一、传统的提高计算速度的方法
- faster clocks (设置更快的时钟)
- more work over per clock cycle(每个时钟周期做更多的工作)
- more processors(更多处理器)
二、CPU & GPU
- CPU更加侧重执行时间,做到延时小
- GPU则侧重吞吐量,能够执行大量的计算
更形象的理解就是假如我们载一群人去北京,CPU就像那种敞篷跑车一样速度贼快,但是一次只能坐两个人,而GPU就像是大巴车一样,虽然可能速度不如跑车,但是一次能载超多人。
总结起来相比于CPU,GPU有如下特点:
- 有很多计算单元,可以在一起执行大量的计算
- 显示并行计算模型(explicitly parallel programming model),这个会在后面深度讨论
- GPU是对吞吐量进行优化,而不是吞吐量
三、cuda登场
以前我们所写的代码都只能运行在CPU上,那么如果想运行在GPU上该怎么实现呢?
这时候就需要CUDA大大登场了!!!
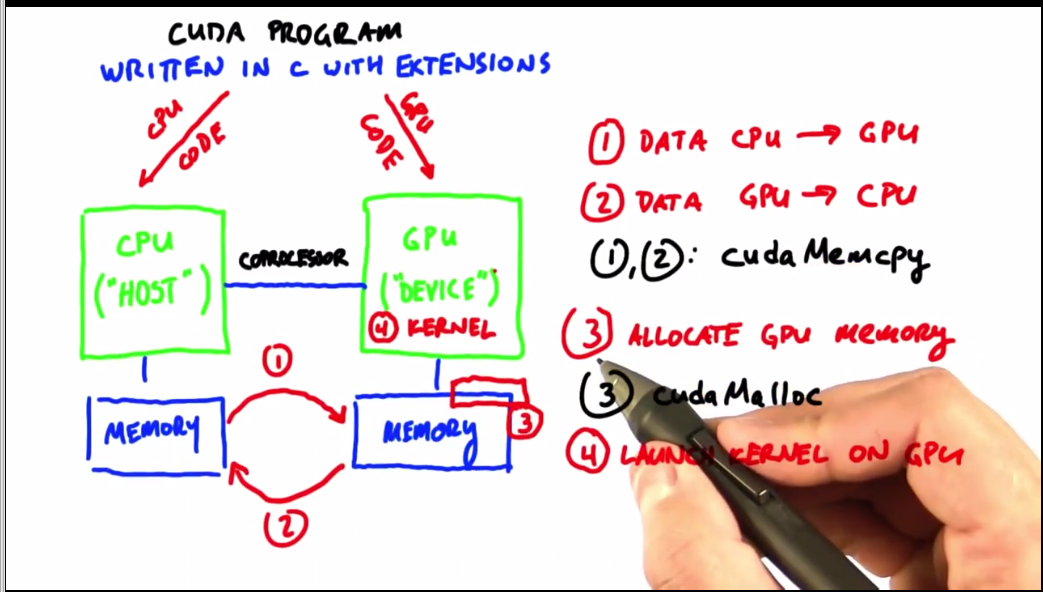
cuda执行原理是CPU运行主程序,向GPU发送指示告诉它该做什么,那么系统就需要做如下的事情:
- 1.把CPU内存中的数据转移到GPU的内存中
- 2.将数据从GPU移回CPU
(把数据从一个地方移到另一个地方命令为cudaMemcpy) - 3.在GPU上分配内存,在C语言中该命令是malloc,而在cuda中则是cudaMalloc
- 4.在GPU上调用以并行方式计算的程序,这些程序叫做内核。
练习题:GPU可以做如下哪些事?

正确选项解释:
- 选项2:回应CPU发来的请求,即对应上面的步骤2——将数据从GPU移回CPU
- 选项4:回应CPU发来的请求,即对应上面的步骤1——把CPU内存中的数据转移到GPU的内存中
- 选项5:计算由CPU调用的内核运算。
四、A CUDA Program
典型的GPU算法流程:
- CPU在GPU上分配存储空间(cudaMalloc)
- CPU将输入数据拷贝到GPU(cudaMemcpy)
- CPU调用某些内核来监视这些在GPU上处理这个数据的内核(kernel launch)
- CPU将GPU计算得到的结果复制回CPU(cudaMemcpy)
五、定义GPU计算
GPU能做的事是:
- 有效的启动大量线程
- 并行的运行上面启动的大量线程,而不是运行一个有很多并行工作的线程,也不是运行一个线程更加快速。

六、CPU&GPU计算原理区别
下面将计算数组[0,1,2……,63]每个元素平方来比较CPU和GPU计算原理的区别,以及具体代码实现。
CPU
for(i=0;i<64;i++){
out[i] = in[i] * in[i];
}该段代码在CPU中执行,只有一个线程,它会循环64次,每次迭代做一个计算。
GPU
实现代码:
#include <stdio.h>
__global__ void cube(float * d_out, float * d_in){
// Todo: Fill in this function
}
int main(int argc, char ** argv) {
const int ARRAY_SIZE = 64;
const int ARRAY_BYTES = ARRAY_SIZE * sizeof(float);
// generate the input array on the host
float h_in[ARRAY_SIZE];
for (int i = 0; i < ARRAY_SIZE; i++) {
h_in[i] = float(i);
}
float h_out[ARRAY_SIZE];
// declare GPU memory pointers
float * d_in;
float * d_out;
// allocate GPU memory
cudaMalloc((void**) &d_in, ARRAY_BYTES);
cudaMalloc((void**) &d_out, ARRAY_BYTES);
// transfer the array to the GPU
cudaMemcpy(d_in, h_in, ARRAY_BYTES, cudaMemcpyHostToDevice);
// launch the kernel
cube<<<1, ARRAY_SIZE>>>(d_out, d_in);
// copy back the result array to the CPU
cudaMemcpy(h_out, d_out, ARRAY_BYTES, cudaMemcpyDeviceToHost);
// print out the resulting array
for (int i =0; i < ARRAY_SIZE; i++) {
printf("%f", h_out[i]);
printf(((i % 4) != 3) ? "t" : "n");
}
cudaFree(d_in);
cudaFree(d_out);
return 0;
}代码拆解分析:
1.变量命名规则
在编写cuda代码时,需要遵守如下规则,这样可以避免犯不必要的错误。
CPU的变量以h_开头(host),而GPU的变量以d_开头(device)。
2.定义内核函数
__global__ void square(float *d_out, float *d_in){
int idx = threadIdx.x;
float f = d_in[idx];
d_out[idx] = f * f;
}通过 global 定义的函数可以让cuda知道这是一个内核函数。
函数第一行作用是通过内置的线程索引threadIdx获得当前线程的索引。另外threadIdx是c语言中的struct,它有3名成员,分别是 .x,.y,.z 。如果该线程是第一个线程,则threadIdx.x返回的值是0。
3.数据转移cudaMemcpy
代码片段
// 将数据转移到GPU
cudaMemcpy(d_in, h_in, ARRAY_BYTES, cudaMemcpyHostToDevice);
// 调用内核
square<<<1, ARRAY_SIZE>>>(d_out, d_in);
// 将结果传回CPU
cudaMemcpy(h_out, d_out, ARRAY_BYTES, cudaMemcpyDeviceToHost);注意下面函数的第三个参数direction有三种选项:
cudaMemcpy(destination, source, size, direction)分别是:
- cudaMemcpyHostToDevice
- cudaMemcpyDeviceToHost
- cudaMemcpyDeviceToDevice
4.调用内核 square<<<1, 64>>>
另外在解释一下如上函数各参数的含义:
第一个参数1表示需要分配的块的数量为1,
第二个参数64表示每一块有64个线程。
所以假设我们需要1280个线程,我们就可以这样定义:
square<<<10,128>>>(param1, param2);或者
square<<<5,256>>>(param1, param2);BUT!!! 要注意不能像下面这样定义,因为一个块的线程数一般没那么大,一般只有1024.
square<<<1,1280>>>(param1, param2);还需要知道的是上面介绍的两个参数其实可以是二维或者三维的,即
square<<<1,64>>> 等效为 square<<<dim3(1,1,1),dim3(64,1,1)>>> ,但是dim3(64,1,1)=dim3(64)=64。
例如我们有一个128*128的图片,现在需要对每一个像素进行计算,我们可以是
<<<dim3(128,1,1),(128,1,1)>>>,也可以是<<<dim3(8,8,1),dim3(16,16,1)>>>
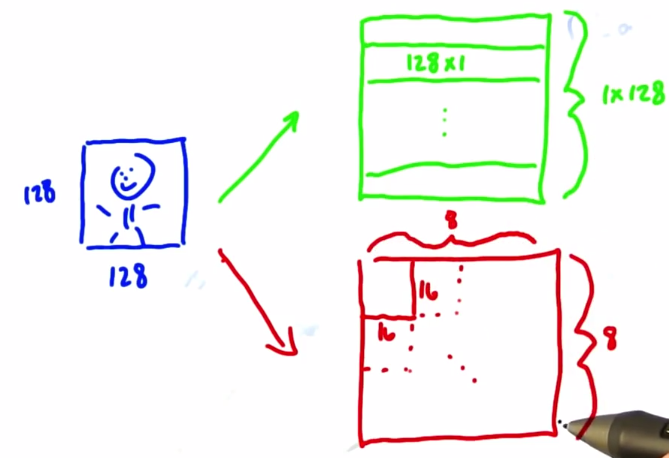
总结起来核函数的调用的完整形式是
kernel<<<dim3(bx,by,bz), dim3(tx,ty,tz), shmem>>>(...)第一个参数表示网络块的维数(bx * by * bz),
第二个参数表示每块所含有的线程数(tx * ty * tz)
第三个参数一般默认为0,它是以字节表示的每个线程块分配的共享内存量

最后
以上就是高高黄蜂最近收集整理的关于Udacity并行计算课程笔记-The GPU Programming Model一、传统的提高计算速度的方法二、CPU & GPU三、cuda登场四、A CUDA Program五、定义GPU计算六、CPU&GPU计算原理区别的全部内容,更多相关Udacity并行计算课程笔记-The内容请搜索靠谱客的其他文章。








发表评论 取消回复