Document-Level Relation Extraction with Adaptive Thresholding and Localized
Context Pooling

文档级别的关系抽取提出了一个新的挑战相较于之前句子级别的抽取。一个文档一般包含多个实体对,每个相同的实体对在整个文章中可能对应有不同的关系。在这片论文中,他们提出了2个新的方法,一个是适应性二值化选取和邻近内容池化来解决多标签和多实体的问题。
适应性二值化替换全局二值化对于多标签的分类在首要的工作中。
临近内容池化直接转化注意力从预训练语言模型到一个能够帮助决定关系的临近关系。这个方法已经在3个文档等级的datasets中实现了。分别是docRED、CDR和GDA。

这是一个文档级别关系抽取的例子。
问题的建模
对于一个文档d和实体集合ei,文档级别关系抽取的任务是来预测一个关系的子集来自于实体对(es,e0)的R U {NA}。R是一个预定义关系的集合,es是主语so是宾语。每个实体ei可能被提及很多次 记为m。没有任何关系的被标记为NA。综上,问题被转换为预测d中所有实体对(es,eo)的标签。
对于bert baseline的加强
在这部分将简要介绍基础模型的构建,该模型是在bert的基础上构建的,通过一些技术手段加强了它的效果
编码器
d=[xt],标记每个提及的实体一个特殊的符号*在第一次提及和最后一次提及处。这里使用的方法是实体标记技术 (Zhang et al. 2017; Shi and Lin 2019; Soares et al.
2019).
然后将文档放入预训练语言模型中去获得上下文内容的嵌入
H=[h1,h2…hl]=bert([x1,…xl])
一旦文章词嵌入完成之后,下一步是实体对的分类使用的方案是参考的k这个工作(Verga, Strubell, and McCallum 2018; Wang et al. 2019b)
然后选取带有 ※的实体,对于它所有的提及m使用logsumexp pooling的方法来获得嵌入hei(Jia, Wong, and Poon 2019)
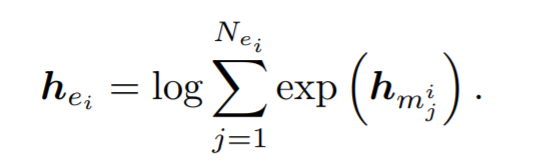
在实验中他有着比mean pooling更好的效果。
二分类器
对于(es eo)的嵌入向量(hes heo)将他们映射到隐藏层的状态z,然后使用双线性计算关系r的概率。
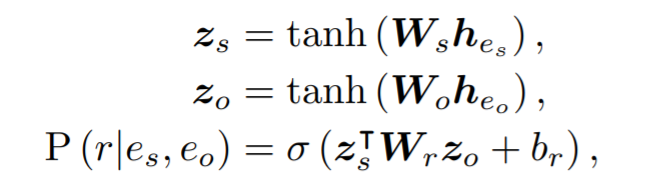
为了减少双线性计算时需要更新的参数,可以使用组bilinearr (Zheng et al. 2019; Tang et al. 2020b),即不是对于一个一个的z进行计算,而是对于一组一组的z机型计算。
适应性二值化
RE分类器输入的时一个实体对之间的关系时r的概率。我们需要对这个【0,1】的概率二值化为是还是不是这个label。
一般选取阈值的办法是通过枚举的方法 看哪个值使得F1更大。但是这种方法对于另一种实体对得到的结果就不一定是最好的。
我们可以通过一个可学习的,适应性的阈值来替换原来固定的一个全局阈值。首先将实体对T划分为正例和负例。
正例表示T之间存在的关系
负例表示R之间不存在的关系
如果一个实体对被分类正确了,那么出现在正例中的logit都要比阈值大,而出现在负例中的样本都应该比阈值小。
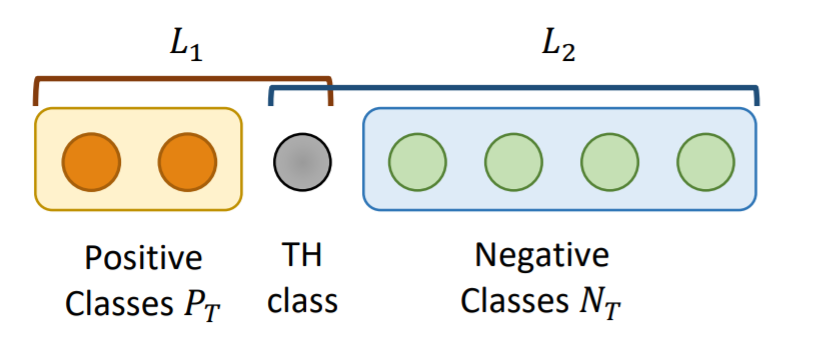
如图所示,又定义了一个新的类TH 他是阈值类,这就是可以自适应调整的阈值。
损失函数计算的公式为,这里将交叉熵拆分为了2个部分
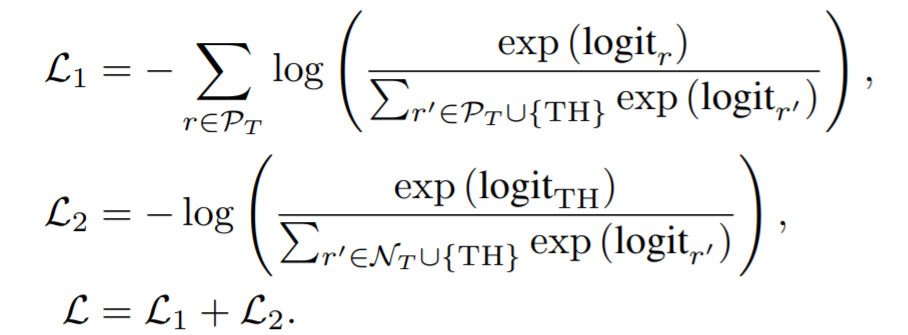
第一个部分L1包含了正确分类的损失和THclass。因为可能有多个正例,所以总的损失是所有正例的加和。s(Menon et al. 2019; Reddi et al. 2019).
否则它将被分为L2
临近内容池化
池化可以将同一个实体的所有嵌入合到一起。但是如何仅仅使用加和的方法,其中一些实体对是没有关系的,所以我们得到的信息是冗余的。所以,做好的方法是值关注那些有用的实体对的信息。
所以这里提出了一种临近内容池化的方法。首先使用transformer-based的模型作为编码器。(可以获取到token级别的依赖关系,通过多头自注意力)(Vaswani et al. 2017)。
然后直接使用attension heads来做池化。这个方法是直接转换了已经训练好的token而没有学信新的attension。
特殊的,Aijk代表注意力从tokenj到token k在i个attension head。首先,选择带有*符号的attion作为mention-level的attension,然后去相同实体menstion-level的平均得到entity级别的attion Aie。接着,对于实体对(es,e0)我们确定一个局部的上下文对于两个实体都很总要的内容,使用注意力机制,得到临近嵌入c(s,o)
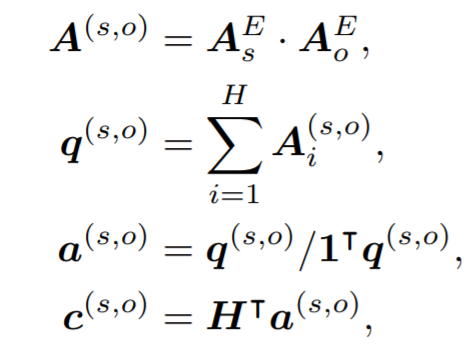
其中计算c的H是通过公式
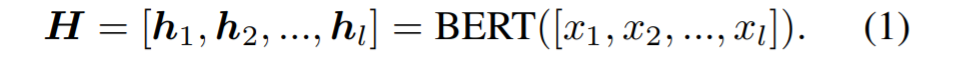
利用bert获得的。
最后
以上就是传统世界最近收集整理的关于Document-Level Relation Extraction with Adaptive Thresholding and Localized Context Pooling问题的建模对于bert baseline的加强适应性二值化临近内容池化的全部内容,更多相关Document-Level内容请搜索靠谱客的其他文章。








发表评论 取消回复