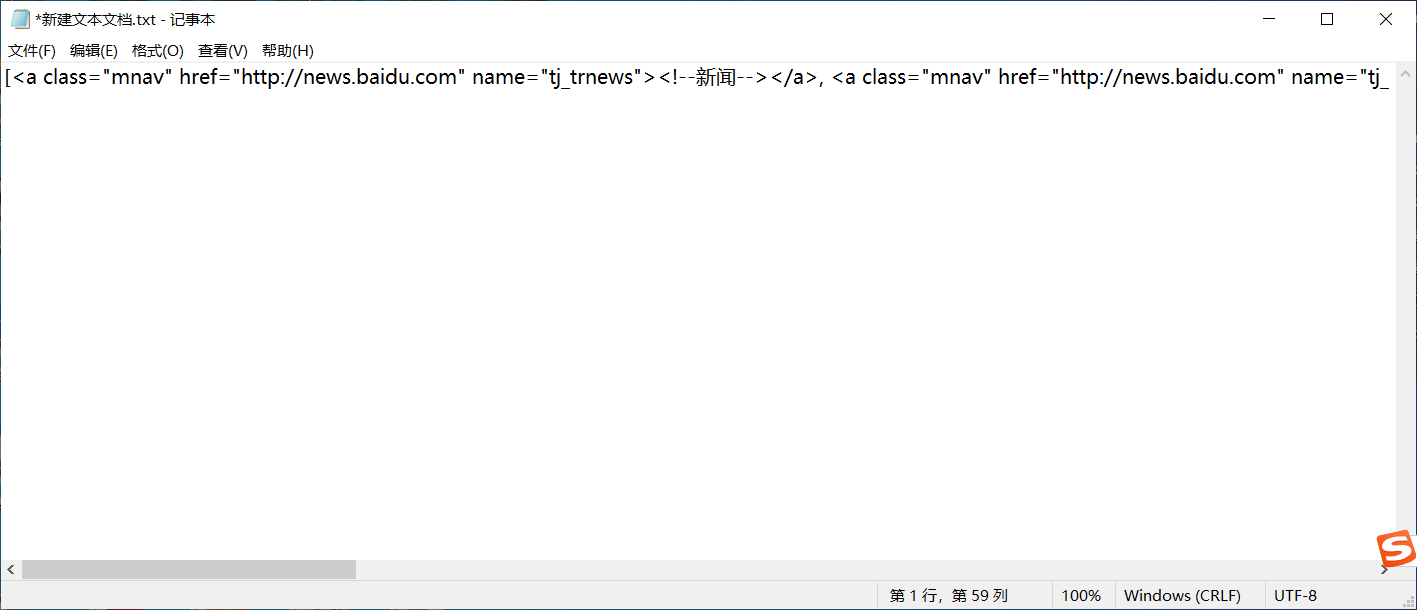
t_list=bs.findAll('a')
for item in t_list:
print(item)
这是使用了for循环的格式:

bs支持使用search进行正则化过滤,先写点简单的明天再写正则化
t_list=bs.findAll(re.compile('a'))
print(t_list)
方法搜索:传入一个方法(函数),根据函数的要求来搜索
例:
def name_is_exits(tag):
return tag.has_attr('name')
t_list=bs.findAll(name_is_exits)
for i in t_list:
print(i)
4.
kwargs 参数
# t_list=bs.findAll(calss=True)
# for i in t_list:
# print(i)
#文本参数
#t_list=bs.findAll(text=['hao123','贴吧','地图'])
#t_list=bs.findAll(text=re.compile(('d')))#所有的数字,正则表达式(标签里的字符串)
#limit参数 限制查找个数
# t_list=bs.findAll('a',limit=3)
# for i in t_list:
# print(i)
#css选择器
# t_list=(bs.select('title')) 通过标签来查找
# t_list=bs.select('.mnav') 通过类名来查找
#t_list=bs.select('#u1') 通过id来查找
# t_list=bs.select('a[class="bri"]') 通过属性来查找
# t_list=bs.select('head>title') 通过子标签来查找
# t_list=bs.select('.mnav~.bri')
# # print(t_list[0].get_text()) 兄弟节点
# for i in t_list:
# print(i)
先粘着有时间再来补充
最后
以上就是整齐乐曲最近收集整理的关于BeautifulSoup整理的全部内容,更多相关BeautifulSoup整理内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复