主要介绍tensorflow.keras 的两个模型
参考 Tensorflow、Keras 官方文档进行学习和整理
Tensorflow 基础知识讲解 Gitee 地址
Tensorflow 基础知识讲解 Github 地址
Sequential 顺序模型
创建模型: model = tf.keras.Sequential()
model.complie() 编译函数用于配置训练模型
compile(optimizer, loss=None, metrics=None, loss_weights=None, sample_weight_mode=None,
weighted_metrics=None, target_tensors=None)
参数:
optimizer: 字符串(优化器名)或者优化器对象。详见 optimizers。
loss: 字符串(目标函数名)或目标函数或 Loss 实例。详见 losses。 如果模型具有多个输出,则可以通过传递损失函数的字典或列表,
在每个输出上使用不同的损失。模型将最小化的损失值将是所有单个损失的总和。
metrics: 在训练和测试期间的模型评估标准。 通常你会使用 metrics = ['accuracy']。要为多输出模型的不同输出指定不同的评估标准,
还可以传递一个字典,如 metrics={'output_a': 'accuracy', 'output_b': ['accuracy', 'mse']}。 你也可以传递一个评
估指标序列的序列 (len = len(outputs)) 例如 metrics=[['accuracy'], ['accuracy', 'mse']] 或
metrics=['accuracy', ['accuracy', 'mse']]。
loss_weights: 指定标量系数(Python浮点数)的可选列表或字典,用于加权不同模型输出的损失贡献。 模型将要最小化的损失值将是所有单
个损失的加权和,由 loss_weights 系数加权。 如果是列表,则期望与模型的输出具有 1:1 映射。 如果是字典,则期望将输出名称(字
符串)映射到标量系数。
sample_weight_mode: 如果你需要执行按时间步采样权重(2D 权重),请将其设置为 temporal。 默认为 None,为采样权重(1D)。如果
模型有多个输出,则可以通过传递 mode 的字典或列表,以在每个输出上使用不同的 sample_weight_mode。
weighted_metrics: 在训练和测试期间,由 sample_weight 或 class_weight 评估和加权的度量标准列表。
target_tensors: 默认情况下,Keras 将为模型的目标创建一个占位符,在训练过程中将使用目标数据。 相反,如果你想使用自己的目标张量
(反过来说,Keras 在训练期间不会载入这些目标张量的外部 Numpy 数据), 您可以通过 target_tensors 参数指定它们。它应该是
单个张量(对于单输出 Sequential 模型)。
**kwargs: 当使用 Theano/CNTK 后端时,这些参数被传入 K.function。
当使用 TensorFlow 后端时,这些参数被传递到 tf.Session.run。
异常
ValueError: 如果 optimizer, loss, metrics 或 sample_weight_mode 这些参数不合法。
model.fit() 训练函数以固定数量的轮次(数据集上的迭代)训练模型
fit(x=None, y=None, batch_size=None, epochs=1, verbose=1, callbacks=None, validation_split=0.0,
validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0,
steps_per_epoch=None, validation_steps=None, validation_freq=1, max_queue_size=10, workers=1,
use_multiprocessing=False)
参数
x: 输入数据。可以是:
一个 Numpy 数组(或类数组),或者数组的序列(如果模型有多个输入)。
一个将名称匹配到对应数组/张量的字典,如果模型具有命名输入。
一个返回 (inputs, targets) 或 (inputs, targets, sample weights) 的生成器或 keras.utils.Sequence。
None(默认),如果从本地框架张量馈送(例如 TensorFlow 数据张量)。
y: 目标数据。它可以是:
Numpy 数组(序列)、 本地框架张量(序列)、Numpy数组序列(如果模型有多个输出)
None(默认)如果从本地框架张量馈送(例如 TensorFlow 数据张量)。
如果模型输出层已命名,你也可以传递一个名称匹配Numpy 数组的字典。
如果 x 是一个生成器,或 keras.utils.Sequence 实例,则不应该 指定 y(因为目标可以从 x 获得)。
batch_size: 整数或 None。每次梯度更新的样本数。如果未指定,默认为 32。
如果你的数据是符号张量、生成器或 Sequence 实例形式,不要指定 batch_size, 因为它们会生成批次。
epochs: 整数。训练模型迭代轮次。一个轮次是在整个 x 或 y 上的一轮迭代。
请注意,与 initial_epoch 一起,epochs 被理解为「最终轮次」。
模型并不是训练了 epochs 轮,而是到第 epochs 轮停止训练。
verbose: 整数,0, 1 或 2。日志显示模式。 0 = 安静模式, 1 = 进度条, 2 = 每轮一行。
callbacks: 一系列的 keras.callbacks.Callback 实例。一系列可以在训练和验证(如果有)时使用的回调函数。 详见 callbacks。
validation_split: 0 和 1 之间的浮点数。用作验证集的训练数据的比例。 模型将分出一部分不会被训练的验证数据,
并将在每一轮结束时评估这些验证数据的误差和任何其他模型指标。 验证数据是混洗之前 x 和y 数据的最后一部分样本中。
这个参数在 x 是生成器或 Sequence 实例时不支持。
validation_data: 用于在每个轮次结束后评估损失和任意指标的数据。 模型不会在这个数据上训练。
validation_data 会覆盖 validation_split。 validation_data 可以是:
元组 (x_val, y_val) 或 Numpy 数组或张量
元组 (x_val, y_val, val_sample_weights) 或 Numpy 数组。
数据集或数据集迭代器。
对于前两种情况,必须提供 batch_size。 对于最后一种情况,必须提供 validation_steps。
shuffle: 布尔值(是否在每轮迭代之前混洗数据)或者字符串 (batch)。 batch 是处理 HDF5 数据限制的特殊选项,
它对一个 batch 内部的数据进行混洗。 当 steps_per_epoch 非 None 时,这个参数无效。
class_weight: 可选的字典,用来映射类索引(整数)到权重(浮点)值,用于加权损失函数(仅在训练期间)。
这可能有助于告诉模型来自代表性不足的类的样本。
sample_weight: 训练样本的可选 Numpy 权重数组,用于对损失函数进行加权(仅在训练期间)。
你可以传递与输入样本长度相同的平坦(1D)Numpy 数组(权重和样本之间的 1:1 映射),
或者在时序数据的情况下,可以传递尺寸为 (samples, sequence_length) 的 2D 数组,以对每个样本的每个时间步施加不同的权重。
在这种情况下,你应该确保在 compile() 中指定 sample_weight_mode="temporal"。
这个参数在 x 是生成器或 Sequence 实例时不支持,应该提供 sample_weights 作为 x 的第 3 元素。
initial_epoch: 整数。开始训练的轮次(有助于恢复之前的训练)。
steps_per_epoch: 整数或 None。 在声明一个轮次完成并开始下一个轮次之前的总步数(样品批次)。
使用 TensorFlow 数据张量等输入张量进行训练时,默认值 None 等于数据集中样本的数量除以 batch 的大小,如果无法确定,则为 1。
validation_steps: 只有在提供了 validation_data 并且是一个生成器时才有用。 表示在每个轮次结束时执行验证时,
在停止之前要执行的步骤总数(样本批次)。
validation_freq: 只有在提供了验证数据时才有用。整数或列表/元组/集合。
如果是整数,指定在新的验证执行之前要执行多少次训练,例如,validation_freq=2 在每 2 轮训练后执行验证。
如果是列表、元组或集合,指定执行验证的轮次,例如,validation_freq=[1, 2, 10] 表示在第 1、2、10 轮训练后执行验证。
max_queue_size: 整数。仅用于生成器或 keras.utils.Sequence 输入。 生成器队列的最大尺寸。
若未指定,max_queue_size 将默认为 10。
workers: 整数。仅用于生成器或 keras.utils.Sequence 输入。 当使用基于进程的多线程时的最大进程数。
若未指定,workers 将默认为 1。若为 0,将在主线程执行生成器。
use_multiprocessing: 布尔值。仅用于生成器或 keras.utils.Sequence 输入。 如果是 True,使用基于进程的多线程。
若未指定,use_multiprocessing 将默认为 False。 注意由于这个实现依赖于 multiprocessing,
你不应该像生成器传递不可选的参数,因为它们不能轻松地传递给子进程。
**kwargs: 用于向后兼容。
返回
一个 History 对象。其 History.history 属性是连续 epoch 训练损失和评估值,以及验证集损失和评估值的记录(如果适用)。
异常
RuntimeError: 如果模型从未编译。
ValueError: 在提供的输入数据与模型期望的不匹配的情况下。
model.evaluate() 评估函数返回误差值和评估标准值
evaluate(x=None, y=None, batch_size=None, verbose=1, sample_weight=None, steps=None,
callbacks=None, max_queue_size=10, workers=1, use_multiprocessing=False)
参数:
x: 输入数据。可以是:
一个 Numpy 数组(或类数组),或者数组的序列(如果模型有多个输入)。
一个将名称匹配到对应数组/张量的字典,如果模型具有命名输入。
一个返回 (inputs, targets) 或 (inputs, targets, sample weights) 的生成器或 keras.utils.Sequence。
None(默认),如果从本地框架张量馈送(例如 TensorFlow 数据张量)。
y: 目标数据。与输入数据 x 类似,它可以是 Numpy 数组(序列)、 本地框架张量(序列)、Numpy数组序列(如果模型有多个输出)
或 None(默认)如果从本地框架张量馈送(例如 TensorFlow 数据张量)。 如果模型输出层已命名,你也可以传递一个名称匹配
Numpy 数组的字典。 如果 x 是一个生成器,或 keras.utils.Sequence 实例,则不应该 指定 y(因为目标可以从 x 获得)。
batch_size: 整数或 None。每次梯度更新的样本数。如果未指定,默认为 32。 如果你的数据是符号张量、生成器或 Sequence 实例形式,
不要指定 batch_size, 因为它们会生成批次。
verbose: 0, 1。日志显示模式。0 = 安静模式, 1 = 进度条。
sample_weight: 训练样本的可选 Numpy 权重数组,用于对损失函数进行加权。 你可以传递与输入样本长度相同的平坦(1D)Numpy 数组
(权重和样本之间的 1:1 映射), 或者在时序数据的情况下,可以传递尺寸为 (samples, sequence_length) 的 2D 数组,以对每
个样本的每个时间步施加不同的权重。 在这种情况下,你应该确保在 compile() 中指定 sample_weight_mode="temporal"。
steps: 整数或 None。 声明评估结束之前的总步数(批次样本)。默认值 None 时被忽略。
callbacks: 一系列的 keras.callbacks.Callback 实例。一系列可以在评估时使用的回调函数。 详见 callbacks。
max_queue_size: 整数。仅用于生成器或 keras.utils.Sequence 输入。
生成器队列的最大尺寸。若未指定,max_queue_size 将默认为 10。
workers: 整数。仅用于生成器或 keras.utils.Sequence 输入。 当使用基于进程的多线程时的最大进程数。
若未指定,workers 将默认为 1。若为 0,将在主线程执行生成器。
use_multiprocessing: 布尔值。仅用于生成器或 keras.utils.Sequence 输入。 如果是 True,使用基于进程的多线程。
若未指定,use_multiprocessing 将默认为 False。 注意由于这个实现依赖于 multiprocessing,你不应该像生成器传递
不可选的参数,因为它们不能轻松地传递给子进程。
异常
ValueError: 若参数非法。
返回
标量测试误差(如果模型只有单个输出且没有评估指标)或标量列表(如果模型具有多个输出和/或指标)。
属性 model.metrics_names 将提供标量输出的显示标签。
mdoel.predict() 预测函数通过输入样本生成输出预测
predict(x, batch_size=None, verbose=0, steps=None, callbacks=None, max_queue_size=10,
workers=1, use_multiprocessing=False)
参数
x: 输入数据。可以是:
一个 Numpy 数组(或类数组),或者数组的序列(如果模型有多个输入)。
一个将名称匹配到对应数组/张量的字典,如果模型具有命名输入。
一个返回 (inputs, targets) 或 (inputs, targets, sample weights) 的生成器或 keras.utils.Sequence。
None(默认),如果从本地框架张量馈送(例如 TensorFlow 数据张量)。
batch_size: 整数或 None。每次梯度更新的样本数。如果未指定,默认为 32。 如果你的数据是符号张量、生成器或 Sequence 实例形式,
不要指定 batch_size, 因为它们会生成批次。
verbose: 日志显示模式,0 或 1。
steps: 声明预测结束之前的总步数(批次样本)。默认值 None 时被忽略。
callbacks: 一系列的 keras.callbacks.Callback 实例。一系列可以在预测时使用的回调函数。 详见 callbacks。
max_queue_size: 整数。仅用于生成器或 keras.utils.Sequence 输入。 生成器队列的最大尺寸。
若未指定,max_queue_size 将默认为 10。
workers: 整数。仅用于生成器或 keras.utils.Sequence 输入。 当使用基于进程的多线程时的最大进程数。
若未指定,workers 将默认为 1。若为 0,将在主线程执行生成器。
use_multiprocessing: 布尔值。仅用于生成器或 keras.utils.Sequence 输入。 如果是 True,使用基于进程的多线程。
若未指定,use_multiprocessing 将默认为 False。 注意由于这个实现依赖于 multiprocessing,你不应该像生成器传递不可选
的参数,因为它们不能轻松地传递给子进程。
返回
预测的 Numpy 数组。
异常
ValueError: 如果提供的输入数据与模型的期望数据不匹配,或者有状态模型收到的数量不是批量大小的倍数。
一个案例
# 完整的Keras Sequential 顺序模型
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
# 生成虚拟数据
x_train = np.random.random((1000, 20))
y_train = np.random.randint(2, size=(1000, 1))
x_test = np.random.random((100, 20))
y_test = np.random.randint(2, size=(100, 1))
# model 构建
model = Sequential()
# 添加神经网络层
model.add(Dense(64, input_dim=20, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
# model.complile() 函数用于模型编译
model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
# model.fit() 函数用于模型训练
model.fit(x_train, y_train, epochs=20, batch_size=128)
# model.evaluate() 函数用于模型评估
score = model.evaluate(x_test, y_test, batch_size=128)
# model.predict() 函数用于预测
result = model.predict(x_test)
Function API 模型
# 在函数式 API 中,自己需要给定一些输入张量和输出张量,可以通过以下方式实例化一个 Model:
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
# 这个模型将包含从 a 到 b 的计算的所有网络层。
a = Input(shape=(32,))
b = Dense(32)(a)
model = Model(inputs=a, outputs=b)
# 在多输入或多输出模型的情况下,也可以使用列表:
model = Model(inputs=[a1, a2], outputs=[b1, b3, b3])
函数式 API 的 Model 类模型对应函数参数可以参考 model.Sequential() 顺序模型:model.compile(), model.fit(), mdoel.evaluate(), model.predict()
一个例子
以下是函数式 API 的一个很好的例子:具有多个输入和输出的模型。函数式 API 使处理大量交织的数据流变得容易。 在这个例子中,我们试图预测 Twitter
上的一条新闻标题有多少转发和点赞数。模型的主要输入将是新闻标题本身,即一系列词语, 但是为了增添趣味,我们的模型还添加了其他的辅助输入来接收额外的数据,例如新闻标题的发布的时间等。
该模型也将通过两个损失函数进行监督学习。较早地在模型中使用主损失函数(参见loss部分内容),是深度学习模型的一个良好正则方法。
模型结构如下图所示: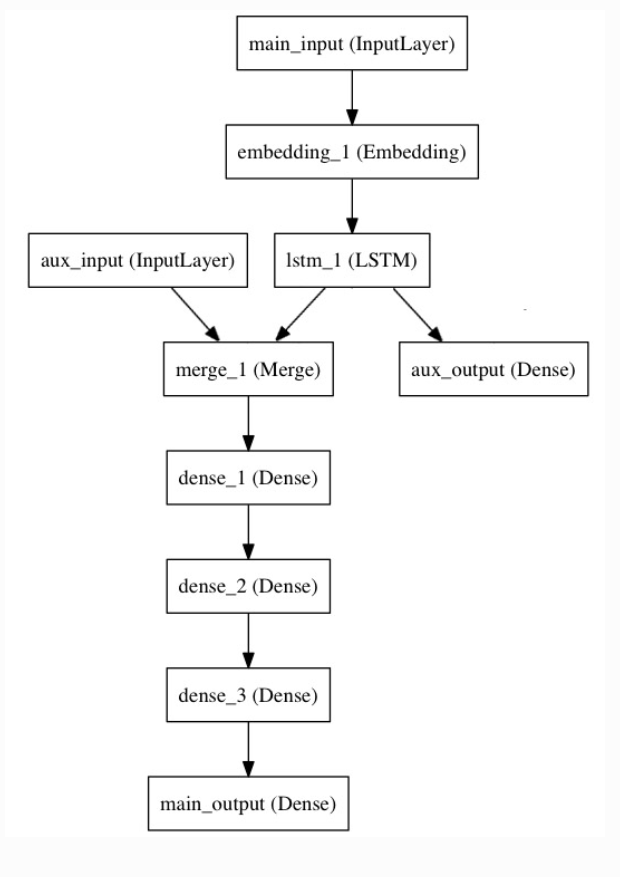
# Coding
import tensorflow as tf
from tensorflow.keras.layers import Input, Embedding, LSTM, Dense
from tensorflow.keras.models import Model
import numpy as np
np.random.seed(0) # 设置随机种子,用于复现结果
# 创建数据
headline_data = np.round(np.abs(np.random.rand(12, 100) * 100))
additional_data = np.random.randn(12, 5)
headline_labels = np.random.randn(12, 1)
additional_labels = np.random.randn(12, 1)
# 开始构建模型网络
# 输入层:通过标题输入,接收一个含有 100 个整数的序列,每个整数在 1 到 10000 之间, 在这里可以通过传递一个 "name" 参数来命名任何层。
main_input = Input(shape=(100,), dtype='int32', name='main_input')
# Embedding 层将输入序列编码为一个稠密向量的序列,每个向量维度为 512。 该层为模型中的:embedding_1(Embedding)
embedding_out = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input)
# LSTM 层把向量序列转换成单个向量,它包含整个序列的上下文信息
lstm_out = LSTM(32)(embedding_out)
# 插入辅助损失,使得即使在模型主损失很高的情况下,LSTM 层和 Embedding 层都能被平稳地训练。该层为模型中的:aux_output(Dense)
aux_output = Dense(1, activation='sigmoid', name='aux_output')(lstm_out)
# 辅助输入数据与 LSTM 层的输出连接起来,输入到模型中,该层为模型中的:aux_input(InputLayer)
aux_input = Input(shape=(5,), name='aux_input')
# 模型中的:merge_1(Merge) 将辅助输入数据与 LSTM 层的输出连接起来
merge_out = tf.keras.layers.concatenate([lstm_out, aux_input])
# 堆叠多个全连接网络层模型中的:dense_1, dense_2, dense_3
dense1 = Dense(64, activation='relu')(merge_out)
dense2 = Dense(64, activation='relu')(dense1)
dense3 = Dense(64, activation='relu')(dense2)
# 最后添加主要的逻辑回归层, 模型中的 main_output(Dense)
main_output = Dense(1, activation='sigmoid', name='main_output')(dense3)
# 定义一个具有两个输入和两个输出的模型
model = Model(inputs=[main_input, aux_input], outputs=[main_output, aux_output])
# 模型编译,训练,预测
model.compile(optimizer='rmsprop', loss='binary_crossentropy', loss_weights=[1., 0.2])
model.fit([headline_data, additional_data], [headline_labels, additional_labels], epochs=50, batch_size=32)
pred = model.predict([headline_data, additional_data])
# 由于输入和输出均被命名了(在定义时传递了一个 name 参数),我们也可以通过以下方式编译模型:
# model.compile(optimizer='rmsprop',
# loss={'main_output': 'binary_crossentropy', 'aux_output': 'binary_crossentropy'},
# loss_weights={'main_output': 1., 'aux_output': 0.2})
# model.fit({'main_input': headline_data, 'aux_input': additional_data},
# {'main_output': headline_labels, 'aux_output': additional_labels},
# epochs=50, batch_size=32)
# model.predict({'main_input': headline_data, 'aux_input': additional_data})
最后
以上就是酷酷黑裤最近收集整理的关于Tensorflow.keras 两个模型的全部内容,更多相关Tensorflow.keras内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。






![[Python人工智能] 三十六.基于Transformer的商品评论情感分析 (2)keras构建多头自注意力(Transformer)模型](https://www.shuijiaxian.com/files_image/reation/bcimg16.png)

发表评论 取消回复