VGGNet模型简介
VGGNet是由牛津大学视觉几何小组(Visual Geometry Group, VGG)提出的一种深层卷积网络结构,以7.32%的错误率赢得了2014年ILSVRC分类任务的亚军。它采用的 3x3 的卷积核思想是后来许多模型基础。
特点
-
整个网络采用同样大小的卷积核尺寸 3x3 和最大池化尺寸 2x2。
-
1x1 卷积的意义主要在于线性变换,通道数不变,没有降维。
-
两个 3x3 的卷积串联相当于一个 5x5 的卷积,感受野大小为 5x5。
三个 3x3 的卷积串联相当于一个 7x7 的卷积,感受野大小为 7x7。
这样做是网络参数量更小,多层的激活函数也提高了网络的学习能力。
-
VGGNet 训练时,可以先训练浅层的简单网络VGG11,再复用VGG11的权重初始化来训练VGG13。
-
在训练过程中可以使用对数据进行增强,使得模型不容易过拟合。
1.网络结构
VGGNet有多种版本,它们区别只是模型中卷积层数量的不同。
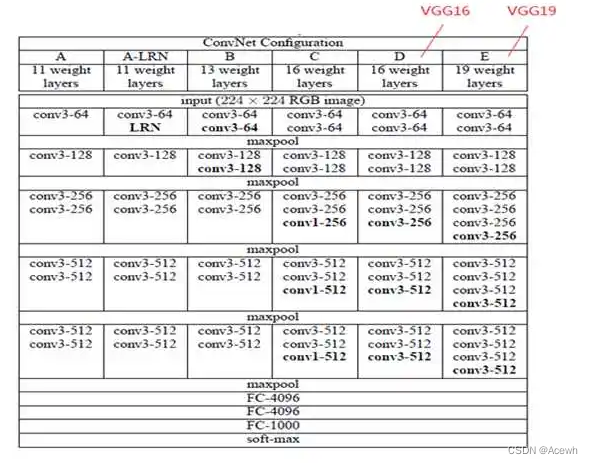
2.TF2实现
from tensorflow.keras.layers import Convolution2D,MaxPooling2D,Flatten,Dense,Dropout
from tensorflow.keras import Sequential
import tensorflow as tf
def vgg_block(convs_num,filters_num):
vblk = Sequential()
for i in range(convs_num):
vblk.add(Convolution2D(filters_num,kernel_size=3,padding='same',activation='relu'))
vblk.add(MaxPooling2D(pool_size=2,strides=2))
return vblk
def vgg16(conv_arch):
model = Sequential()
for (convs_num,filters_num) in conv_arch:
model.add(vgg_block(convs_num,filters_num))
model.add(Sequential([
Flatten(),
Dense(4096,activation='relu'),
Dropout(0.5),
Dense(4096,activation='relu'),
Dropout(0.5),
Dense(1000,activation='softmax')
]))
return model
# VGG16有5个vgg块,总共13个卷积层,再加上3个全连接层,所以称为VGG16
conv_arch = ((2,64),(2,128),(3,256),(3,512),(3,512))
m_vgg = vgg16(conv_arch)
X = tf.random.uniform((1,224,224,1))
Y = m_vgg(X)
m_vgg.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential_1 (Sequential) (1, 112, 112, 64) 37568
_________________________________________________________________
sequential_2 (Sequential) (1, 56, 56, 128) 221440
_________________________________________________________________
sequential_3 (Sequential) (1, 28, 28, 256) 1475328
_________________________________________________________________
sequential_4 (Sequential) (1, 14, 14, 512) 5899776
_________________________________________________________________
sequential_5 (Sequential) (1, 7, 7, 512) 7079424
_________________________________________________________________
sequential_6 (Sequential) (1, 1000) 123642856
=================================================================
Total params: 138,356,392
Trainable params: 138,356,392
Non-trainable params: 0
_________________________________________________________________
或者
vgg16 = tf.keras.applications.vgg16.VGG16(
include_top=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
classifier_activation='softmax'
)
vgg19 = tf.keras.applications.vgg19.VGG19(
include_top=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
classifier_activation='softmax'
)
3.PyTorch实现
import torchvision.models as models
from torchsummary import summary
vgg16 = models.vgg16()
print(vgg16)
summary(vgg16.cuda(),(3,227,227))
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 227, 227] 1,792
ReLU-2 [-1, 64, 227, 227] 0
Conv2d-3 [-1, 64, 227, 227] 36,928
ReLU-4 [-1, 64, 227, 227] 0
MaxPool2d-5 [-1, 64, 113, 113] 0
Conv2d-6 [-1, 128, 113, 113] 73,856
ReLU-7 [-1, 128, 113, 113] 0
Conv2d-8 [-1, 128, 113, 113] 147,584
ReLU-9 [-1, 128, 113, 113] 0
MaxPool2d-10 [-1, 128, 56, 56] 0
Conv2d-11 [-1, 256, 56, 56] 295,168
ReLU-12 [-1, 256, 56, 56] 0
Conv2d-13 [-1, 256, 56, 56] 590,080
ReLU-14 [-1, 256, 56, 56] 0
Conv2d-15 [-1, 256, 56, 56] 590,080
ReLU-16 [-1, 256, 56, 56] 0
MaxPool2d-17 [-1, 256, 28, 28] 0
Conv2d-18 [-1, 512, 28, 28] 1,180,160
ReLU-19 [-1, 512, 28, 28] 0
Conv2d-20 [-1, 512, 28, 28] 2,359,808
ReLU-21 [-1, 512, 28, 28] 0
Conv2d-22 [-1, 512, 28, 28] 2,359,808
ReLU-23 [-1, 512, 28, 28] 0
MaxPool2d-24 [-1, 512, 14, 14] 0
Conv2d-25 [-1, 512, 14, 14] 2,359,808
ReLU-26 [-1, 512, 14, 14] 0
Conv2d-27 [-1, 512, 14, 14] 2,359,808
ReLU-28 [-1, 512, 14, 14] 0
Conv2d-29 [-1, 512, 14, 14] 2,359,808
ReLU-30 [-1, 512, 14, 14] 0
MaxPool2d-31 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-32 [-1, 512, 7, 7] 0
Linear-33 [-1, 4096] 102,764,544
ReLU-34 [-1, 4096] 0
Dropout-35 [-1, 4096] 0
Linear-36 [-1, 4096] 16,781,312
ReLU-37 [-1, 4096] 0
Dropout-38 [-1, 4096] 0
Linear-39 [-1, 1000] 4,097,000
================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.59
Forward/backward pass size (MB): 222.41
Params size (MB): 527.79
Estimated Total Size (MB): 750.79
----------------------------------------------------------------
4.其他版本
vgg11 = models.vgg11() # VGG11 有 8个卷积层,3个全连接层
vgg13 = models.vgg13() # VGG11 有 10个卷积层,3个全连接层
vgg19 = models.vgg19() # VGG11 有 16个卷积层,3个全连接层
vgg13bn = models.vgg13_bn() # 每个卷积层后面添加一个BN层
最后
以上就是优雅香菇最近收集整理的关于VGGNet模型简介,Tensorflow2与Pytorch的实现VGGNet模型简介的全部内容,更多相关VGGNet模型简介,Tensorflow2与Pytorch内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复