学习SVM的心得体会以及搜集的一些面试题
- SVM
- 硬间隔SVM
- 推导过程
- 软间隔SVM
- 推导过程
- 支持向量回归SVR
- 推导过程
- 损失函数
- 训练过程
- 核函数
- SVM相关面试题
SVM
SVM的思想是在特征空间中找到一个超平面划分不同类,并且间隔最大的超平面意味着分类置信度比较大。
硬间隔SVM
如样本是线性可分的,则使用硬间隔的SVM,每个样本都是分类正确的
推导过程
空间超平面的方程为Wx+b = 0,W为平面法向量。
点到平面的距离为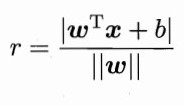
最大化间隔即为
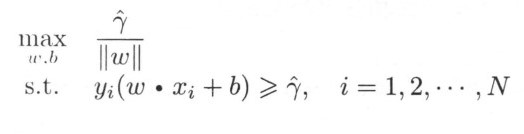
具体取值无关,而1/W最大等价于W最大,所以问题等价于
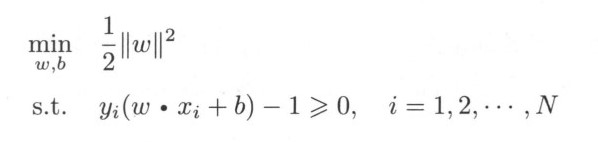
定义拉格朗日函数
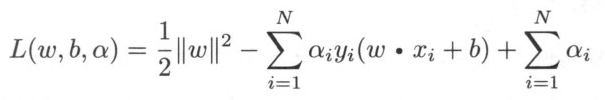
所以原问题转换为对偶问题
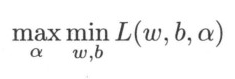
先求min令其对w和b的偏导为0得出
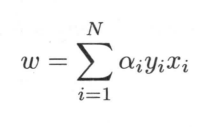
和
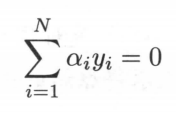
代入原式,对偶问题变成了
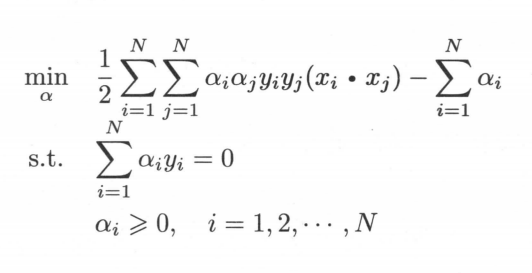
然后因为KKT条件,非拉格朗日参数的偏导为0;拉格朗日项为 0;拉格朗日乘子小于0,拉格朗日参数大于0。即;
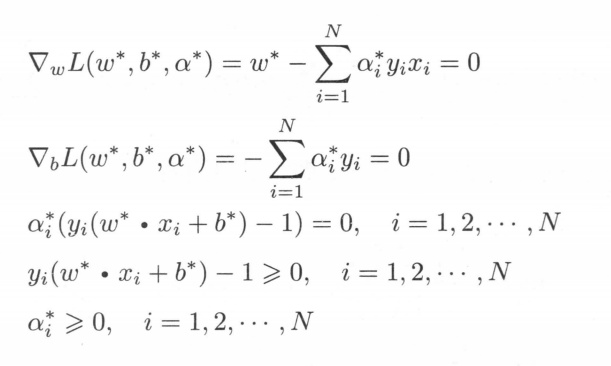
(倒数第二个式子需要移项,不等式变号)
由此可以推出对于样本i,要么ai=0,要么y(Wx+b) = 1为分界线上的支持向量。
所以支持向量机参数W,b只取决于少数ai不等于0的支持向量。
最后
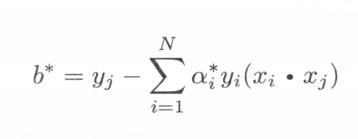
所以超平面可表示为
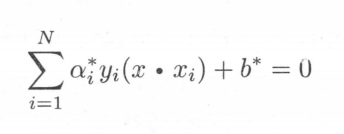
其中a*为支持向量的拉格朗日参数。
软间隔SVM
如果 样本近似线性可分,允许少数分类错误,那么可以使用软间隔的SVM。
推导过程
为每个样本引入一个松弛向量,使得样本可以在两个间隔平面中间,既
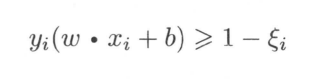
那么目标函数变为了
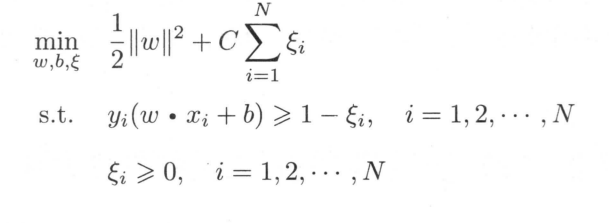
其中C为惩罚系数,平衡间隔最大和误分类个数最少。
其拉格朗日函数为
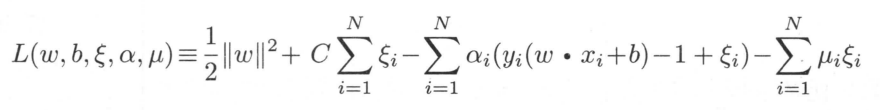
同上步骤一致,对W,b,间隔求偏导令其为0
得
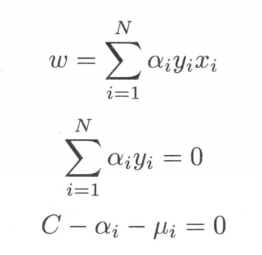
回代得结果和硬间隔SVM一致但是约束多了两个
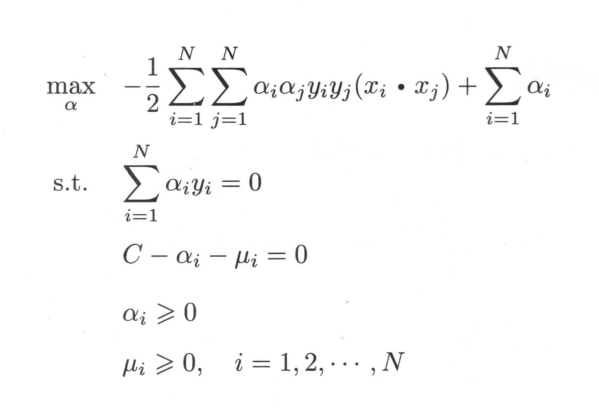
同理由KKT条件可得
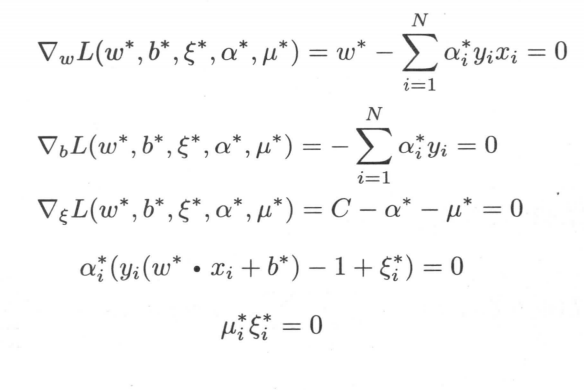
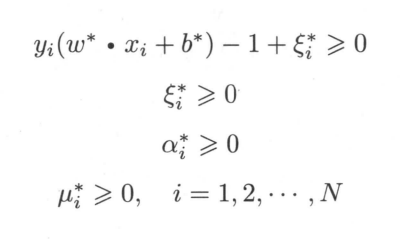
我们可以看出若ai<C则ui>0进一步推出间隔=0,该支持向量就在间隔边界上;当ai=C时
- 间隔在(0,1)之间,则样本Xi分类正确,位于超平面和间隔边界之间
- 间隔为1,样本恰好在超平面之上
- 间隔大于1,样本分类错误
支持向量回归SVR
如果把训练得到的超平面用于回归问题
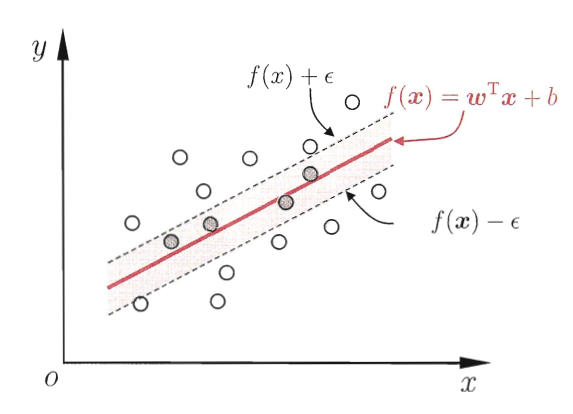
红色区域为不计入损失的区域
推导过程
为超平面两侧引入不同的松弛向量则得到
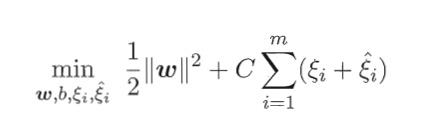
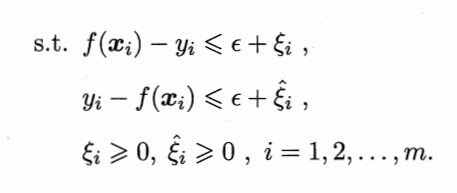
其拉格朗日函数为
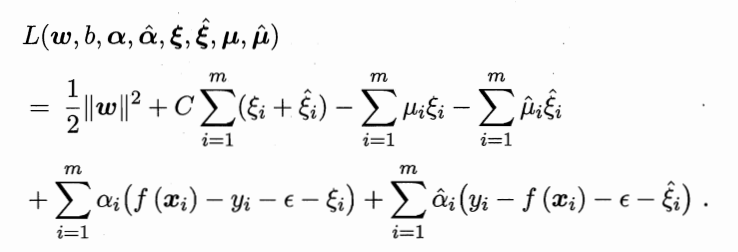
求偏导为0,得
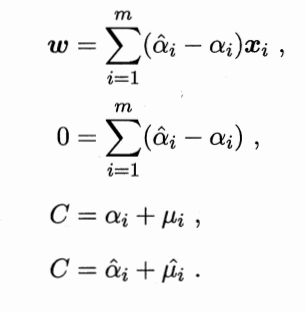
回代得对偶问题
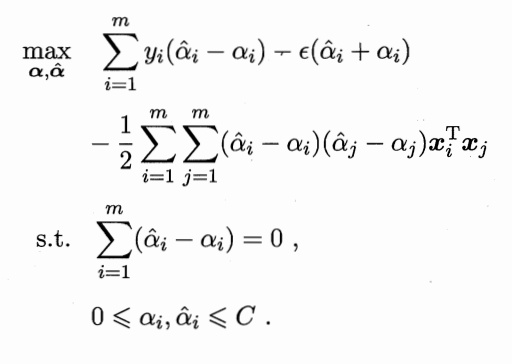
需要满足KKT条件
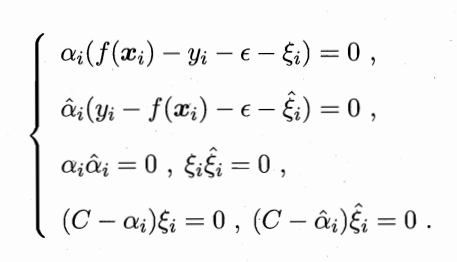
损失函数
软间隔SVM还有另外一种推导方式,最小化损失函数
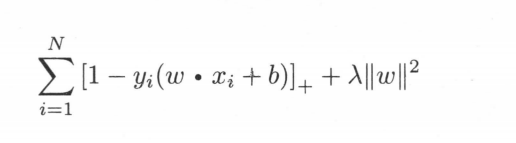
相当于合页损失函数加上L2正则
训练过程
SMO方法,每次选择两个变量ai和aj,并固定其他得参数,然后解对偶问题,得到新的ai和aj。变量得选择先选取违背KKT条件最大得样本,在选择与第一个样本最远的样本。直观解释是样本差异大,对模型得更新程度比较大。
b这个参数通过支持向量y-Wx的平均值得出。
核函数
当样本线性不可分时,就要引入映射,把样本投影到高维可分的平面再去求解,然后因为计算投影函数,再计算内积比较麻烦,直接引入核函数,用K(x1,x2)计算x1和x2在高维空间中的内积。
SVM的目标函数借助核函数就可以化为
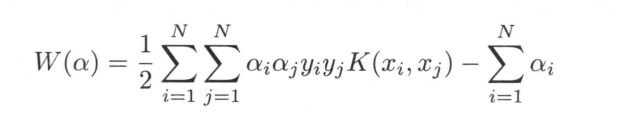
常用核函数有

但是实际上要用核函数的时候就用高斯核,因为高斯核可以拟合无穷维空间(高斯核函数的泰勒展开相当于0到n维的多项式核函数之和),改变一下带宽即可。带宽越大,样本影响的范围也越大。带宽越小,非线性程度越大,分类能力越强,容易发生过拟合。
SVM相关面试题
1.SVM的特点
可以解决高维数据的问题(对偶问题把维度相关问题化为了和样本数有关)
全局求解,避免了局部最优
相当于自带L2正则
但是对缺失数据敏感,噪声敏感(关键支持向量)
输入数据需要归一化(涉及计算距离,归一化提高精度;用梯度下降计算的,归一化提高速度)
复杂度为O(n2),大数据不合适
2.为什么要转换为对偶问题
- 把目标函数和约束全部融入一个新的函数,即拉格朗日函数,再通过这个函数来寻找最优点,更容易处理。
- 出现样本内积形式,自然引入核函数。
- 把与样本维度相关的求解转换为与样本数量有关(支持向量)
3.SVM怎么输出预测概率
把SVM的输出结果当作x经过一层LR模型得到概率,其中lr的W和b参数为使得总体交叉熵最小的值。
4.SVM和LR的区别
- LR和SVM都可以处理分类问题,且一般都用于处理线性二分类问题(在改进的情况下可以处理多分类问题)
- 两个方法都可以增加不同的正则化项,如l1、l2等等。所以在很多实验中,两种算法的结果是很接近的。
- LR和SVM都可以用来做非线性分类,只要加核函数就好。
- LR和SVM都是线性模型,当然这里我们不要考虑核函数
- 都属于判别模型
不同 - LR是参数模型,SVM是非参数模型。
- 从损失函数来看,区别在于逻辑回归采用的是logistical loss(极大似然损失),SVM采用的是合页损失,这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
- 逻辑回归相对来说模型更简单,好理解,特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些,SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算。
- SVM不直接依赖数据分布,而LR则依赖整体数据分布,因为SVM只与支持向量那几个点有关系,而LR和所有点都有关系。
- SVM依赖正则系数,实验中需要做CV
- SVM本身是结构风险最小化模型,而LR是经验风险最小化模型
最后
以上就是文静羊最近收集整理的关于SVM详解以及常见面试题SVMSVM相关面试题的全部内容,更多相关SVM详解以及常见面试题SVMSVM相关面试题内容请搜索靠谱客的其他文章。



![[BFS]简单例题,模板](https://www.shuijiaxian.com/files_image/reation/bcimg7.png)




发表评论 取消回复