Filebeat 是一款轻量级的日志采集器,可以用来收集日志,并将日志汇总起来处理。
Filebeat 的工具原理如下图所示:
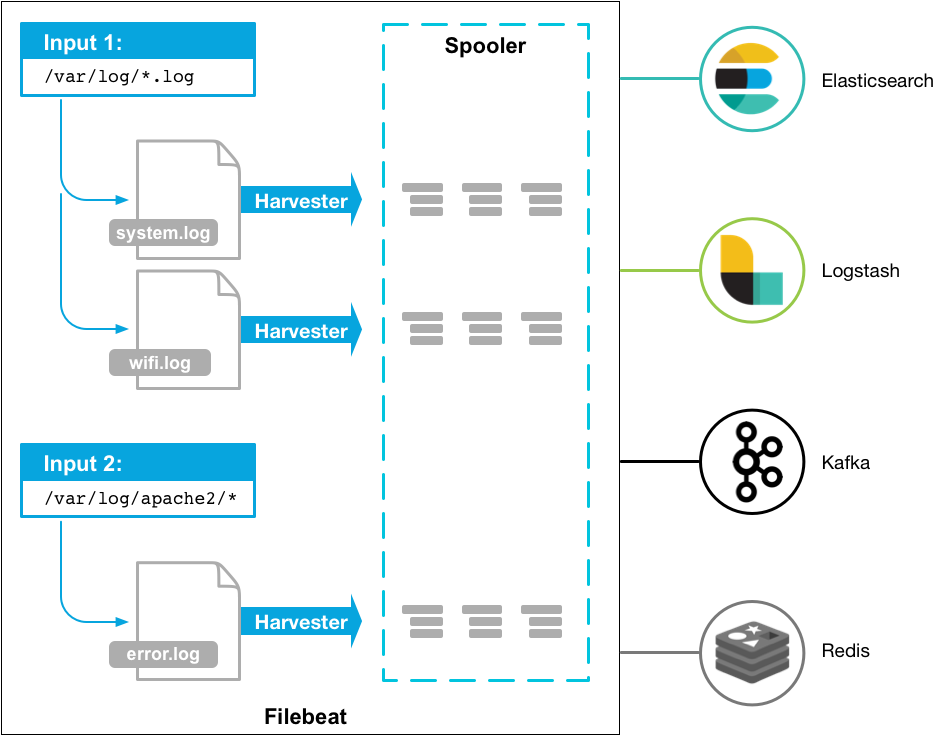
图片来源:
https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-overview.html
通过 filebeat 配置文件 filebeat.yml 指定需要收集的日志,并可以指定日志输出至 elasticsearch,logstash,kafka,redis 等下游接收系统。
本文讲述如何配置 filebeat,将日志输出至 kafka 集群。
安装 filebeat
为方便使用,我们采用 docker 方式安装 filebeat。
采用 filebea 官方镜像 docker.elastic.co/beats/filebeat:7.7.1,docker-compose.yml 配置如下:
version: '3'
services:
filebeat:
image: docker.elastic.co/beats/filebeat:7.7.1
container_name: filebeat
restart: always
volumes:
- /home/lihao/code/server/logs:/home/lihao/code/server/logs
- /home/lihao/docker/filebeat/filebeat.yml:/usr/share/filebeat/filebeat.yml:ro
- /var/lib/docker/containers:/var/lib/docker/containers:ro
- /var/run/docker.sock:/var/run/docker.sock:ro
其中 volumes 的配置,第一行是指定需要收集日志的目录,第二行是指定 filebeat 的配置文件,第三、第四行是参考官方文档添加的配置,详细可参考 https://www.elastic.co/guide/en/beats/filebeat/current/running-on-docker.html。
配置 filebeat
配置 filebeat 的输出,以便收集日志:
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /home/lihao/code/server/logs/*.log
上述配置中,指定收集的日志文件为 /home/lihao/code/server/logs 目录下的 .log 文件。
配置日志输出至 kafka 集群:
output.kafka:
hosts: ["10.88.115.137:9095", "10.88.115.137:9096", "10.88.115.137:9097"]
topic: kafka_log
partition.round_robin:
reachable_only: true
kafka 集群地址为10.88.115.137:9095, 10.88.115.137:9096, 10.88.115.137:9097 ,kafka 和 topic 名称为 kafka_log。
Filebeat 提供多种输出至 kafka 分区的策略,包括 random,round_robin,hash,默认是 hash。上面的配置中,我们指定 round_robin 的策略,并指定 reachable_only 为 true,这表示仅将日志发布到可用分区。
设置好 kafka 分区策略后,后面我们可以通过设置 kafka topic 和 consumer 的数量,以实现负载均衡。
完成 filebeat.yml 配置后,我们使用命令启动 filebeat 容器。
docker-compose up -d
测试
启动 kafka consumer 测试程序,以测试从 kafka 接收日志。
from kafka import KafkaConsumer
consumer = KafkaConsumer('kafka_log', group_id="monitor_group1", bootstrap_servers=["10.88.115.137:9095", '10.88.115.137:9096', '10.88.115.137:9097'])
for msg in consumer:
print(msg.value)
然后往目录 /home/lihao/code/server/logs 写入日志,命令:
cd /home/lihao/code/server/logs
echo "hello" >> ksb.log
可以看到 consumer 程序输出:
… “message”:“hello” …
使用 kafka 命令可以查看到 topic 的 partition 数量(有关命令可以参考文章《
Kafka 生产者和消费者学习笔记》):
bin/kafka-topics.sh --describe --zookeeper 10.88.115.137:2181 --topic kafka_log
Topic kafka_log 的 partition 数量为 1。为实现负载均衡,设置 kafka_log 的 partition 数量为 2:
bin/kafka-topics.sh --zookeeper 10.88.115.137:2181 --alter --topic kafka_log --partitions 2
打开终端,同时启动两个 kafka consumer 测试程序。然后,修改 partition 数量后,再次执行:
cd /home/lihao/code/server/logs
echo "hello1" >> ksb.log
echo "hello2" >> ksb.log
可以看到其中一个 kafka consumer 测试程序输出:
… “message”:“hello1” …
另一个 kafka consumer 测试程序输出:
… “message”:“hello2” …
不断执行上面的 echo 命令,可以看到 kafka consumer 测试程程序交替地输出接收到的日志。
在我们的生产环境,通过 prometheus 收集 kafka consumer 的 cpu 占用情况,可以看到生产环境上 3 个 kafka consumer 的负载基本一致,这也验证了 filebeat 的 partition.round_robin: 配置在实现负载均衡的作用。
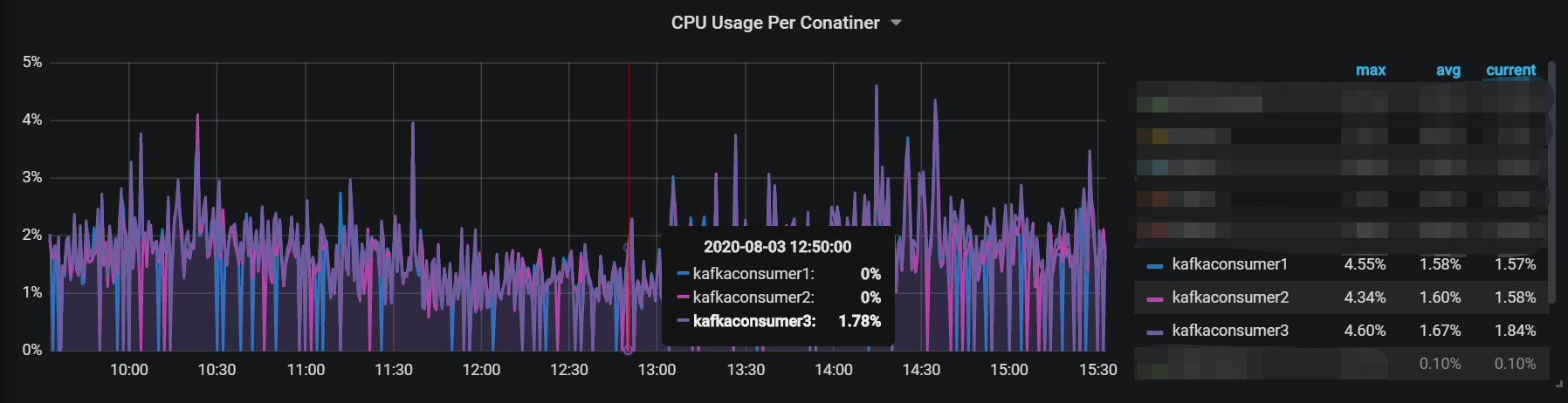
参考资料
- https://www.elastic.co/cn/beats/filebeat
- https://www.elastic.co/guide/en/beats/filebeat/current/kafka-output.html
- https://www.jianshu.com/p/229c01447e54
- https://www.elastic.co/guide/en/beats/filebeat/current/running-on-docker.html
- https://www.zhihu.com/question/28925721
最后
以上就是高高水杯最近收集整理的关于Filebeat 日志输出至 Kafka的全部内容,更多相关Filebeat内容请搜索靠谱客的其他文章。








发表评论 取消回复