1、应用场景分析
参考徐崴老师Flink项目
- 数据清洗【实时ETL】
- 数据报表
1.1、数据清洗【实时ETL】
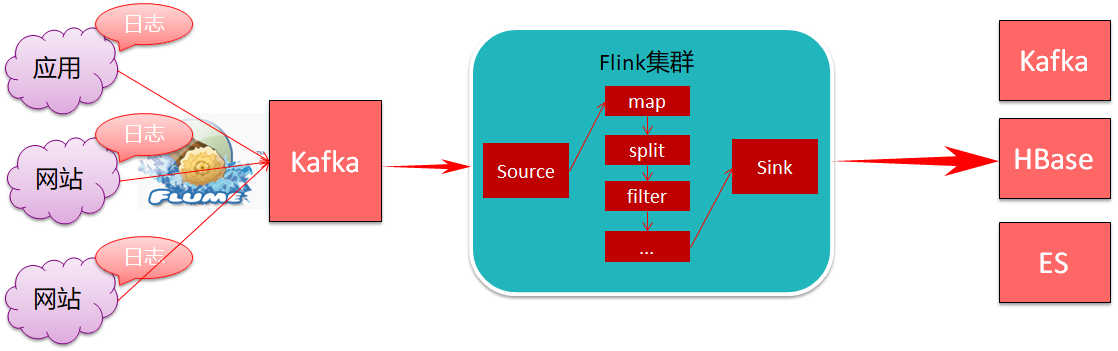
1.1.1、需求分析
针对算法产生的日志数据进行清洗拆分
- 算法产生的日志数据是嵌套大JSON格式(json嵌套json),需要拆分打平
- 针对算法中的国家字段进行大区转换
- 最后把不同类型的日志数据分别进行存储
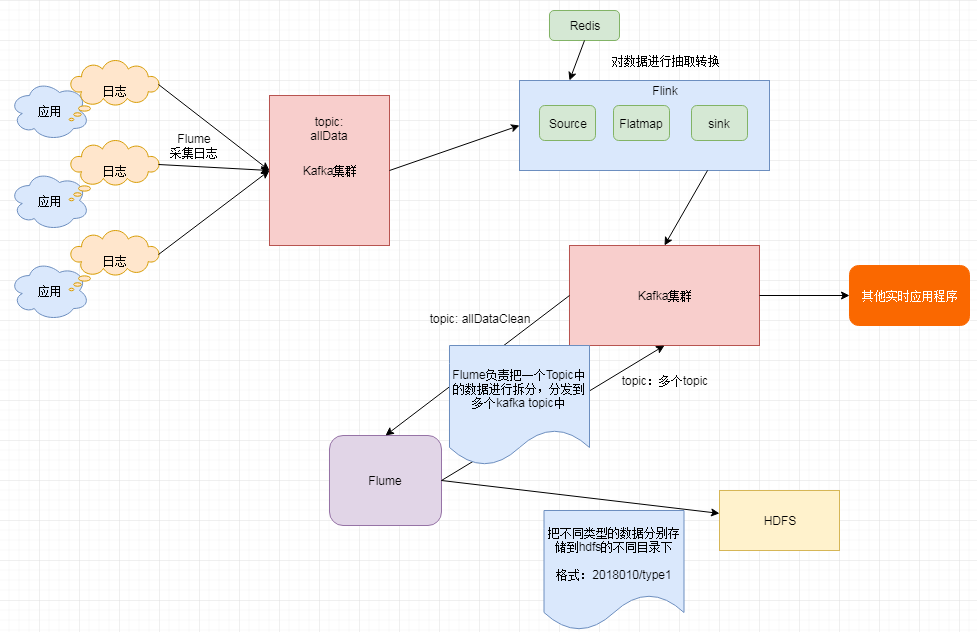
1.1.2、架构图
1.2、新建项目工程
创建一个大的项目,用Maven来维护
每个flink需求,即job创建一个 ”Module”
第一步:
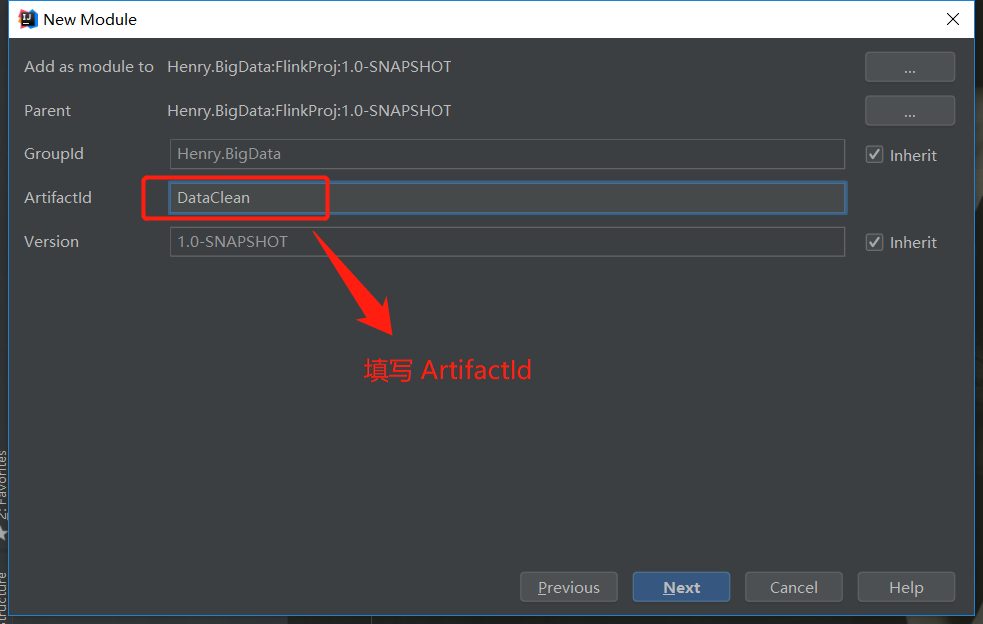
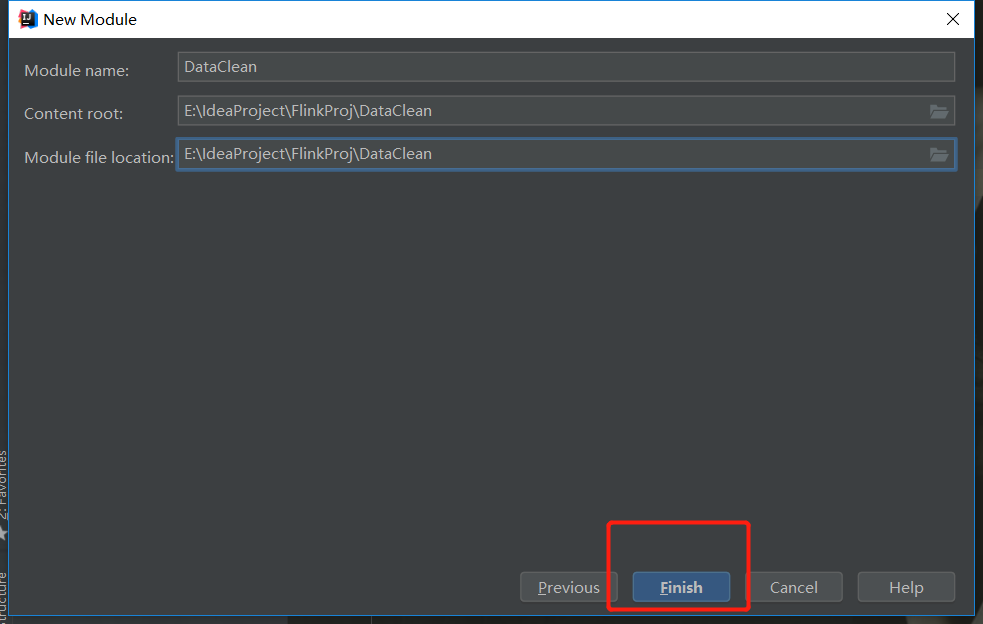
第二步:
在工程项目pom.xml中添加依赖管理,在其中管理各个需求子项目的依赖版本
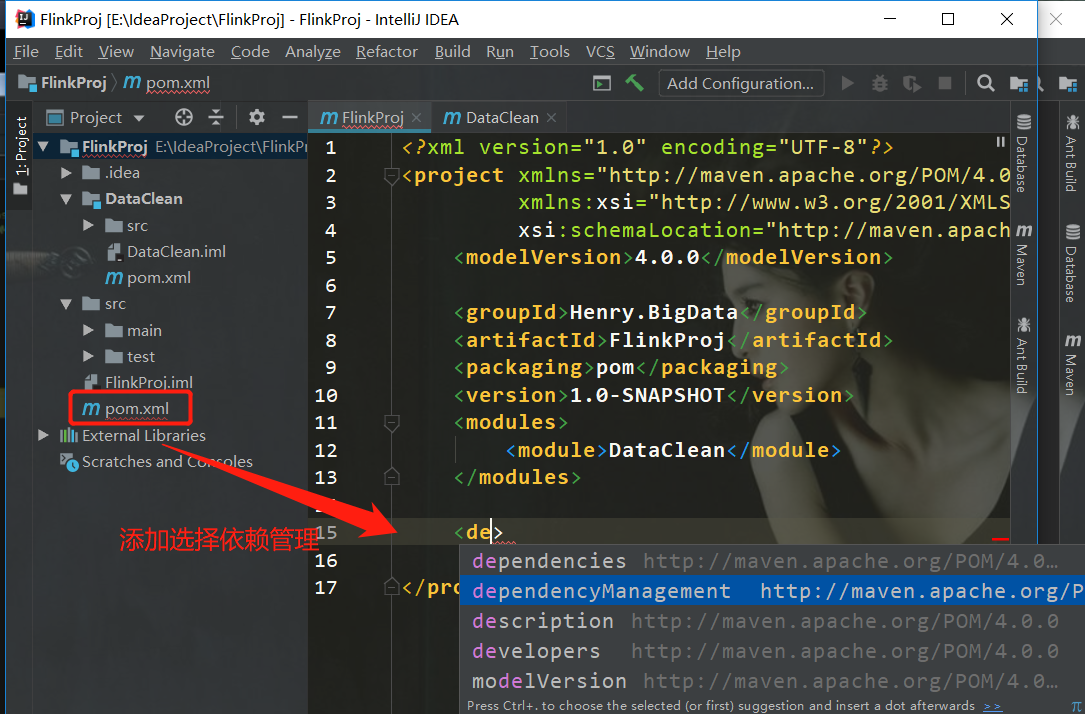
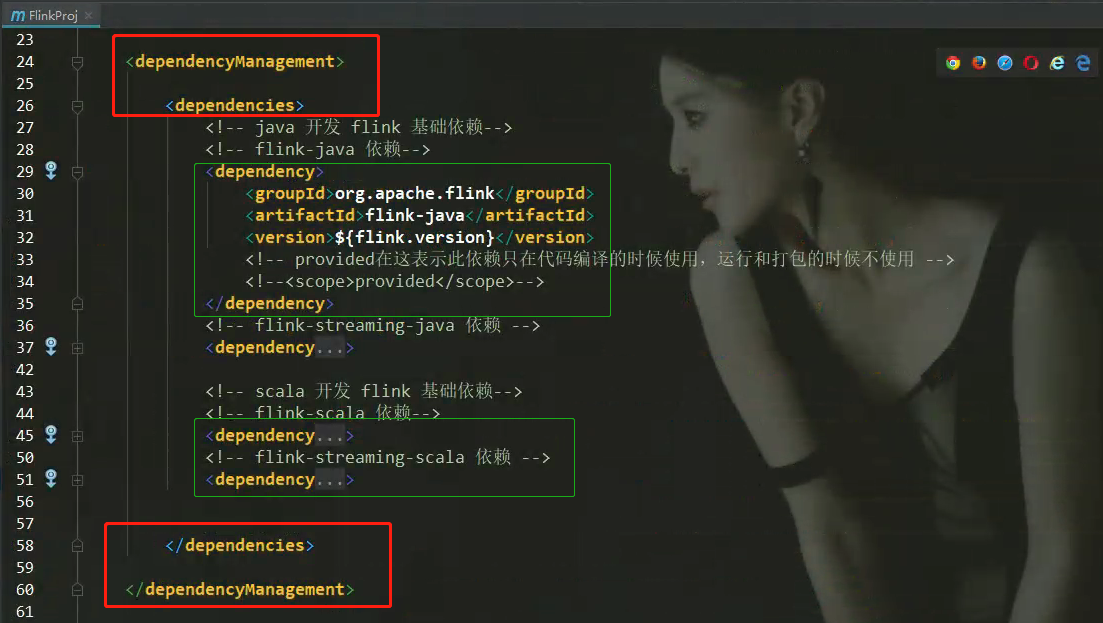
在依赖管理中添加工程项目相关依赖:
第三步:
在DataClean module中的pom.xml中添加依赖(不需要加入版本):
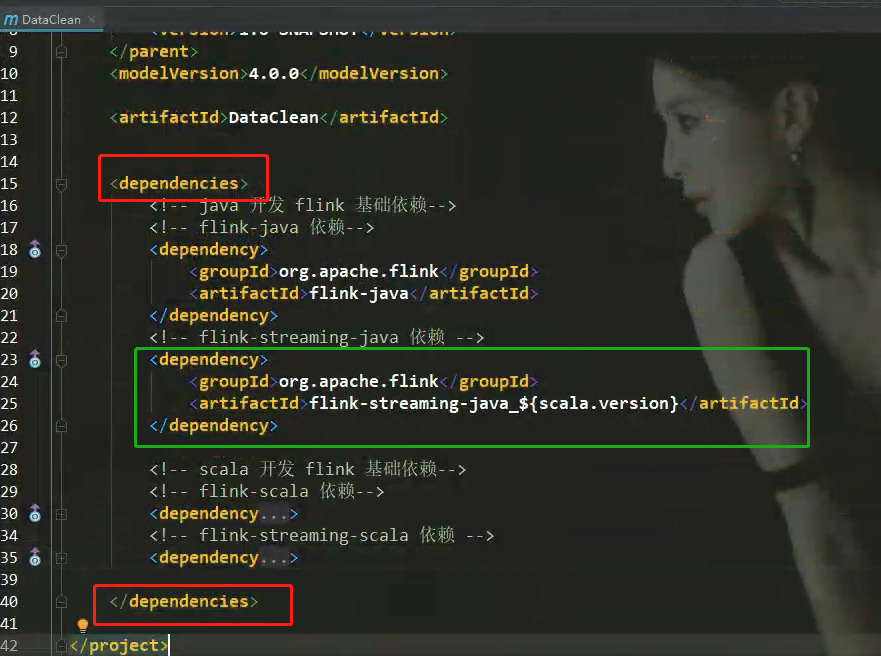
2、DataClean代码开发
开发介绍采用的是 Java 代码实现的,完整工程代码及 Scala 代码的实现详见底部 GitHub 代码地址
2.1、MyRedisSource实现
功能: 自定义 Redis Source
由于存储的是 国家大区和编码的映射关系
类似于 k-v ,所以返回 HashMap 格式比较好
在 Redis 中保存的国家和大区的关系
Redis中进行数据的初始化,数据格式:
Hash 大区 国家
hset areas; AREA_US US
hset areas; AREA_CT TW,HK
hset areas AREA_AR PK,SA,KW
hset areas AREA_IN IN
需要把大区和国家的对应关系组装成 java 的 hashmap
代码:
package henry.flink.customSource;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.exceptions.JedisConnectionException;
import java.util.HashMap;
import java.util.Map;
/**
* @Author: Henry
* @Description: 自定义 Redis Source
* 由于存储的是 国家大区和编码的映射关系
* 类似于 k-v ,所以返回 HashMap 格式比较好
* 需要把大区和国家的对应关系组装成 java 的 hashmap
*
* @Date: Create in 2019/5/25 18:12
**/
public class MyRedisSource implements SourceFunction<HashMap<String,String>>{
private Logger logger = LoggerFactory.getLogger(MyRedisSource.class);
private final long SLEEP_MILLION = 60000 ;
private boolean isrunning = true;
private Jedis jedis = null;
public void run(SourceContext<HashMap<String, String>> ctx) throws Exception {
this.jedis = new Jedis("master", 6379);
// 存储所有国家和大区的对应关系
HashMap<String, String> keyValueMap = new HashMap<String, String>();
while (isrunning){
try{
// 每次执行前先清空,去除旧数据
keyValueMap.clear();
// 取出数据
Map<String, String> areas = jedis.hgetAll("areas");
// 进行迭代
for (Map.Entry<String, String> entry : areas.entrySet()){
String key = entry.getKey(); // 大区:AREA_AR
String value = entry.getValue(); // 国家:PK,SA,KW
String[] splits = value.split(",");
for (String split : splits){
// 这里 split 相当于key, key 是 value
keyValueMap.put(split, key); // 即 PK,AREA_AR
}
}
// 防止取到空数据
if(keyValueMap.size() > 0){
ctx.collect(keyValueMap);
}
else {
logger.warn("从Redis中获取到的数据为空!");
}
// 一分钟提取一次
Thread.sleep(SLEEP_MILLION);
}
// 捕获 Jedis 链接异常
catch (JedisConnectionException e){
// 重新获取链接
jedis = new Jedis("master", 6379);
logger.error("Redis链接异常,重新获取链接", e.getCause());
}// 捕获其他异常处理,通过日志记录
catch (Exception e){
logger.error("Source数据源异常", e.getCause());
}
}
}
/**
* 任务停止,设置 false
* */
public void cancel() {
isrunning = false;
// 这样可以只获取一次连接在while一直用
if(jedis != null){
jedis.close();
}
}
}
2.2、DataClean实现
主要代码:
// 指定 Kafka Source
String topic = "allData";
Properties prop = new Properties();
prop.setProperty("bootstrap.servers", "master:9092");
prop.setProperty("group.id", "con1");
FlinkKafkaConsumer011<String> myConsumer = new FlinkKafkaConsumer011<String>(
topic, new SimpleStringSchema(),prop);
// 获取 Kafka 中的数据,Kakfa 数据格式如下:
// {"dt":"2019-01-01 11:11:11", "countryCode":"US","data":[{"type":"s1","score":0.3},{"type":"s1","score":0.3}]}
DataStreamSource<String> data = env.addSource(myConsumer); // 并行度根据 kafka topic partition数设定
// mapData 中存储最新的国家码和大区的映射关系
DataStream<HashMap<String,String>> mapData = env.addSource(new MyRedisSource())
.broadcast(); // 可以把数据发送到后面算子的所有并行实际例中进行计算,否则处理数据丢失数据
// 通过 connect 方法将两个数据流连接在一起,然后再flatMap
DataStream<String> resData = data.connect(mapData).flatMap(
//参数类型代表: data , mapData , 返回结果; Json
new CoFlatMapFunction<String, HashMap<String, String>, String>() {
// 存储国家和大区的映射关系
private HashMap<String, String> allMap = new HashMap<String, String>();
// flatMap1 处理 Kafka 中的数据
public void flatMap1(String value, Collector<String> out)
throws Exception {
// 原数据是 Json 格式
JSONObject jsonObject = JSONObject.parseObject(value);
String dt = jsonObject.getString("dt");
String countryCode = jsonObject.getString("countryCode");
// 获取大区
String area = allMap.get(countryCode);
// 迭代取数据,jsonArray每个数据都是一个jsonobject
JSONArray jsonArray = jsonObject.getJSONArray("data");
for (int i = 0; i < jsonArray.size(); i++) {
JSONObject jsonObject1 = jsonArray.getJSONObject(i);
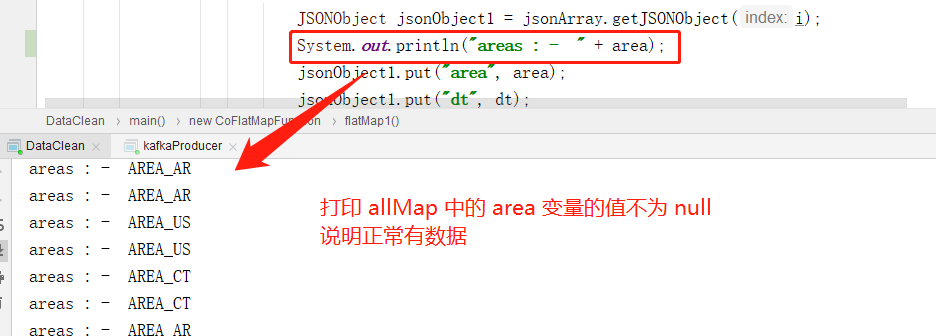
System.out.println("areas : - " + area);
jsonObject1.put("area", area);
jsonObject1.put("dt", dt);
out.collect(jsonObject1.toJSONString());
}
}
// flatMap2 处理 Redis 返回的 map 类型的数据
public void flatMap2(HashMap<String, String> value, Collector<String> out)
throws Exception {
this.allMap = value;
}
});
String outTopic = "allDataClean";
Properties outprop= new Properties();
outprop.setProperty("bootstrap.servers", "master:9092");
//设置事务超时时间
outprop.setProperty("transaction.timeout.ms",60000*15+"");
FlinkKafkaProducer011<String> myproducer = new FlinkKafkaProducer011<>(outTopic,
new KeyedSerializationSchemaWrapper<String>(
new SimpleStringSchema()), outprop,
FlinkKafkaProducer011.Semantic.EXACTLY_ONCE);
resData.addSink(myproducer);
3、实践运行
3.1、Redis
启动redis:
- 先从一个终端启动redis服务
./redis-server
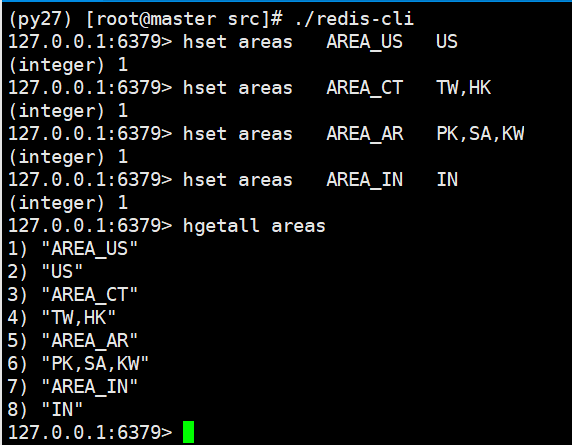
2. 先从一个终端启动redis客户端,并插入数据
./redis-cli
127.0.0.1:6379> hset areas AREA_US US
(integer) 1
127.0.0.1:6379> hset areas AREA_CT TW,HK
(integer) 1
127.0.0.1:6379> hset areas AREA_AR PK,SA,KW
(integer) 1
127.0.0.1:6379> hset areas AREA_IN IN
(integer) 1
127.0.0.1:6379>
hgetall查看插入数据情况:
3.2、Kafka
启动kafka:
./kafka-server-start.sh -daemon ../config/server.properties
jps查看启动进程:

kafka创建topc:
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 5 --topic allData
创建topic成功:

监控kafka topic:
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic allDataClean

3.3、启动程序
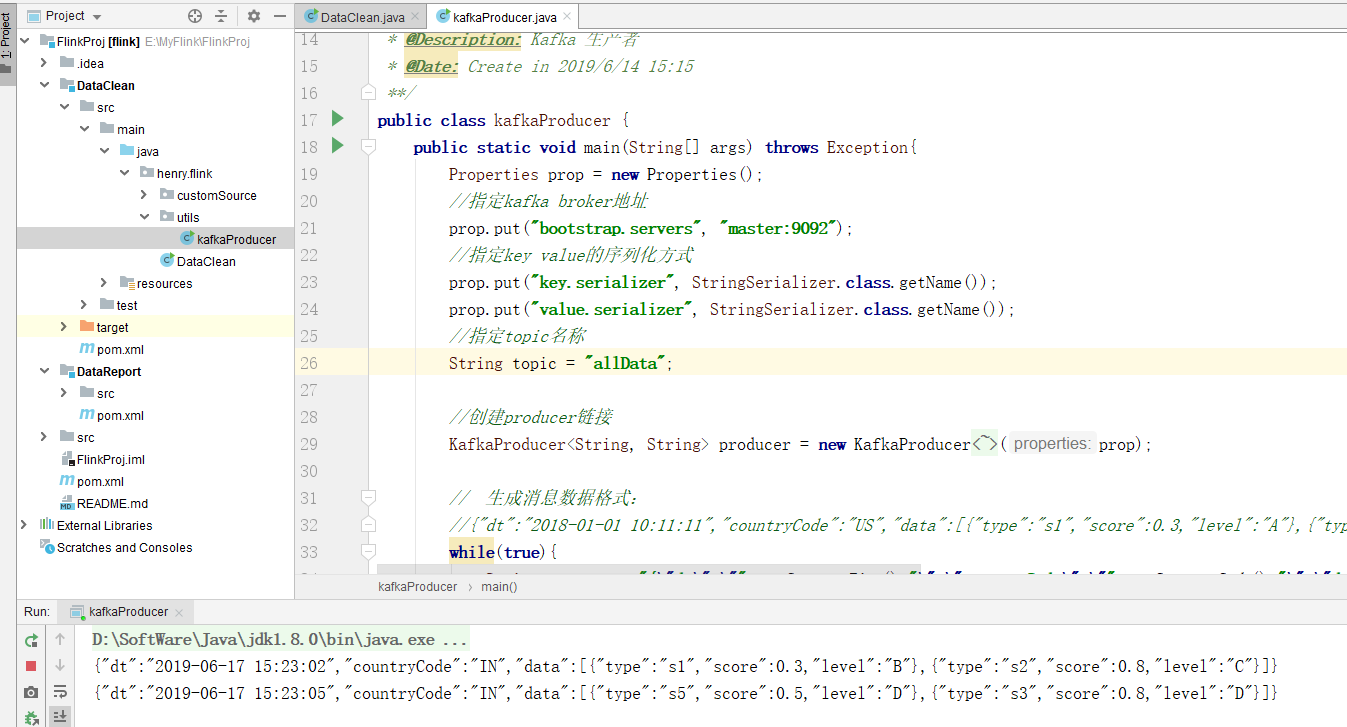
先启动 DataClean 程序,再启动生产者程序,kafka生产者产生数据如下:

最后终端观察处理输出的数据:
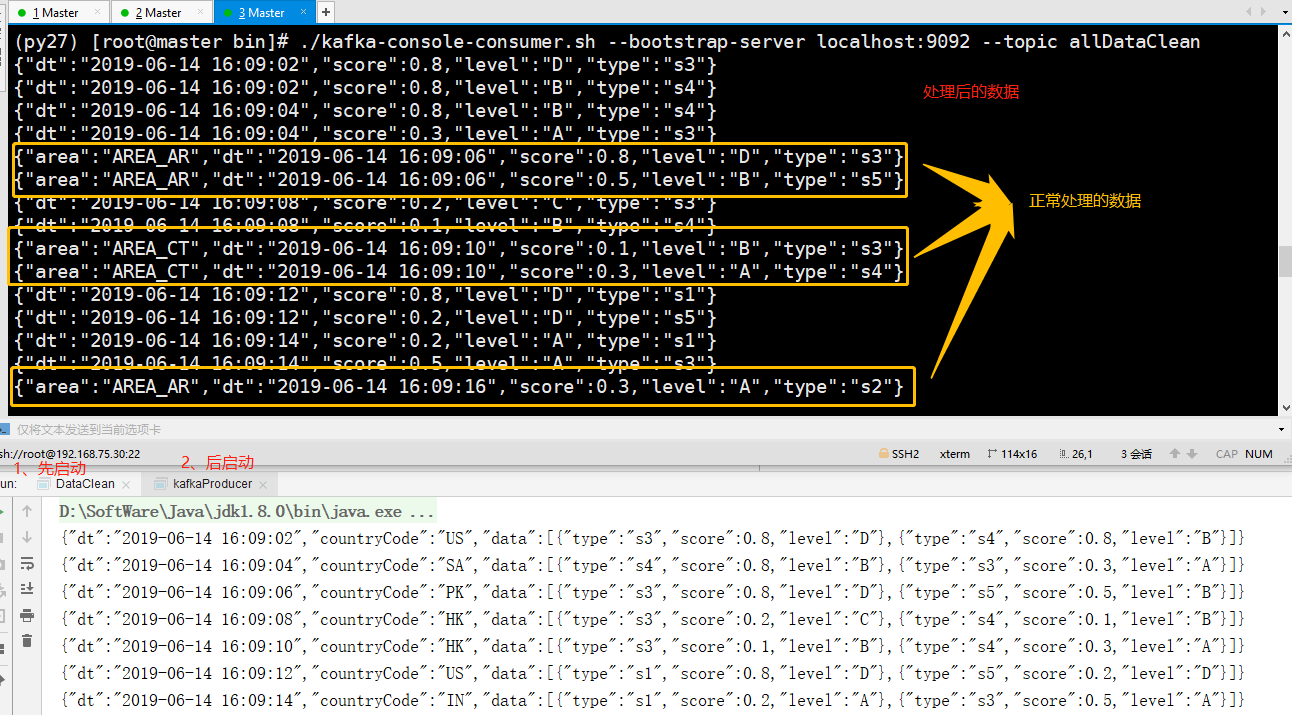
只有部分数据正确处理输出的原因是:代码中没有设置并行度,默认是按机器CPU核数跑的,所以有的线程 allMap 没有数据,有的有数据,所以会导致部分正确,这里需要通过 broadcast() 进行广播,让所有线程都接收到数据:
DataStream<HashMap<String,String>> mapData = env.addSource(new MyRedisSource()).broadcast();
运行结果:
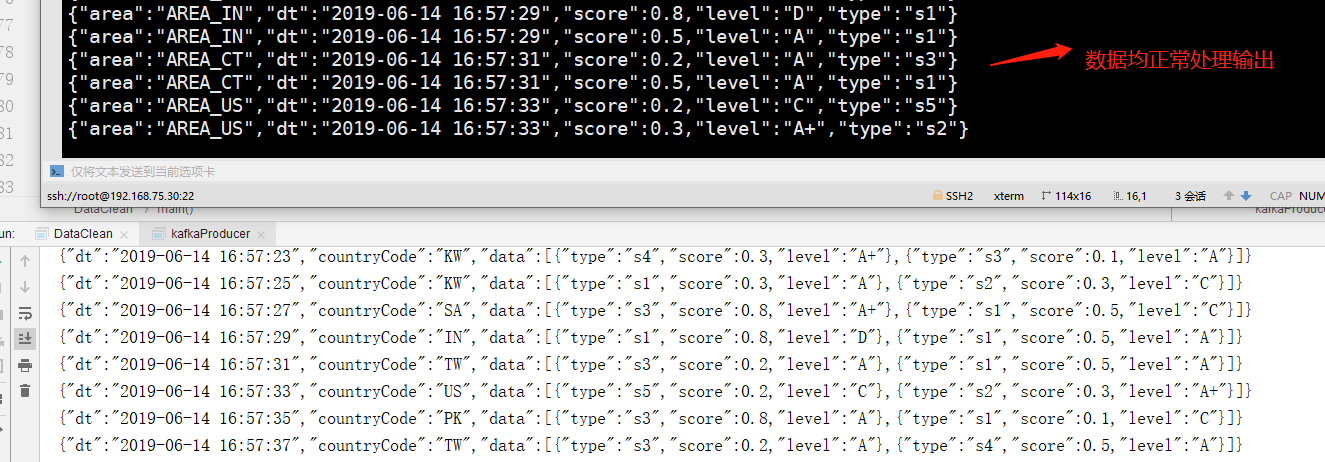
控制台打印结果:
3.4、Flink yarn集群启动
向yarn提交任务:
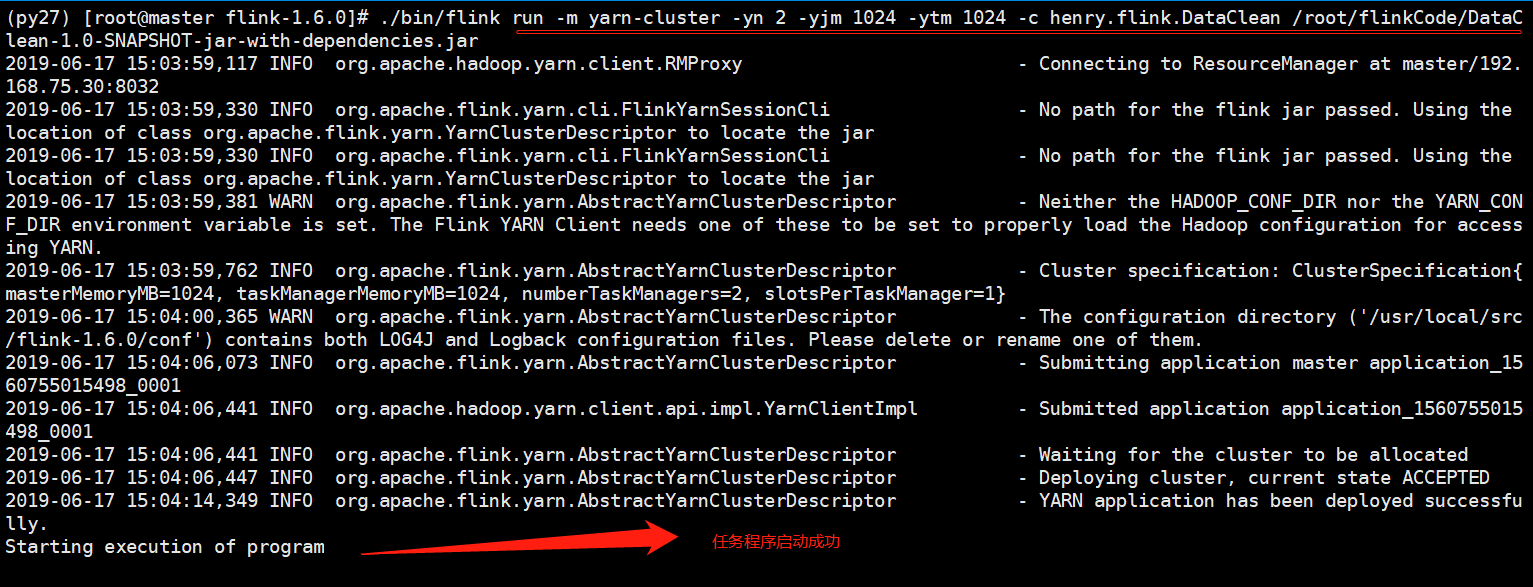
./bin/flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 -c henry.flink.DataClean /root/flinkCode/DataClean-1.0-SNAPSHOT-jar-with-dependencies.jar
任务成功运行启动:
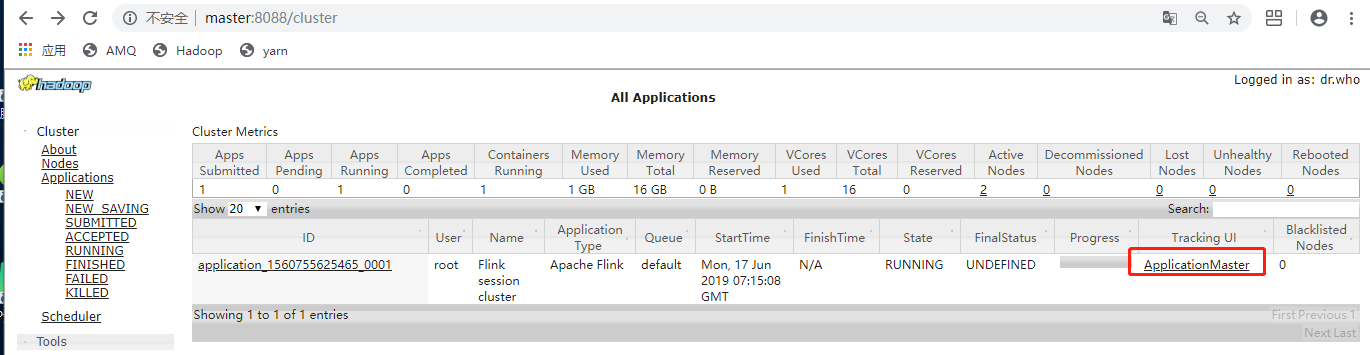
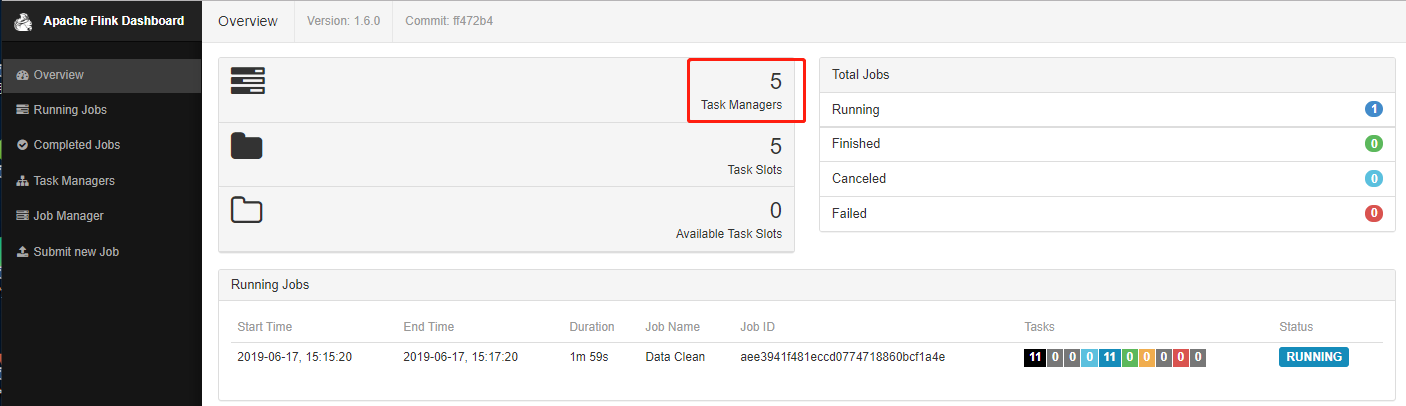
通过 yarn UI 查看任务,并进入Flink job:
程序中设置的并行度:
启动kafka生产者:
监控topic消费情况:
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic allDataClean
最终终端输出结果, 同IDEA中运行结果:

下一节:【20】Flink 实战案例开发(二):数据报表
Github 工程源码地址
最后
以上就是犹豫羊最近收集整理的关于【19】Flink 实战案例开发(一):数据清洗1、应用场景分析2、DataClean代码开发3、实践运行的全部内容,更多相关【19】Flink内容请搜索靠谱客的其他文章。








发表评论 取消回复