我是靠谱客的博主 虚心纸飞机,这篇文章主要介绍论文笔记 AAAI 2021|what the role is vs. What plays the role: Semi-supervised Event Argument Extraction v,现在分享给大家,希望可以做个参考。
文章目录
- 1 简介
- 1.1 动机
- 1.2 创新
- 2 方法
- 3 半监督双重训练策略
- 4 实验
1 简介
论文题目:What the role is vs. What plays the role: Semi-supervised Event Argument Extraction via Dual Question Answering
论文来源:AAAI 2021
论文链接:https://ojs.aaai.org/index.php/AAAI/article/view/17720
1.1 动机
- 目前的事件论元抽取方法存在两个限制:1)不充分地参数共享。2)不充分地利用论元角色的语义信息。
1.2 创新
- 提出了一个半监督学习框架DualQA(dual question answering))解决低资源情况下的事件论元抽取。
- 为了尽可能地共享参数和利用角色语义信息,在问答范式下提出事件论元识别和事件角色识别(使用dual training进行训练)。
2 方法
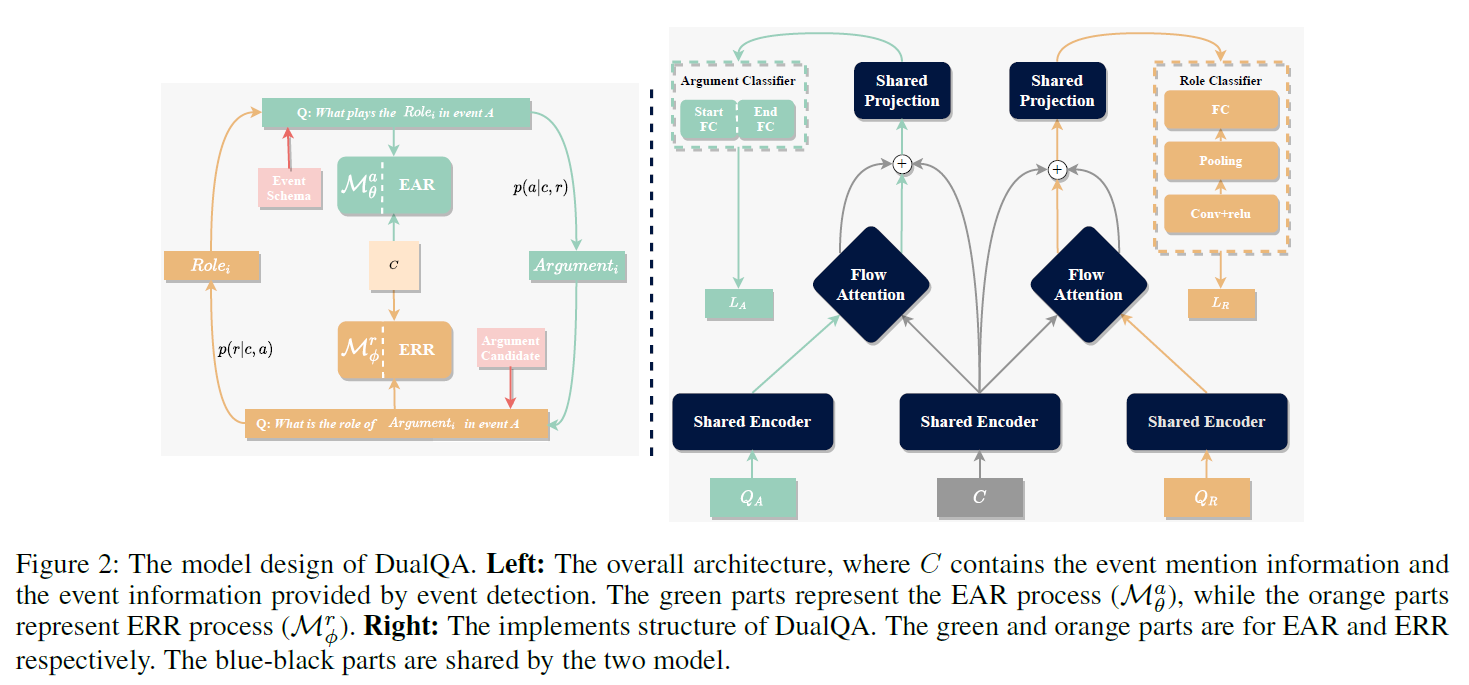
整体框架如上图所示,主要分为下面几部分:
- 问题生成:事件论元识别的问题为What plays the role x r x_r xr in x t x x_{tx} xtx? ( x d 1 , . . . , x d n ) (x_d^1,...,x_d^n) (xd1,...,xdn) 事件角色识别的问题为What is the role of x a x_a xa in x t s x_{ts} xts?
- 实体编码:使用BERT-based对上下文和问题进行编码,公式如下:
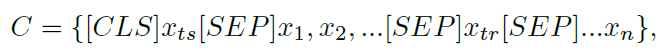
|
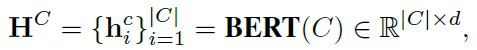
|
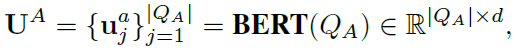
|
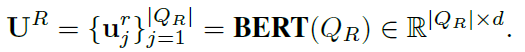
|
- Flow Attention: 该模块的主要目的是将问题和上下文结合,并为上下文中的每个单词生成一组query-aware特征向量。attention从两个方向被计算:从上下文到问题(C2Q)和从问题到上下文(Q2C),首先计算问题和上下文的相似性( S A , S R S^A,S^R SA,SR),然后根据相似性进行注意力计算,最后得到query-aware特征向量。公式如下:
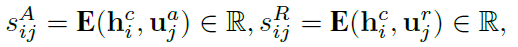
|
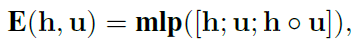
| |
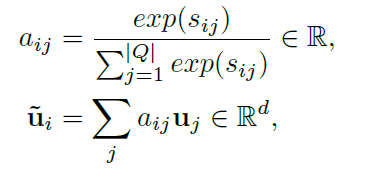
|
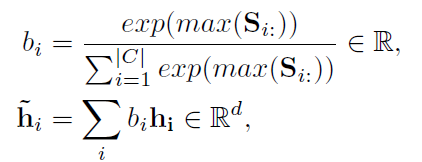
|
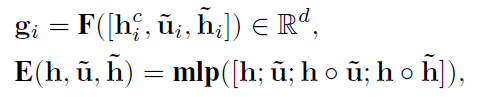
|
- 论元分类:预测每个token是否为论元的开始或者结束,公式如下:
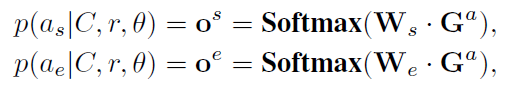
- 角色分类:使用CNN对角色进行分类:

3 半监督双重训练策略
每轮训练主要分为两步:1)联合训练模型 2)使用模型标注数据,扩充训练集(当事件论元识别和事件角色识别的结果相同时认为是可靠的标注)。当没有未标注的数据或者模型拟合时停止训练。loss公式和伪代码如下:
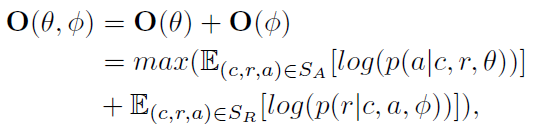
|
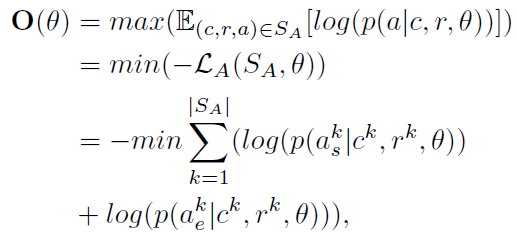
|
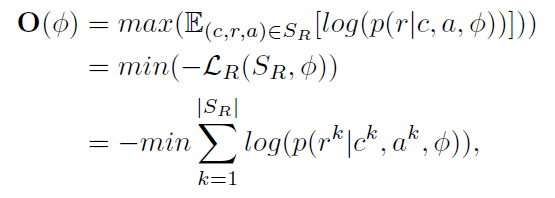
|

4 实验
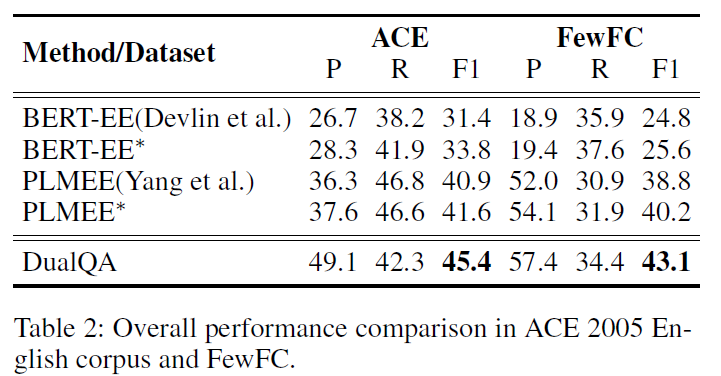
数据集为ACE 2005英语语料和FewFC中文金融语料,为了建立低资源的条件,ACE数据集选择10%的训练数据作为标注数据,60%作为未标注数据;FewFC数据集选择1%的训练数据作为标注数据,60%作为未标注数据,实验结果如下:
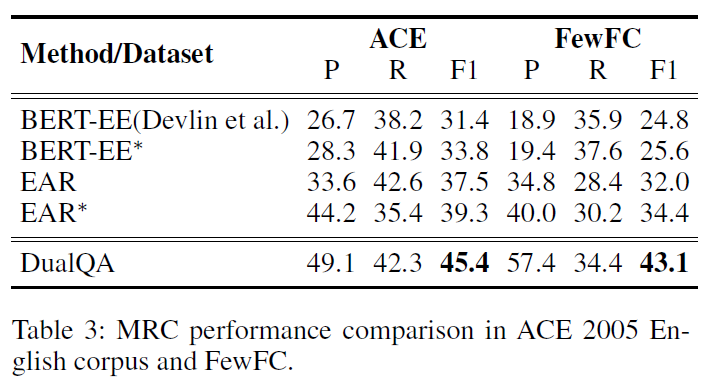
机器阅读理解框架的消融实验,结果如下:
双向学习的消融实验,结果如下:
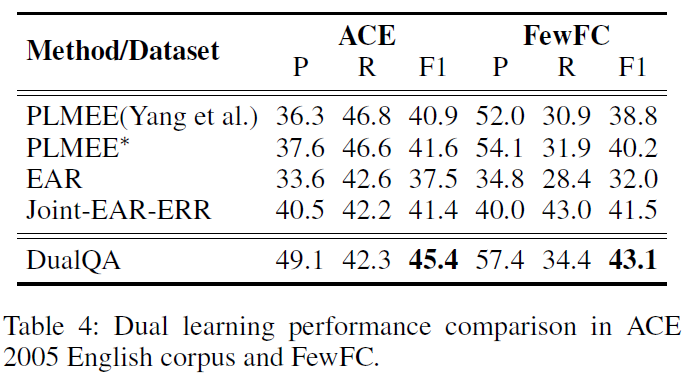
不同数据量情况下的实验结果:
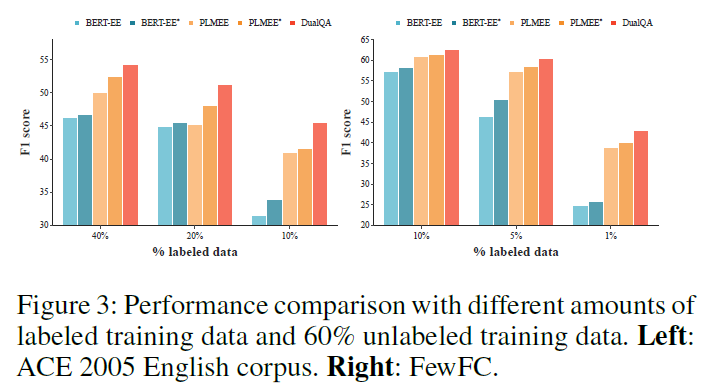
标注数据的质量:
最后
以上就是虚心纸飞机最近收集整理的关于论文笔记 AAAI 2021|what the role is vs. What plays the role: Semi-supervised Event Argument Extraction v的全部内容,更多相关论文笔记内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复