windows下使用python的scrapy爬虫框架,爬取个人博客文章内容信息
scrapy作为流行的python爬虫框架,简单易用,这里简单介绍如何使用该爬虫框架爬取个人博客信息。关于python的安装和scrapy的安装配置请读者自行查阅相关资料,或者也可以关注我后续的内容。
本文使用的python版本为2.7.9 scrapy版本为0.14.3
1.假设我们爬虫的名字为vpoetblog
在命令行下切换到桌面目录,输入startproject scrapy vpoetblog 如下图所示:

命令执行成功后会在桌面生成一个名为vpoetblog的文件夹
该文件夹的目录为:
│ scrapy.cfg
│
└─vpoetblog
│ items.py
│ pipelines.py
│ settings.py
│ __init__.py
│
└─spiders
__init__.py│ scrapy.cfg
│ data.txt //用于保存抓取到的数据
└─doubanmoive
│ items.py //用于定义抓取的item
│ pipelines.py //用于将抓取的数据进行保存
│ settings.py
│ __init__.py
│
└─spiders blog_spider.py //主爬虫函数 用于定义抓取规则等
__init__.py
items.py内容如下:
# -*- coding: cp936 -*-
from scrapy.item import Item, Field
class VpoetblogItem(Item):
# define the fields for your item here like:
# name = Field()
article_name = Field() #文章名字
public_time = Field() #发表时间
read_num = Field() #阅读数量
pipelines.py内容如下:
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from scrapy.exceptions import DropItem
from scrapy.conf import settings
from scrapy import log
class Pipeline(object):
def __init__(self):
print 'abc'
def process_item(self, item, spider):
#Remove invalid data
#valid = True
#for data in item:
#if not data:
#valid = False
#raise DropItem("Missing %s of blogpost from %s" %(data, item['url']))
#print 'crawl no data.....n'
#if valid:
#Insert data into txt
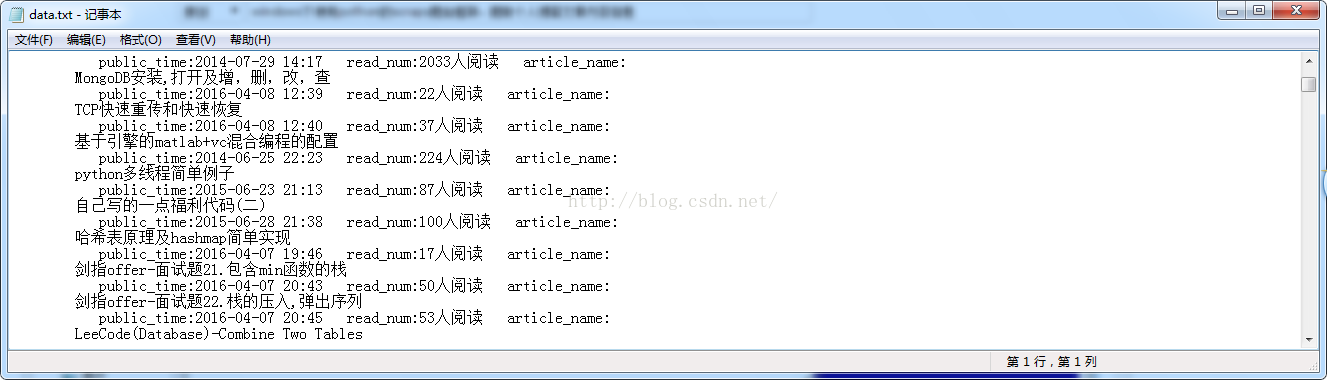
input = open('data.txt', 'a')
input.write('article_name:'+item['article_name'][0]+' ');
input.write('public_time:'+item['public_time'][0]+' ');
input.write('read_num:'+item['read_num'][0]+' ');
input.close()
return item
settings.py内容如下:
# Scrapy settings for vpoetblog project
#
# For simplicity, this file contains only the most important settings by
# default. All the other settings are documented here:
#
# http://doc.scrapy.org/topics/settings.html
#
BOT_NAME = 'vpoetblog'
BOT_VERSION = '1.0'
SPIDER_MODULES = ['vpoetblog.spiders']
NEWSPIDER_MODULE = 'vpoetblog.spiders'
ITEM_PIPELINES={
'vpoetblog.pipelines.Pipeline':300
}
DOWNLOAD_DELAY = 2
RANDOMIZE_DOWNLOAD_DELAY = True
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5'
COOKIES_ENABLED = True
# -*- coding: utf-8 -*-
from scrapy.selector import HtmlXPathSelector
from scrapy.contrib.spiders import CrawlSpider,Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from vpoetblog.items import VpoetblogItem
class MoiveSpider(CrawlSpider):
name="vpoetblog"
allowed_domains=["blog.csdn.net"]
start_urls=["http://blog.csdn.net/u013018721/article/list/1"]
rules=[
Rule(SgmlLinkExtractor(allow=(r'http://blog.csdn.net/u013018721/article/list/d+'))),
Rule(SgmlLinkExtractor(allow=(r'http://blog.csdn.net/u013018721/article/details/d+')),callback="parse_item"),
]
def parse_item(self,response):
sel=HtmlXPathSelector(response)
item=VpoetblogItem()
item['article_name']=sel.select('//*[@class="link_title"]/a/text()').extract()
item['public_time']=sel.select('//*[@class="link_postdate"]/text()').extract()
item['read_num']=sel.select('//*[@class="link_view"]/text()').extract()
return item
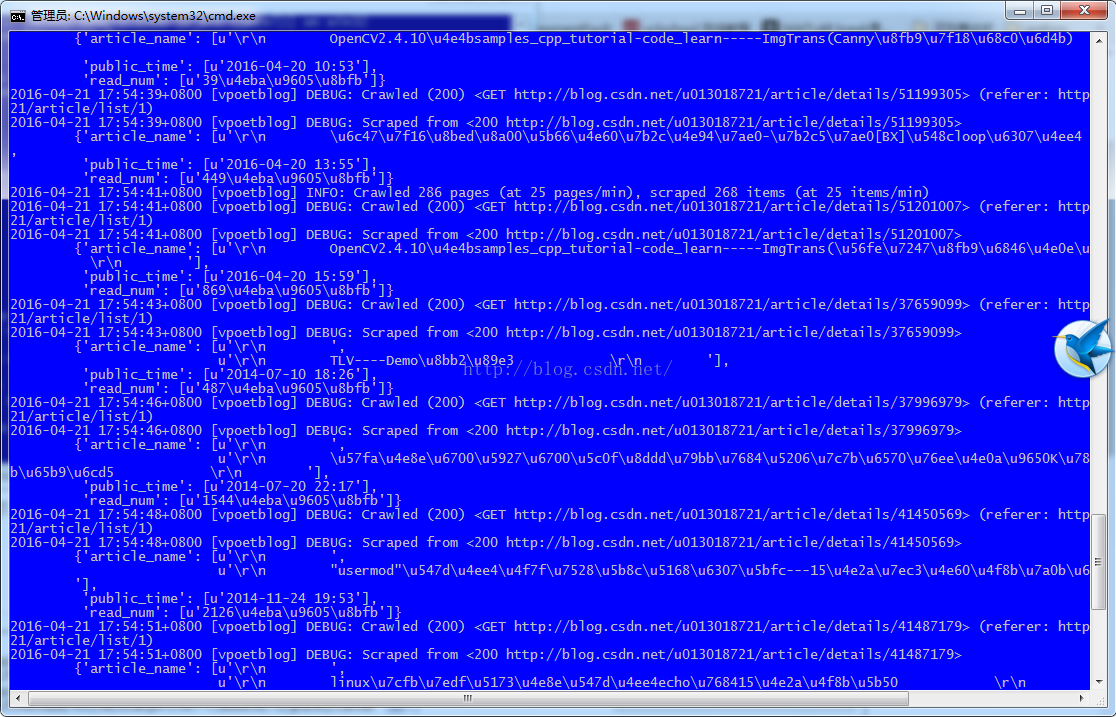
运行命令如下:

运行截图如下:

最后
以上就是独特大叔最近收集整理的关于windows下使用python的scrapy爬虫框架,爬取个人博客文章内容信息的全部内容,更多相关windows下使用python内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复