【论文阅读ACL2020】Multi-Cell Compositional LSTM for NER Domain Adaptation
- 一、研究背景
- 二、研究目的
- 三、模型结构
- 1. Baseline LSTM
- 2. Multi-Cell Compositional LSTM
- Entity typed LSTM cells (ET cells):
- Compositional LSTM cell (C cell)
- Merging
- 四、任务训练
- Entity type prediction
- Attention score
- NER
- UDA
- 辅助任务
- LM模型
- 五、loss计算
- SDA loss
- UDA loss
论文链接:https://www.aclweb.org/anthology/2020.acl-main.524.pdf
一、研究背景
跨域 NER 是一个很重要研究的问题。实体的表现可以在不同的领域中高度不同。然而,实体类型之间的相关性在跨域中可以相对更稳定。我们研究了一种用于多任务学习的多单元组成式LSTM结构,用一个单独的单元状态对每个实体类型进行建模。在实体类型单元的帮助下,可以在实体类型层面进行跨域知识转移。理论上,由此产生的每个实体类型的不同特征分布使其在跨域转移方面更加强大。
二、研究目的
1.NER的挑战性在于不同的上下文中,实体识别可能会不同。
2.现在CrossNER的三大挑战
- 相同的实体类型在不同的领域中是不同的
– political new domain :PER 标签典型人物是‘Trump’和‘Clinton’
– sport domain:PER 标签典型人物是‘James’和‘Trout’ - 不同类型的实体在不同领域中表现出不同程度的不同
– location names共享在political news domain和the sports domain,例如“Barcelona” and “Los Angeles”
– organization names 在不同的领域是不同的 - 实体的类型在各个域中是不同的
– 医疗领域的疾病、药物等实体类型,而在生物领域的基因、蛋白质等实体类型
本文提出muti-cell compositional LSTM结构通过在处理一个句子时,同时考虑每个单词的所有实体类型来解决以上的挑战
三、模型结构
1. Baseline LSTM
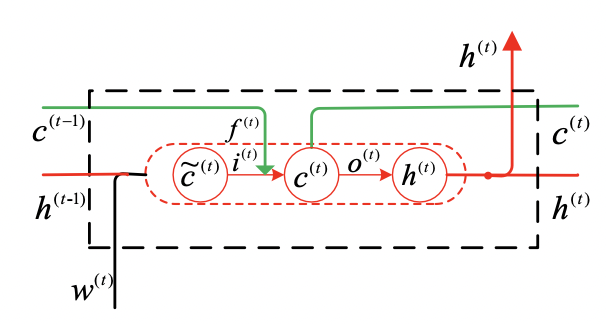
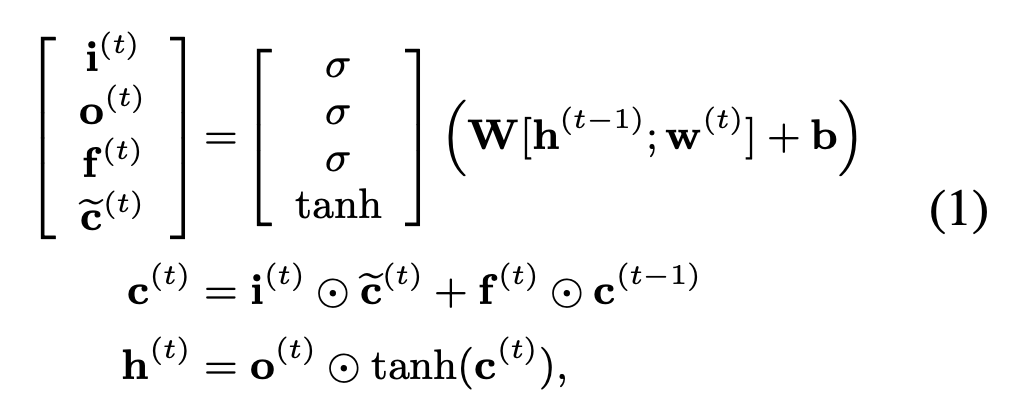
i(t) 为input gate, O(t) output gate , f(t) forget gate
2. Multi-Cell Compositional LSTM
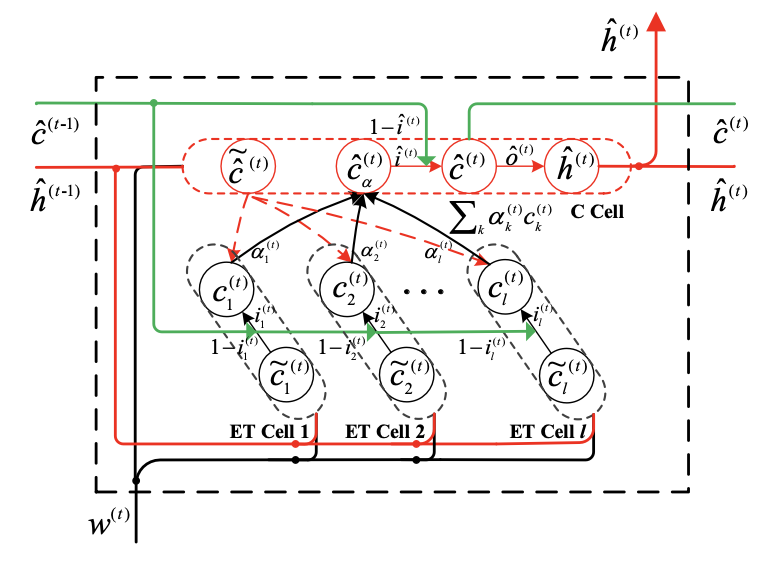
我们将根据上一时刻计算得到的临时细胞状态,分为L类(实体的类型数),也就是图中的ET Cell(Entity typed LSTM cells ),ET Cell的权重分配是根据当前的上下文计算的(即临时细胞状态),最后我们将这些ET Cell进行融合到一个细胞状态中来计算最后的hidden state。下面分别介绍一下各个模块:
Entity typed LSTM cells (ET cells):
给定当前单词w(t) 以及前一时刻的隐状态h(t-1) 计算当前实体类型的input gate和 temporary memory cell :
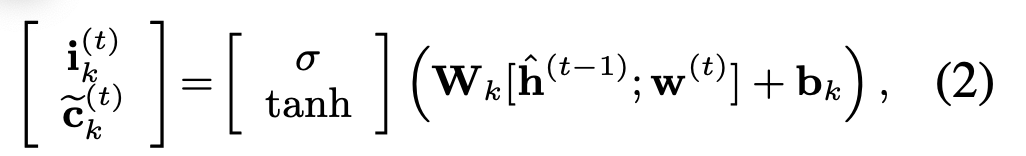
利用上一个时间步的细胞状态C(t-1) 复制L次来更新当前细胞的临时细胞状态:
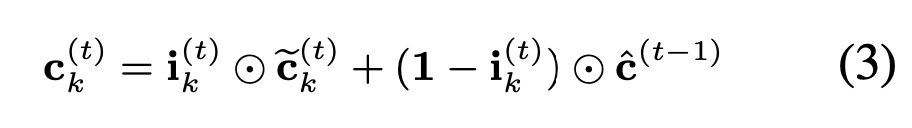
我们最后得到一个ET Cell状态![]()
Compositional LSTM cell (C cell)
给定当前单词w(t) 以及前一时刻的隐状态h(t-1) 计算input gate和 temporary memory cell,还有output gate:
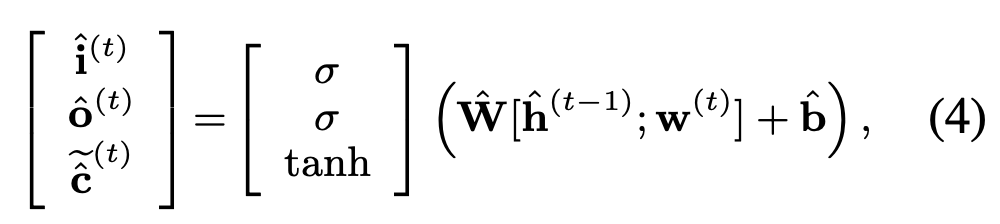
Merging
我们利用C Cell的临时细胞状态来计算ET Cell各个类别的权重:
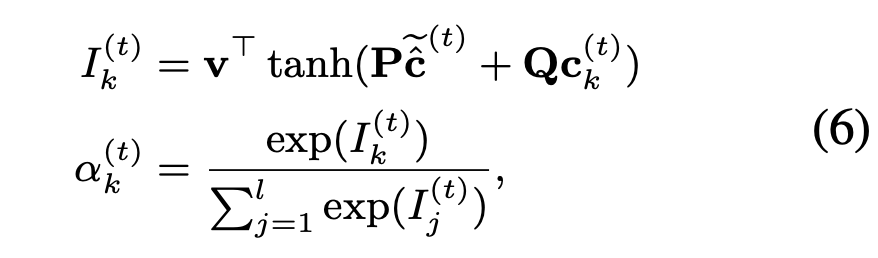
根据各个类别的权重来融合ET Cell 的细胞状态到一个细胞中:
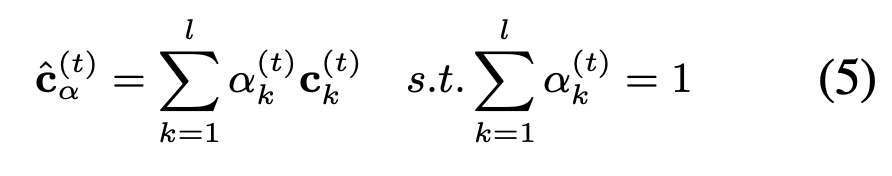
然后对融合后的细胞进行更新:
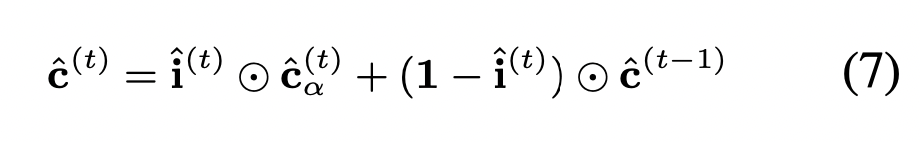
计算最后的隐状态:
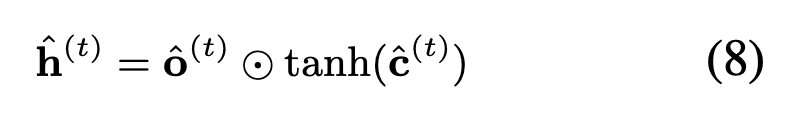
四、任务训练
为了更好地从带标签的数据中提取实体类型知识去训练ET Cell和C Cell,本文设置两个辅助任务:
Entity type prediction
给定当前词xt的 ET Cell的细胞序列:
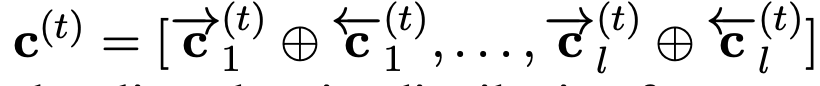
我们定义基于当前词的实体分布如下:
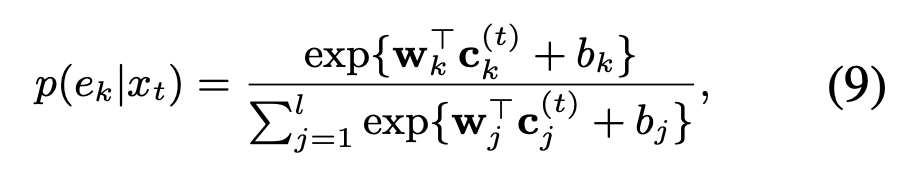
任务的loss为:
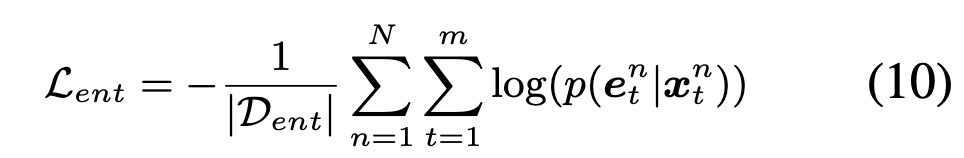
Attention score
给定当前词xt的 ET Cell 和 C Cell 的attention score序列:
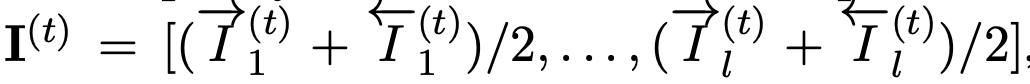
我们利用attention score 对齐当前词的实体分布:
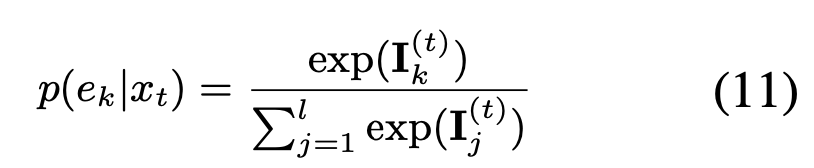
任务loss:
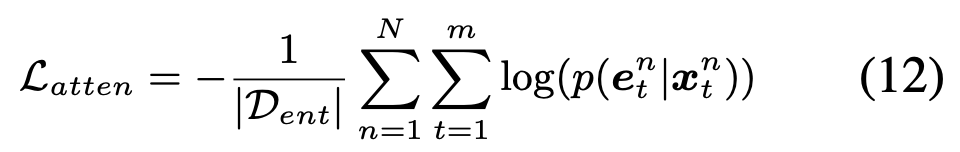
NER
给定一句话的隐状态序列:
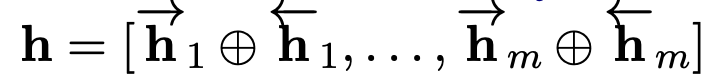
通过CRF计算在该隐状态下的最大可能路径:
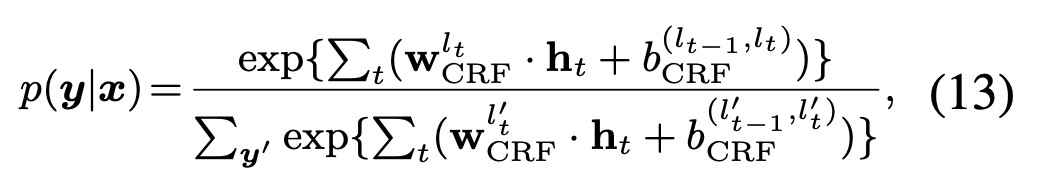
任务loss:
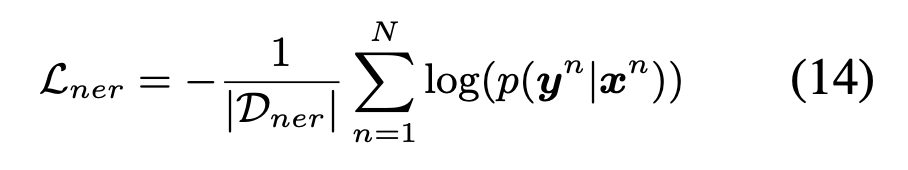
UDA
辅助任务
为了更好的提取实体知识,我们使用预先收集的命名实体字典De来标注 T,得到一组实体词D+ 用于联合训练实体预测任务和注意评分任务
LM模型
前向和后向LM probability
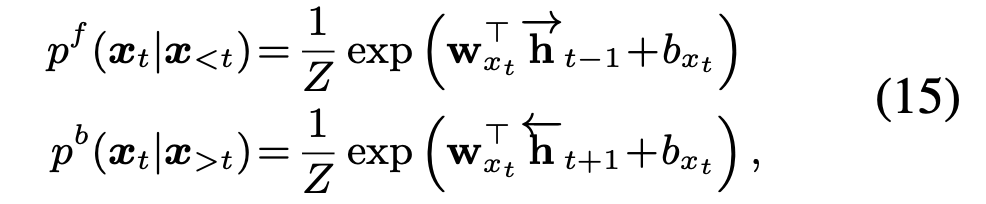
任务loss:
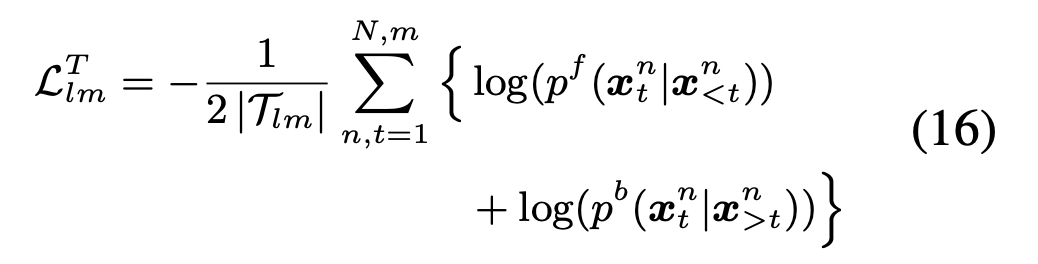
五、loss计算
SDA loss
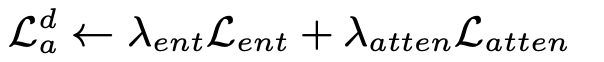
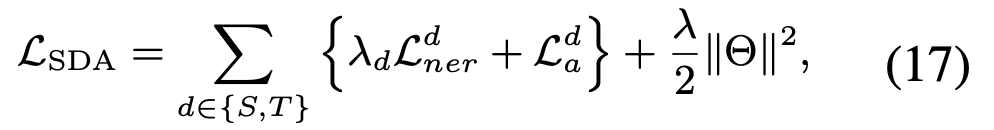
UDA loss
最后
以上就是诚心白云最近收集整理的关于【论文阅读ACL2020】Multi-Cell Compositional LSTM for NER Domain Adaptation的全部内容,更多相关【论文阅读ACL2020】Multi-Cell内容请搜索靠谱客的其他文章。








发表评论 取消回复