终极目标
掌握几种基础的机器算法
分类
有监督,无监督, 强化
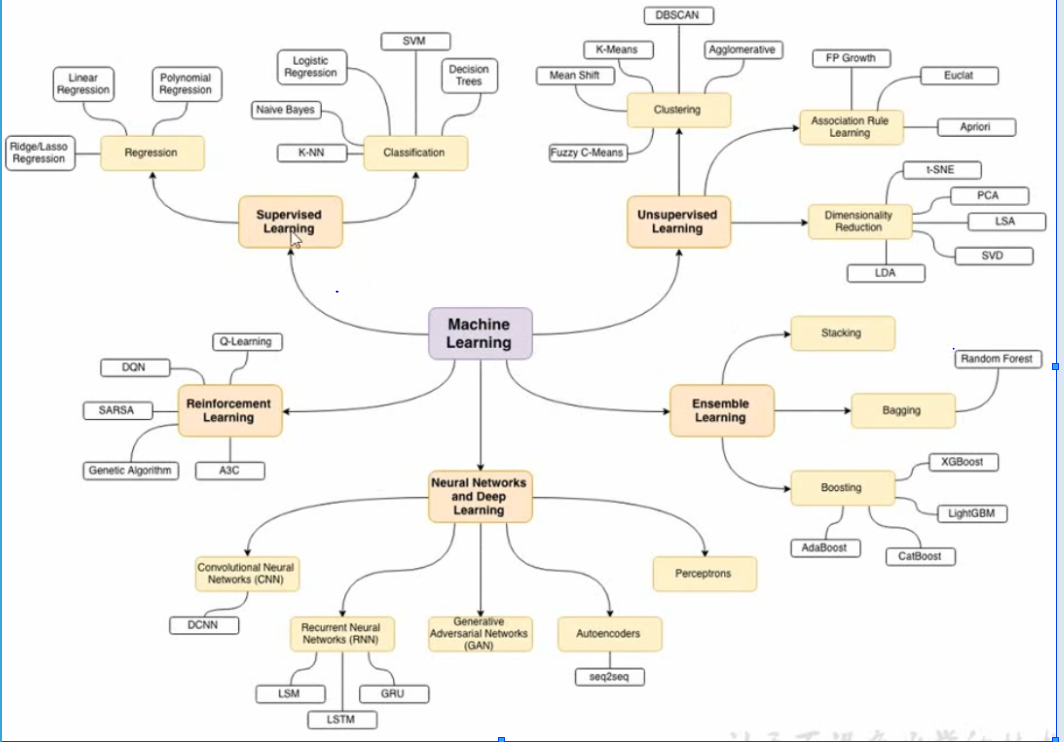 Ensemble learning 混合学习。
Ensemble learning 混合学习。
推荐系统的目的
1 用户 能够找到自己要的东西
2 内容 要更快的送给需要他的用户手中
3 网站 更有效的保留用户资源
基于协同过滤的推荐算法
CF (collaborative filtering)协同过滤
就是比如说,用户,或者商品,当历史数据量小的时候,需要给用户或者商品进行画像,当历史数据量大时,无需这些画像,直接根据其关系就能够给出合适的推荐。
基于近邻的协同过滤
基于用户 user cf
基于物品 item cf
基于模型过滤
奇异值分级(SVD)
潜在语义分析(LSA)
支撑向量机(SVM)
混合推荐
加权混合 权重不同
切换混合
分区混合
分层混合
相似度计算
1欧式距离
2余弦相似度
数值型特征处理
就是,比如说住房面积和房屋价格,两个维度进行计算的话,值的区别很大,那肯定不行,所以值用
Feature=Feature值(Feature最大值减去Feature最小值)
回归
1线性回归 Linear Regression
2多项式回归 ploynomial Regression
3岭回归 Ridge Regression
4 Lasso回归
5 弹性回归网络(ElasticNet Regression)
补充:
梯度下降
要想要损失函数最小,面对多维情况,人们想到了梯度下降的方法
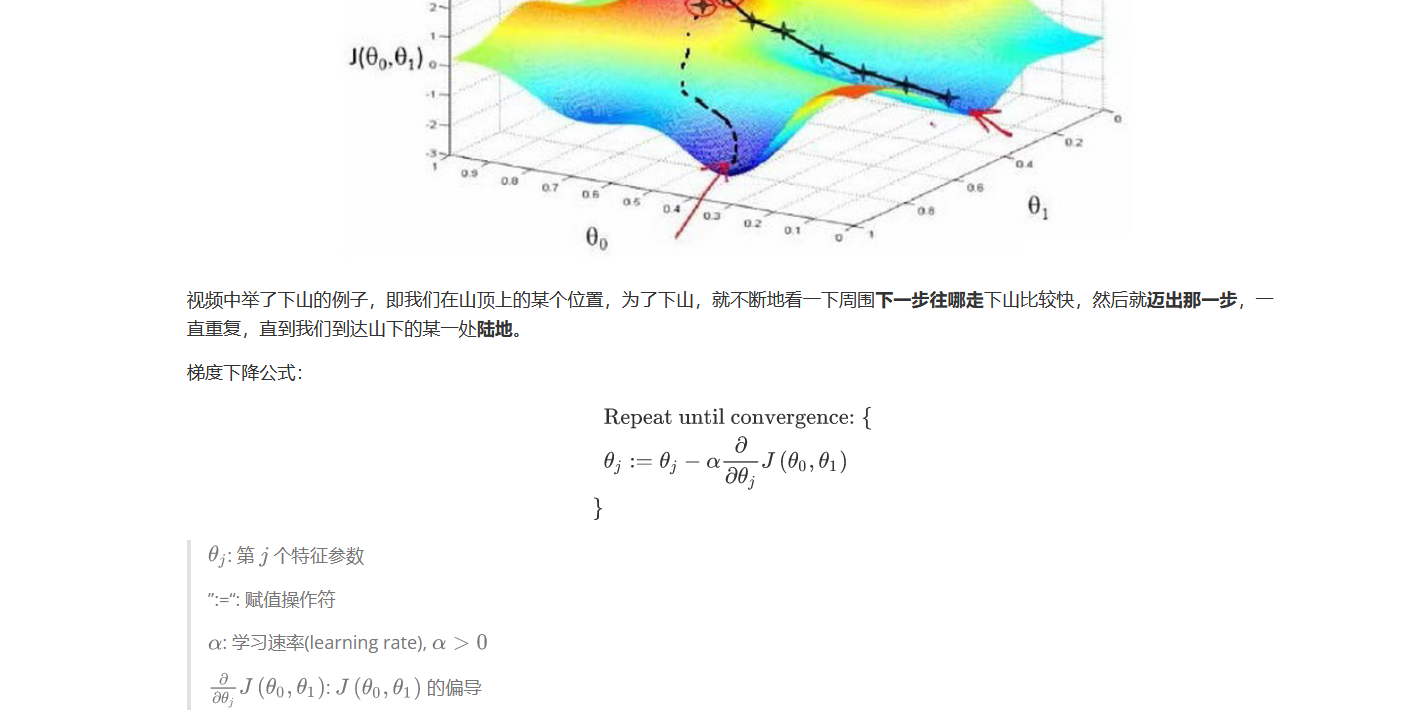
简单说下我的理解 :求误差最小,那就对他求导,为0时就是其最小,学习速率决定他的变化大小,而特征参数则决定其下坡的方向,若:=的右边等于正数,则特征向量继续向该方向移动。
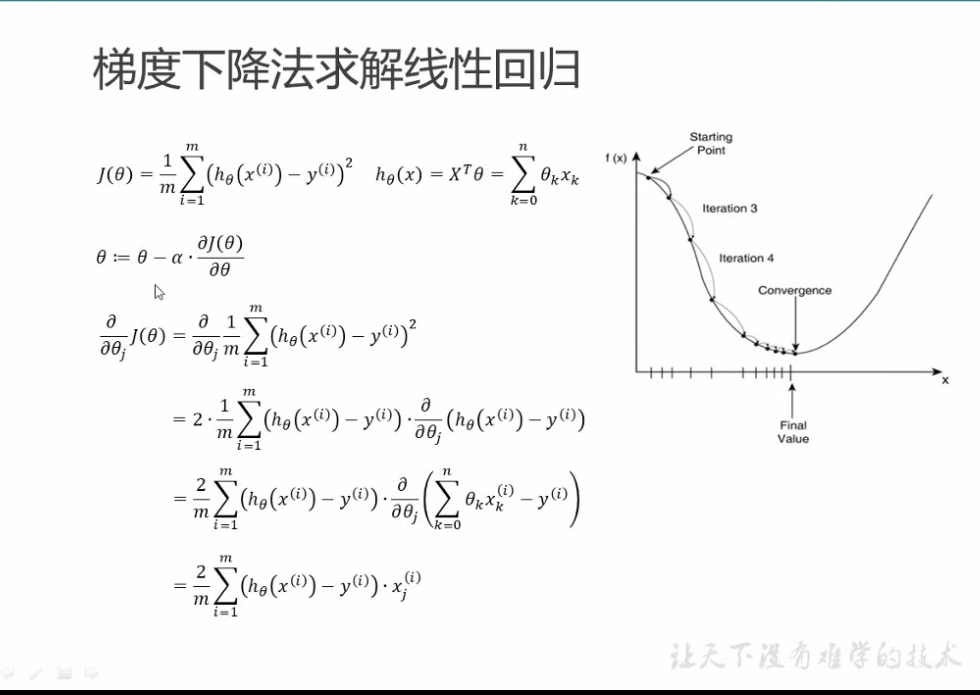
总结一下线性回归
求损失函数在哪最小
 求那个回归直线就是求w,和b,最小二乘法
求那个回归直线就是求w,和b,最小二乘法
得到的那个损失函数,我们需要这个损失函数最小,那就对其求偏导,对w和b分别求偏导,偏导等于0,求出w和b,这条线就出来了,当面对多个变量时,采用梯度下降,因为太多的w,那不得复杂死,所以就不求偏导了,就享图1一样,一点一点下移动,猜最低点的答案,而下图中第二个式子表示的就是 步长乘以方向。
 套用人家写好的包:例子
套用人家写好的包:例子
# 线性回归 这个底层其实就是上边说的最小二乘法计算的损失函数,而不是梯度下降
import numpy as np # 快速操作结构数组的工具
import matplotlib.pyplot as plt # 可视化绘制
from sklearn.linear_model import LinearRegression # 线性回归
# 样本数据集,第一列为x,第二列为y,在x和y之间建立回归模型
data = [
[0.067732, 3.176513], [0.427810, 3.816464], [0.995731, 4.550095], [0.738336, 4.256571], [0.981083, 4.560815],
[0.526171, 3.929515], [0.378887, 3.526170], [0.033859, 3.156393], [0.132791, 3.110301], [0.138306, 3.149813],
[0.247809, 3.476346], [0.648270, 4.119688], [0.731209, 4.282233], [0.236833, 3.486582], [0.969788, 4.655492],
[0.607492, 3.965162], [0.358622, 3.514900], [0.147846, 3.125947], [0.637820, 4.094115], [0.230372, 3.476039],
[0.070237, 3.210610], [0.067154, 3.190612], [0.925577, 4.631504], [0.717733, 4.295890], [0.015371, 3.085028],
[0.335070, 3.448080], [0.040486, 3.167440], [0.212575, 3.364266], [0.617218, 3.993482], [0.541196, 3.891471]
]
# 生成X和y矩阵
dataMat = np.array(data)
X = dataMat[:, 0:1] # 变量x
y = dataMat[:, 1] # 变量y
# ========线性回归========
model = LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
model.fit(X, y) # 线性回归建模
print('系数矩阵:n', model.coef_)
print('线性回归模型:n', model)
# 使用模型预测
predicted = model.predict(X)
# 绘制散点图 参数:x横轴 y纵轴
plt.scatter(X, y, marker='x')
plt.plot(X, predicted, c='r')
# 绘制x轴和y轴坐标
plt.xlabel("x")
plt.ylabel("y")
# 显示图形
plt.show()
1线性回归 Linear Regression
线性回归的几个特点:
- 建模速度快,不需要很复杂的计算,在数据量大的情况下依然运行速度很快。
- 可以根据系数给出每个变量的理解和解释
- 对异常值很敏感
2多项式回归 ploynomial Regression
多项式回归的特点:
- 能够拟合非线性可分的数据,更加灵活的处理复杂的关系
- 因为需要设置变量的指数,所以它是完全控制要素变量的建模
- 需要一些数据的先验知识才能选择最佳指数
- 如果指数选择不当容易出现过拟合
3岭回归 Ridge Regression
如果大学没学好矩阵,请先看***补充的知识点 矩阵***
如果不理解什么是范数, 请先看 补充的知识点 范数
共线性 :指的是自变量直接存在近似线性的关系。
如何确定高共线性呢?
即使理论上该变量应该与Y高度相关,回归系数也不显着。
添加或删除X特征变量时,回归系数会发生显着变化。
X特征变量具有高成对相关性(检查相关矩阵)。

(还不太懂,我没数学基础,总之就是当变量之间的有关系时,加入了一个L2表达式,lasso是加入了L1表达式,我的理解就是,当遇到共线性问题时,就采用套索回归和山岭回归,区别就是套索回归能够产生稀疏,产生少量的特征,而岭回归就是产生比较多的特征,其他的特征无限接近于0,能应对过拟合 具体的以后碰到再说吧)

4Lasso套索回归
套索回归与岭回归非常相似,因为两种技术都具有相同的前提。 我们再次为回归优化函数添加一个偏置项,以减少共线性的影响,从而减小模型方差。 然而,不是使用像岭回归那样的平方偏差,而套索回归使用绝对值偏差
Ridge和Lasso回归之间存在一些差异,这些差异基本上可以回归到L2和L1正则化的属性差异
内置特征选择:经常被提及为L1范数的有用属性,而L2范数则不然。这实际上是L1范数的结果,它倾向于产生稀疏系数。例如,假设模型有100个系数,但只有10个系数具有非零系数,这实际上是说“其他90个预测变量在预测目标值方面毫无用处”。 L2范数产生非稀疏系数,因此不具有此属性。因此,可以说Lasso回归做了一种“参数选择”,因为未选择的特征变量的总权重为0。
稀疏性:指矩阵(或向量)中只有极少数条目为非零。 L1范数具有产生许多具有零值的系数或具有很少大系数的非常小的值的特性。这与Lasso执行一种特征选择的前一点相关联。
计算效率:L1范数没有解析解,但L2有。在计算上可以有效地计算L2范数解。然而,L1范数具有稀疏性属性,允许它与稀疏算法一起使用,这使得计算在计算上更有效。
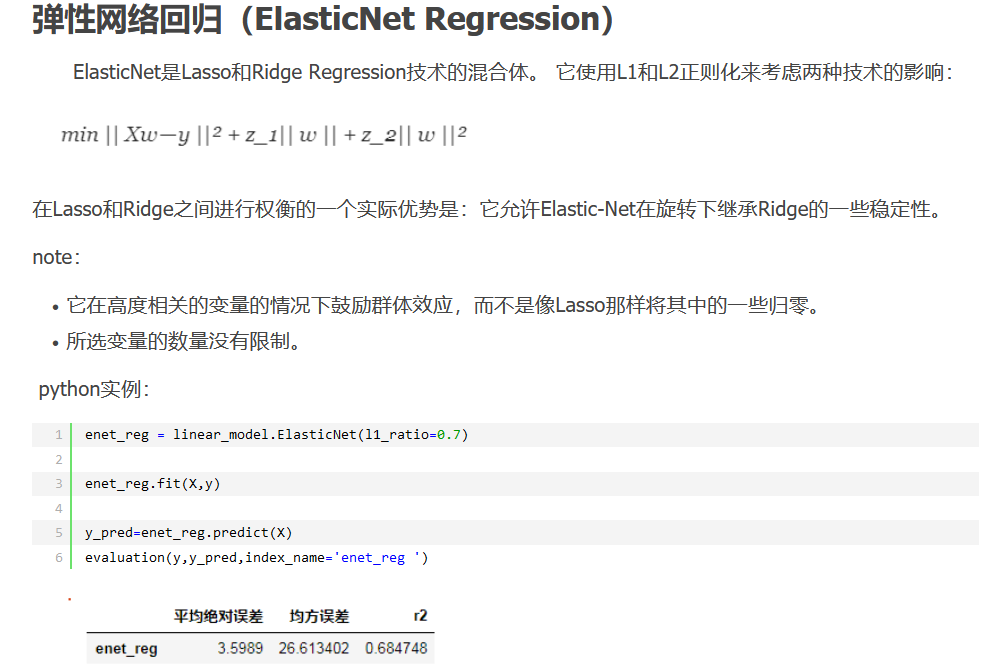
5 弹性回归网络(ElasticNet Regression)
分类算法
补充: 标称型数据就是只有是和否,用来分类
1.KNN k-近邻
本质: 看他的大部分邻居都分为哪一类,他就属于哪个类,结果很大程度取决于K的值(可以简单理解为半径)
距离一般用欧氏距离(平方开根号)即L2,或者曼哈顿距离(绝对值开根号)即L1,余弦相似度。
算法描述:
1 计算测试数据与各个训练数据直接的距离
2按距离递增关系进行排序
3选取距离最小的K个点
4 确定前K个点所在类别出现的频率
5 该测试样本频率大的就属于那一类
代码
import pandas as pd # 数据格式
from sklearn.datasets import load_iris # 数据集 iris一种花的名字
from sklearn.model_selection import train_test_split # 切分数据
from sklearn.metrics import accuracy_score # 分类准确率
from python.knn import kNN # 这个是自定义的类
if __name__ == '__main__':
iris = load_iris()
print(iris)
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
# 给pd加上一列
df['class'] = iris.target
df['class'] = df['class'].map({0: iris.target_names[0], 1: iris.target_names[1], 2: iris.target_names[2]})
print(df)
df.describe() # 查看数据的各个指标
x = iris.data
y = iris.target.reshape(-1, 1)
# 划分训练和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=1,
stratify=y) # 后两个参数一个是种子,一个是按照y分层,按y等比例分割
# 测试
knn = kNN()
knn.fit(x_train, y_train)
y_pred = knn.predict(x_test)
print(y_test)
print('aaaaaaaaaaaa')
print(y_pred)
# 求出预测准确率
accuracy = accuracy_score(y_test, y_pred)
print(accuracy) #测试精准度大约97%
import numpy as np # 快速操作结构数组的工具
def l1_distance(a, b):
return np.sum(np.abs(a - b), axis=1)
def l2_distance(a, b):
return np.sqrt(np.sum((a - b) ** 2, axis=1))
# 核心算法实现
# axis=1表示让矩阵的每一行相加,如果不给这个参数,他加的是矩阵的所有值
class kNN(object):
def __init__(self, n_neighbors=3, dist_func=l1_distance):
self.n_neighbors = n_neighbors
self.dist_func = dist_func
# 训练模型方法
def fit(self, x, y):
self.x_train = x
self.y_train = y
# 模型预测方法
def predict(self, x):
y_pred = np.zeros((x.shape[0], 1), dtype=self.y_train.dtype)
# 遍历输入的x的数据点
for i, x_test in enumerate(x):
# 计算距离
distances = self.dist_func(self.x_train, x_test)
# 给距离做个排序,得到的是索引值的排序
nn_index = np.argsort(distances)
# 设置K点 ravel就是把矩阵变成1维
nn_y = self.y_train[nn_index[:self.n_neighbors]].ravel()
# 统计类别中出现频率最高的那个,赋给y_pred[i] bincount返回的是个出现的次数
y_pred[i] = np.argmax(np.bincount(nn_y))
return y_pred
选取最合适的K值
import xlrd
import numpy as np
from sklearn import model_selection
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
data = xlrd.open_workbook('gua.xls')
sheet = data.sheet_by_index(0)
ressex = sheet.col_values(colx=0, start_rowx=1, end_rowx=None)
a=[]
for num in range(1,sheet.nrows):
a.append(sheet.row_values(num, start_colx=1, end_colx=10))
Y = np.array(ressex)
X = np.array(a)
print(X)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, Y, test_size=0.5, random_state=0,stratify=Y)
k_range = range(1, 31)
k_error = []
#循环,取k=1到k=31,查看误差效果
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
#cv参数决定数据集划分比例,这里是按照5:1划分训练集和测试集
scores = cross_val_score(knn, X, Y, cv=6, scoring='accuracy')
k_error.append(1 - scores.mean())
#画图,x轴为k值,y值为误差值
plt.plot(k_range, k_error)
plt.xlabel('Value of K for KNN')
plt.ylabel('Error')
plt.show()
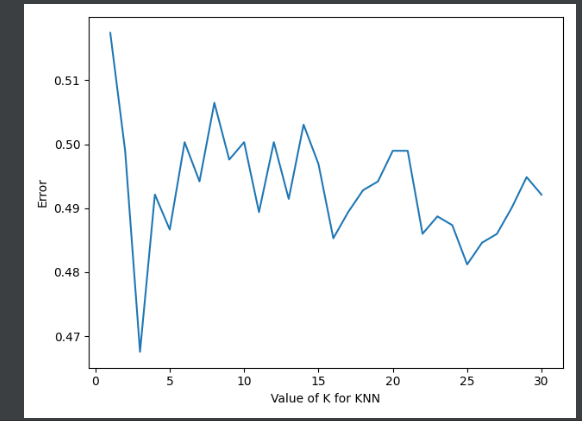 这个最低点就是k值。
这个最低点就是k值。
算法特点:
优点:精度高、对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高
适用数据范围:数值型和标称型
决策树
我理解就是 if else
每一步都选择最优的特征,那问题是如何确定哪个是最优的特征呢?
 熵值越低,说明分类分的特别好。
熵值越低,说明分类分的特别好。
信息增益


算法特点:
优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。
缺点:可能会产生过度匹配问题。
适用数据类型:数值型和标称
型
朴素贝叶斯
算法特点:
优点:在数据较少的情况下依然有效,可以处理多类别问题。
缺点:对于输入数据的准备方式较为敏感。
适用数据类型:标称型数据
逻辑斯蒂回归
针对于边界比较明显的分类,相比于knn,knn在内部分类。
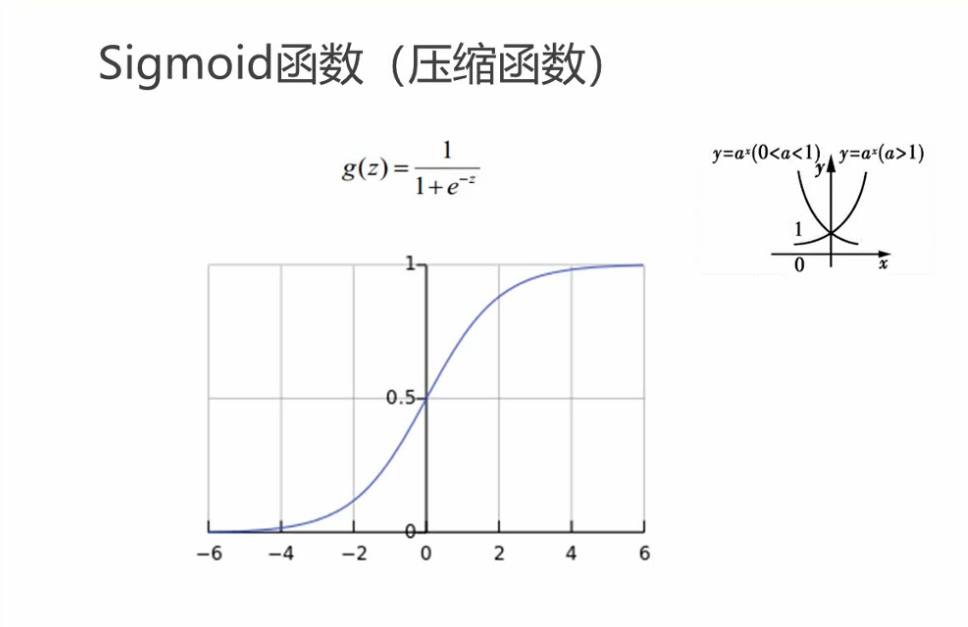 为啥叫压缩函数:就是把x取正无穷或者负无穷时,g(z)的取值为0或者1。
为啥叫压缩函数:就是把x取正无穷或者负无穷时,g(z)的取值为0或者1。
其实并不用看上面的函数而只用看z的正负值,z是正值的时候,取1,负值取0.下图有两个例子。
 损失函数:
损失函数:
不使用平方损失函数,因为之前是二次方,有最低点,这里边有个指数函数,并且z里边也有可能是复杂的。除此之外,比如说,比如说分类那个z等于0.51,他分类正确,但是损失函数是(1-0.51),这分类虽然正确,但是他的损失函数并不小,所以不用平方损失。
应该用下面这个函数图像。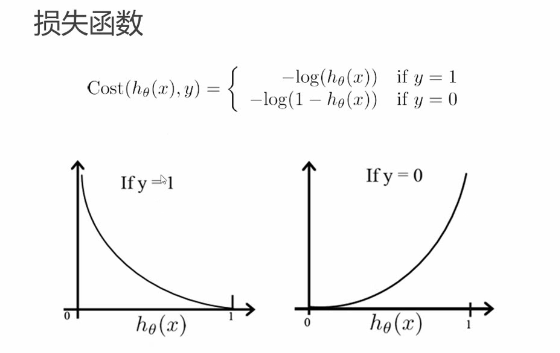
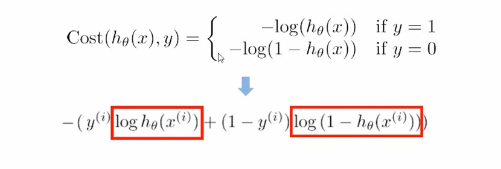
算法特点:
优点:计算代价不高,易于理解和实现
缺点:容易欠拟合,分类精度可能不高
使用数据类型:数值型和标称型数据
支持向量机
算法特点:
优点:计算代价不高,易于理解和实现
缺点:容易欠拟合,分类精度可能不高
使用数据类型:数值型和标称型数据
随机森林
算法特点:
优点:几乎无需输入准备、可实现隐式特征选择、训练速度非常快、其他模型很难超越。
缺点:劣势在于模型大小、是个很难去解释的黑盒子。
使用数据类型:数值型和标称型数据
无监督学习
kmeans
K均值是聚类算法中最为简单,高效的,属于无监督学习算法。
核心思想:
由用户指定K个初始质心,以作为聚类的类别,重复迭代直至算法收敛。
sklearn
补充的知识点
矩阵
1 矩阵的意义
为什么叫线性代数,就是考虑线性的问题,矩阵就是把线性方程上的点都写出来了
2 矩阵相乘的意义

 简单总结一下,相乘的结果就是A矩阵的x的值, Y的值为B矩阵的每个值的意义乘以A矩阵的值。
简单总结一下,相乘的结果就是A矩阵的x的值, Y的值为B矩阵的每个值的意义乘以A矩阵的值。
3 矩阵的秩
秩的汉语意思是官员的品级。
定义:矩阵中所有行向量中极大线性代无关组的元素个数。
可以这样理解
设在矩阵中有一个非零的[公式]阶子式,且所有[公式]阶子式的值均为零。则[公式]的值称为矩阵的秩
R(A) =rank(A) 就是最小的rank(A)阶子式
也可以理解为
将矩阵按列分解为[公式]个向量,组成一个向量组。则该向量组的一个最大线性无关组中包含向量的个数[公式]称为矩阵的行秩。同理可定义列秩,可证列秩=行秩。
矩阵的逆
AB=E
则B是A的逆
如何求呢
 A*表示伴随矩阵,伴随矩阵主对角线交换,和主对角线相对应的右斜线全都乘以-1
A*表示伴随矩阵,伴随矩阵主对角线交换,和主对角线相对应的右斜线全都乘以-1
范数
范数 比如说一个向量,我们求其值(根号下(x的2次方,加上y的二次方)) 这个值就叫做向量的大小,又叫做L2范数的值。
L0范数是指向量中非0的元素的个数。(L0范数很难优化求解)
L1范数是指向量中各个元素绝对值之和
L2范数是指向量各元素的平方和然后求平方根
L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。
L1范数: 可以进行特征选择,即让特征的系数变为0.
L2范数: 可以防止过拟合,提升模型的泛化能力,有助于处理 condition number不好下的矩阵(数据变化很小矩阵求解后结果变化很大)(核心:L2对大数,对outlier离群点更敏感!)
下降速度:最小化权值参数L1比L2变化的快
模型空间的限制:L1会产生稀疏 L2不会。L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。
损失函数和代价函数的区别
损失函数(Loss/Error Function): 计算单个样本的误差。link
代价函数(Cost Function): 计算整个训练集所有损失函数之和的平均值
分类问题考虑的准确度,精确度,召回率区别
一个班100人 20女 80男,现在要选20名女生,但是一个盲人选了50个人,其中20人女,30人男
准确度就是(20+50)/100 20表示20个女生,50表示分类正确的未被选中的男生
精确度就是20/50
召回率就是20/20
微积分
导数
偏导数(x或者y方向)
方向导数(任意方向)
 梯度
梯度
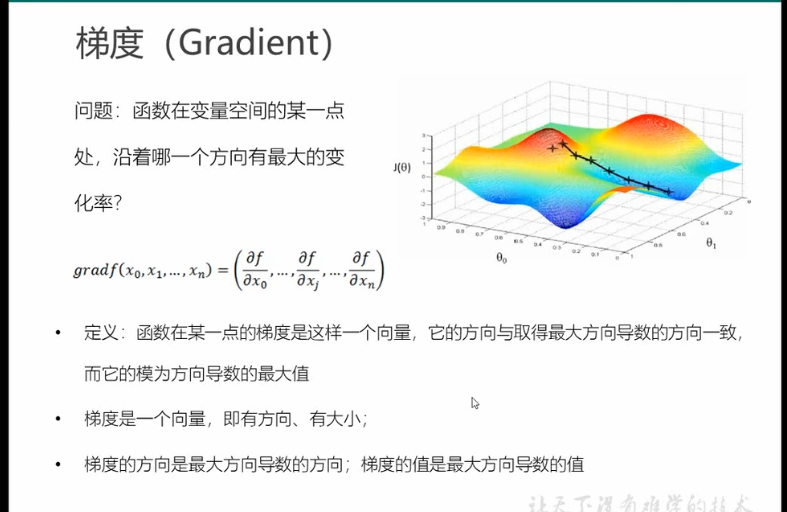 简单理解,斜率最快的方向集合组成的向量就是下降最快的
简单理解,斜率最快的方向集合组成的向量就是下降最快的
概率
均值
方差
标准差
概率分布
均匀分布 正态分布 指数分布
贝叶斯公式
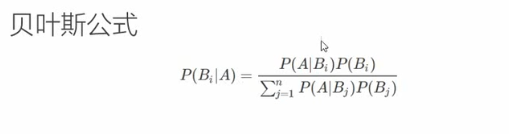 贝叶斯公式简单理解,分子就是这两个同时发生的概率,分母是全概率公式,即A发生的概率。
贝叶斯公式简单理解,分子就是这两个同时发生的概率,分母是全概率公式,即A发生的概率。
奥卡姆剃刀
就是说,不要过分的追求训练误差,而把模型复杂化。
牛顿法和拟牛顿法
 比梯度下降更快一点。
比梯度下降更快一点。
sklearn学习
决策树
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import pandas as pd
# coding=utf-8
wine = load_wine()
a = pd.concat([pd.DataFrame(wine.data), pd.DataFrame(wine.target)], axis=1)
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data, wine.target, test_size=0.3)
# 主要就是splitter,他就是生成决策树时,会生成好多个,每次最优的选择不一定是最好的,他默认是best,也就是每次选择都是最优的
clf = tree.DecisionTreeClassifier(criterion="gini",random_state=0,splitter="random")
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest)
import graphviz
dot_data = tree.export_graphviz(clf, feature_names=["1T", "2T", "3T", "4T", "5T", "6T", "7T", "8T", "9T", "10T", "11T",
"12T",'13T'], class_names=["oneC", "twoC", "threeC"], filled=True,
rounded=True)
graph = graphviz.Source(dot_data)
print clf.feature_importances_
所有参数列表
1 criterion 这个参数用来决定不纯度的计算方法
: entropy(信息熵) gini基尼系数
最后
以上就是风中大炮最近收集整理的关于机器学习入门终极目标分类推荐系统的目的基于协同过滤的推荐算法回归分类算法无监督学习sklearn补充的知识点sklearn学习所有参数列表的全部内容,更多相关机器学习入门终极目标分类推荐系统内容请搜索靠谱客的其他文章。








发表评论 取消回复