Master节点主要完成集群管理器的中心化部分,作用是分配Application 到Worker节点,维护Worker节点,Driver,Application的状态,Worker节点负责具体业务的运行。
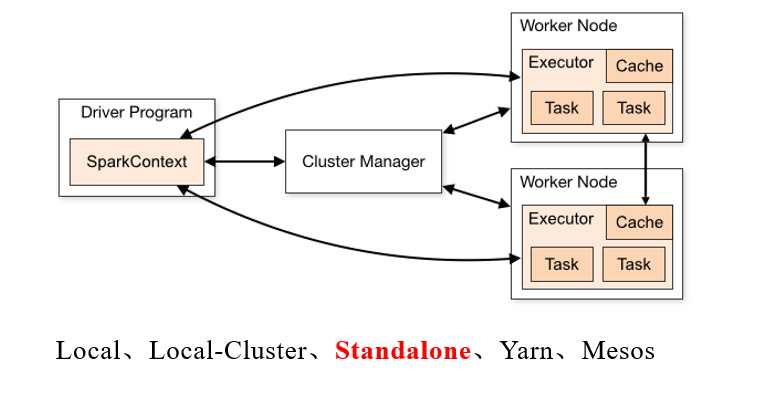
Driver端的主要作用是:初始化SparkContext 与Spark集群进行通信,真正执行sc.textFile() , map,flatmap() 都是在Executor中进行执行的。
上图是Spark的四种模式 分别是Local Local-Cluster Standalone Yarn Mesos 模式,四种模式之间相互独立互不相关,四种模式的区别在于上图所示的Cluster Manager 的不同。一个Worker节点可以有多个的Executor。
在Driver端只是进行提交操作,初始化SparkContext,new 对象等操作,比如在Driver端创建了一个数组,Executor中需要用到这个数组,这时候就会把数据发送到Executor中。
collect() 的作用是将Executor中的内容抓取到Driver端进行展示。
最后
以上就是完美奇异果最近收集整理的关于Spark 的角色理解的全部内容,更多相关Spark内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复