1.为什么有这个想法:
最近想看一部连载小说,奈何没有现成资源,网页一章一章看广告又太烦,于是乎用python beautifulsoup4 代码爬虫爬取文章的想法就应运而生了
2.软件环境:
python 3.7
Beautifulsoup 4.7.1
requests 2.21.0
pycharm 2018.3.2
3.思路分析
先抓取一篇文章的标题与正文内容,之后抓取目录链接,在目录的循环了执行每篇文章的抓取,最后将文章存成txt。
4.代码:
import requests
from bs4 import BeautifulSoup
import os
import time
def getcontent(url):
html=requests.get(url)
html.encoding='UTF-8'
soup=BeautifulSoup(html.text,'html.parser')
title=soup.select('.bookname h1')
print(title[0].text)
re1=title[0].text
content=soup.select('#content')
result=content[0].text
print(str(result).strip().replace(' ','n'))
re2=str(result).strip().replace(' ','n')
with open(os.path.join(os.getcwd(),'凡人修仙传之仙界篇.txt'),'a+',encoding='utf-8') as f:
f.write(re1+'n'+re2+'rn')
def getallurl():
result=[]
url='https://www.biquke.com/bq/0/990/'
html=requests.get(url)
html.encoding='utf-8'
soup=BeautifulSoup(html.text,'html.parser')
re=soup.select('#list a')
for i in re:
# print(i['href'])
result.append(i['href'])
return result
if __name__ == '__main__':
# url='https://www.biquke.com/bq/0/990/4368042.html'
# getcontent(url)
# url='https://www.biquke.com/bq/0/990/4374212.html'
# getcontent(url)
# url='https://www.biquke.com/bq/0/990/4375800.html'
# getcontent(url)
allpageurl=getallurl()
for i in allpageurl:
url='https://www.biquke.com/bq/0/990/'+i
getcontent(url)
time.sleep(1)
print('='*50)
print('文章截取完毕')
print('='*50)
5.效果截图:
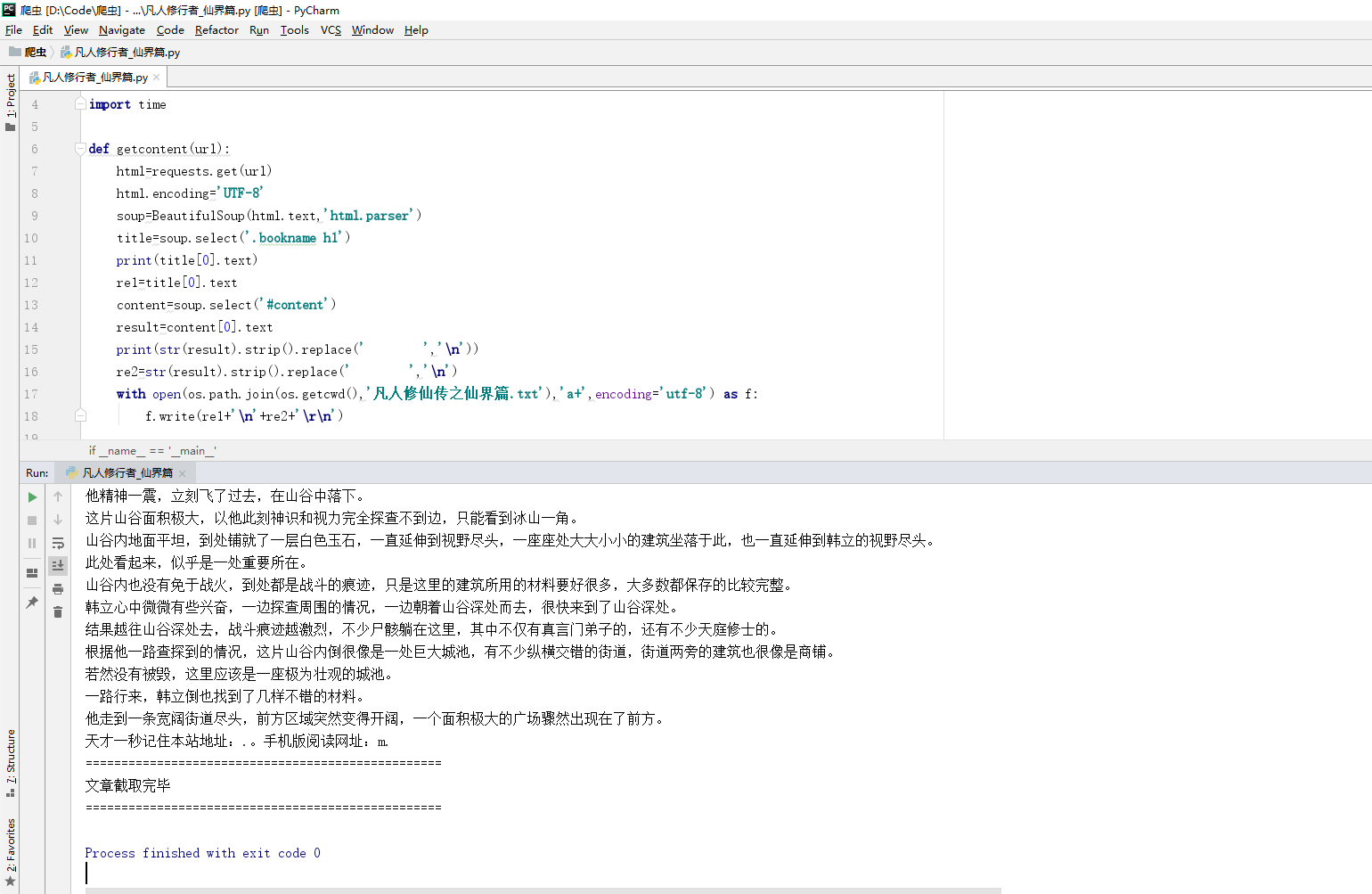

6.心得:
爬虫越来越得心应手了,基础是关键,从局部到整体,思路一定要清晰,先打印到控制台,没问题再存成本地文件。
最后
以上就是坦率鱼最近收集整理的关于python Beautifulsoup4爬取凡人修仙传仙界篇连载中文章并生成txt的全部内容,更多相关python内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复