SVM练习题
1.支持向量机的基本思想是什么?
A:SVM分类器在类之间拟合可能的最宽的“街道”。换言之,它的目的是使决策边界之间的间隔最大化,该决策边界分隔两个类别和训练实例。SVM执行软间隔分类时,实际上是在完美分隔两个类和拥有尽可能最宽的街道之间寻找折中方法(也就是允许少数实例最终还是落在街道上)。还有一个关键点是在训练非线性数据集时,记得使用核函数。
2.什么是支持向量?
A:决策边界完全由位于“街道”边缘的实例所决定(或者称之为“支持”)。这些实例被称为支持向量。位于“街道”之上的实例被称为支持向量,这也包括处于边界上的实例。非支持向量的实例(也就是街道之外的实例)完全没有任何影响。你可以选择删除它们然后添加更多的实例,或者将它们移开,只要一直在街道之外,它们就不会对决策边界产生任何影响。计算预测结果只会涉及支持向量,而不涉及整个训练集。
3.使用SVM时,对输入值进行缩放为什么重要?
A:支持向量机拟合类别之间可能的、最宽的“街道”,所以如果训练集不经缩放,SVM将趋于忽略值较小的特征。
4.SVM 分类器在对实例进行分类时,会输出信心分数吗?概率呢?
A:支持向量机分类器能够输出测试实例与决策边界之间的距离,你可以将其用作信心分数。但是这个分数不能直接转化成类别概率的估算。如果创建SVM时,在Scikit-Learn中设置probability=True,那么训练完成后,算法将使用逻辑回归对SVM分数进行校准(对训练数据额外进行5-折交叉验证的训练),从而得到概率值。这会给SVM添加predict_proba()和predict_log_proba()两种方法。
5.如果训练集有成百万个实例和几百个特征,你应该使用SVM原始问题还是对偶问题来训练模型?
A:使用SVM原始问题。这个问题仅适用于线性支持向量机,因为核SVM只能使用对偶问题。对于SVM问题来说,原始形式的计算复杂度与训练实例m的数量成正比,而其对偶形式的计算复杂度与某个介于m²和m³之间的数量成正比。所以如果实例的数量以百万计,一定要使用原始问题,因为对偶问题会非常慢。
当训练实例的数量小于特征数量时,解决对偶问题比原始问题更迅速。
6.假设你用RBF核训练了一个SVM分类器,看起来似乎对训练集欠拟合,你应该提升还是降低γ(gamma)?C呢?
A:如果一个使用RBF核训练的支持向量机对训练集欠拟合,可能是由于过度正则化导致的。你需要提升γ(gamma)或C(或同时提升二者)来降低正则化。
正则化可以解决过拟合问题,降低正则化参数可以解决欠拟合问题。
γ(gamma) ↑ 或 C ↑ 正则化 ↓ ——解决欠拟合问题
γ(gamma) ↓ 或 C ↓ 正则化 ↑ ——解决过拟合问题
7.如果使用现成二次规划求解器,你应该如何设置QP参数(H、f、A和b)来解决软间隔线性SVM分类器问题?
A:我们把硬间隔问题的QP参数定义为H’、f’、A’及b’。软间隔问题的QP参数还包括m个额外参数(np=n+1+m)及m个额外约束(nc=2m)。它们可以这样定义:
H等于在H’右侧和底部分别加上m列和m行个0:
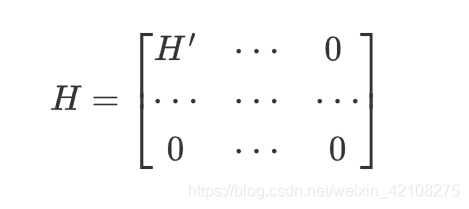
f等于有m个附加元素的f’,全部等于超参数C的值。
b等于有m个附加元素的b’,全部等于0。
A等于在*A’的右侧添加一个mm的单位矩阵 Im,在这个单位矩阵的正下方再添加单位矩阵- Im,剩余部分为0:
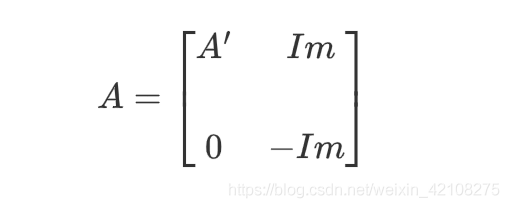
最后
以上就是迷你水池最近收集整理的关于SVM练习题SVM练习题的全部内容,更多相关SVM练习题SVM练习题内容请搜索靠谱客的其他文章。








发表评论 取消回复