MONAI是nvidia技术人员在2022年1月13日线上沙龙分享出来的repository。主要针对医疗影像的特殊性质在pytorch基础上做了一些相关工作。本文章只作为线上沙龙的一些体会,关于monai技术的具体使用后续在有文章更新(如果我还想得起来更新的话233)。

如上所示,MONAI是主要针对healthcare的基于pytorch(吐槽一下paddle要取代pytorch还有很长的路要走,当然paddle也有他的亮点233)。
以下是他的设计初衷,听完他们的分享个人感觉重点是monai比pytorch开发了更多能够针对医疗影像的transform,省去了开发者去自己在写3d相关transform的精力(吐槽一下pytorch相关的图像变化的确比较少而且貌似都是2d的,好多都要自己去写的)
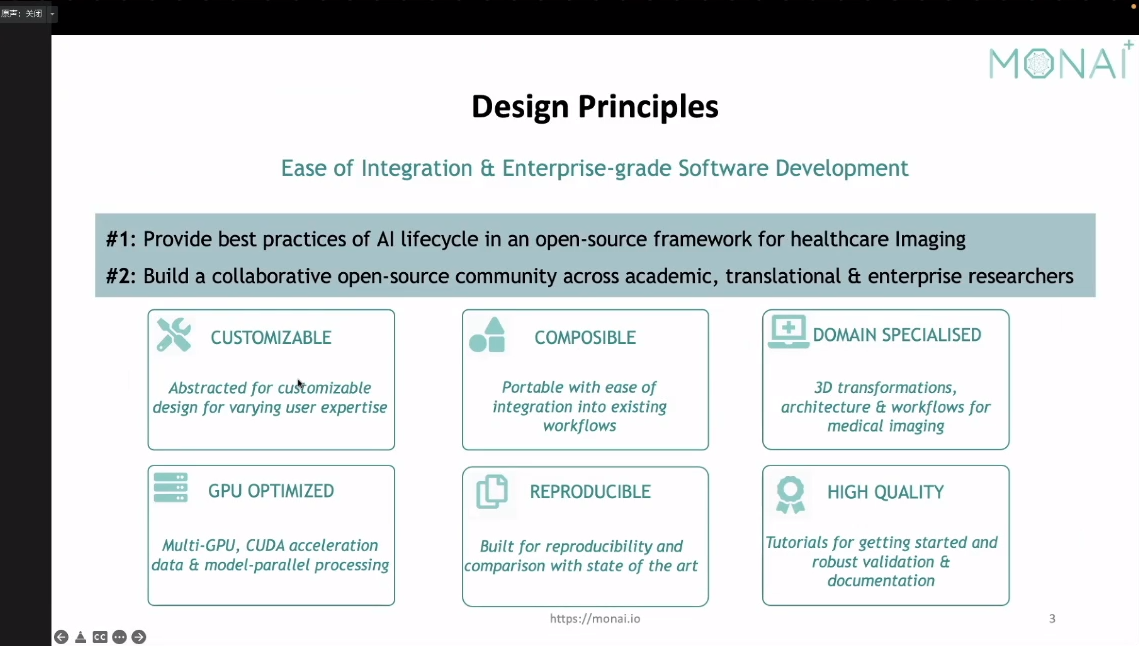
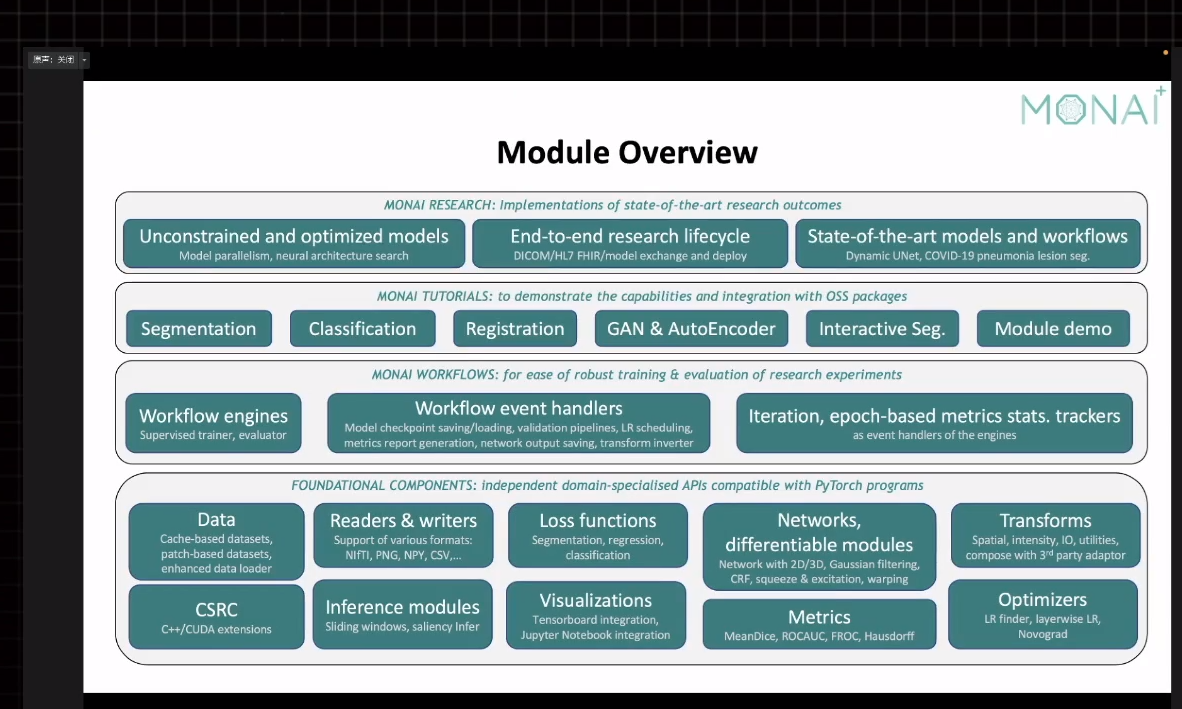
以下是monai的模块总览
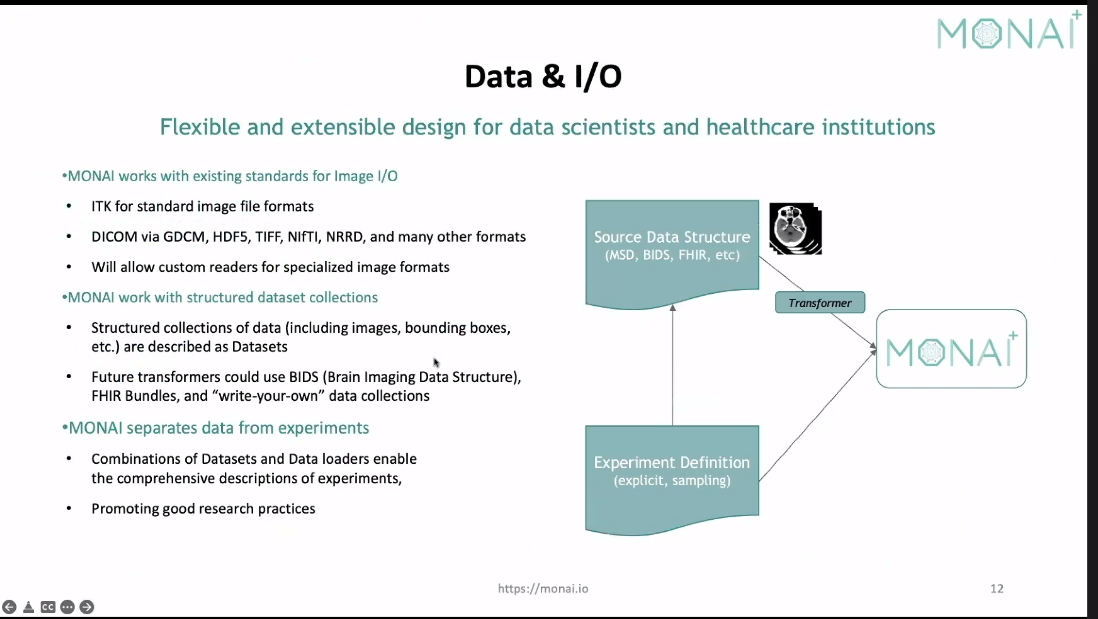
下面讲的是monai可以直接根据图像类型进行读取。我们构建dataset的时候可以方便一些
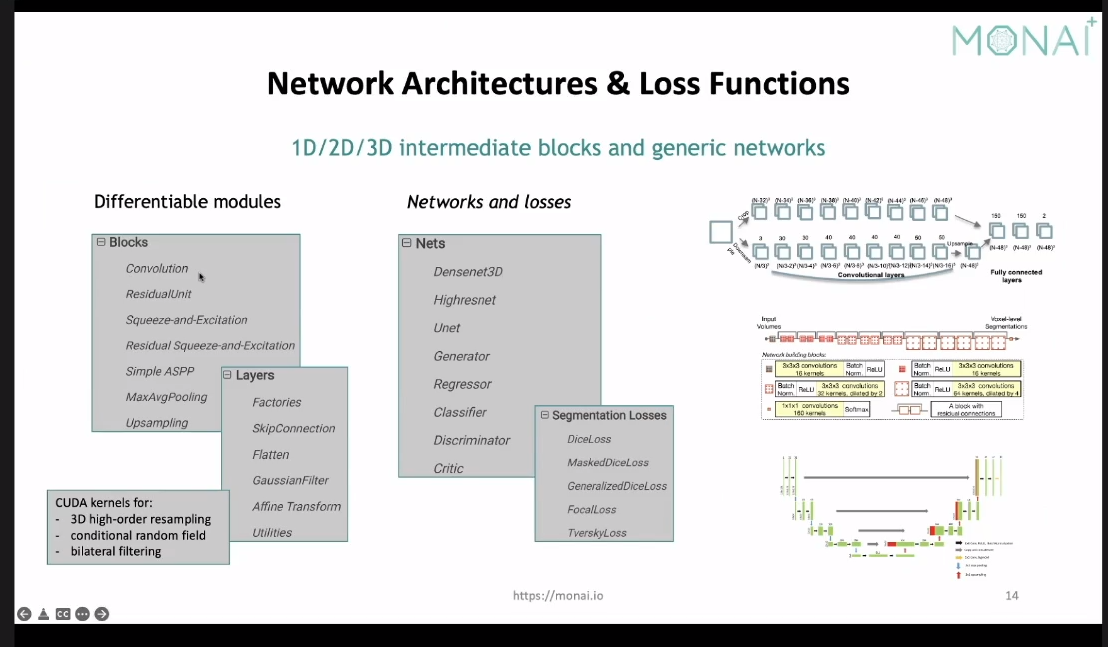
然后再深度学习的相关模块上,monai又提供了满足3d的loss和net相关的模块
官方介绍时候粗略说了一下他们亮点的地方(可能还有别的,但是这里他们没有细讲只是说他们有这些也没说原理):
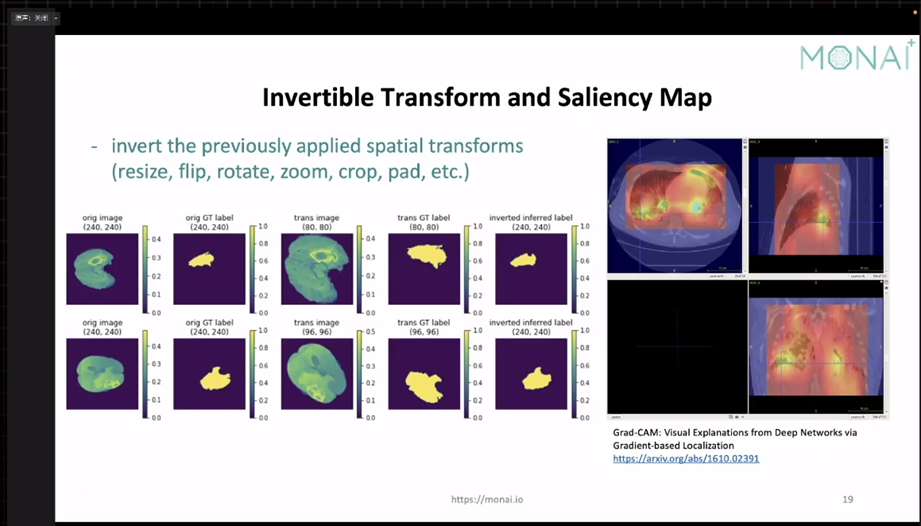
- 支持Invertible transform:大概意思是我们在训练的时候进行了一些随机性的数据增强。比如一些仿射变幻,然后训练得出的label可以通过Invertible transform在反推回去和原始的label进行对比
- Interactive segmentation,这个主要是关于数据标注的。据说是能够对我们数据标注有一定帮助。毕竟医疗图像数据标注起来太蛋疼了(不知道和3dslicer比较是否根据优势,这个我得去实操下)

- 然后还说他们复现了关于最新医疗影像的成果(这个他们一笔带过,不过个人感觉可以好好学习下)

- 联邦学习(这个名字比较陌生,不是很懂)
下面我认为是比较重点和实用的一些东西。数据的处理、gpu加速
数据的处理
相关的transform有200+,可以分为6大类如下图,印象比较深刻的是post-processing(举例一下里面有nms等处理,感觉以后nms不用自己写了233)。另外我们还可以自己去写自定义的transform(这个感觉没啥,大多数框架都支持233)。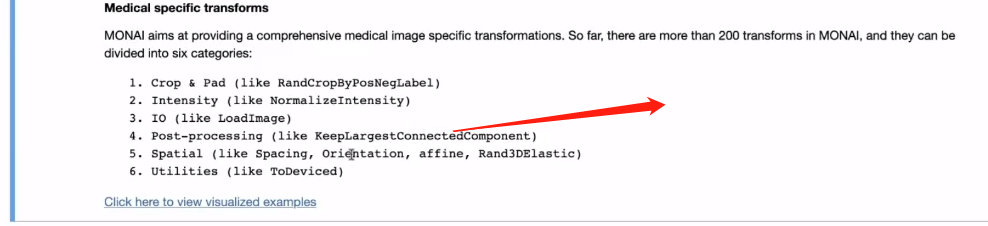
dataset和dataloader他们提出在gpu比较好的情况下,cpu和磁盘可能成为短板导致训练变慢了。并且给到了解决方案。让我们去用他们那边给到的dataset: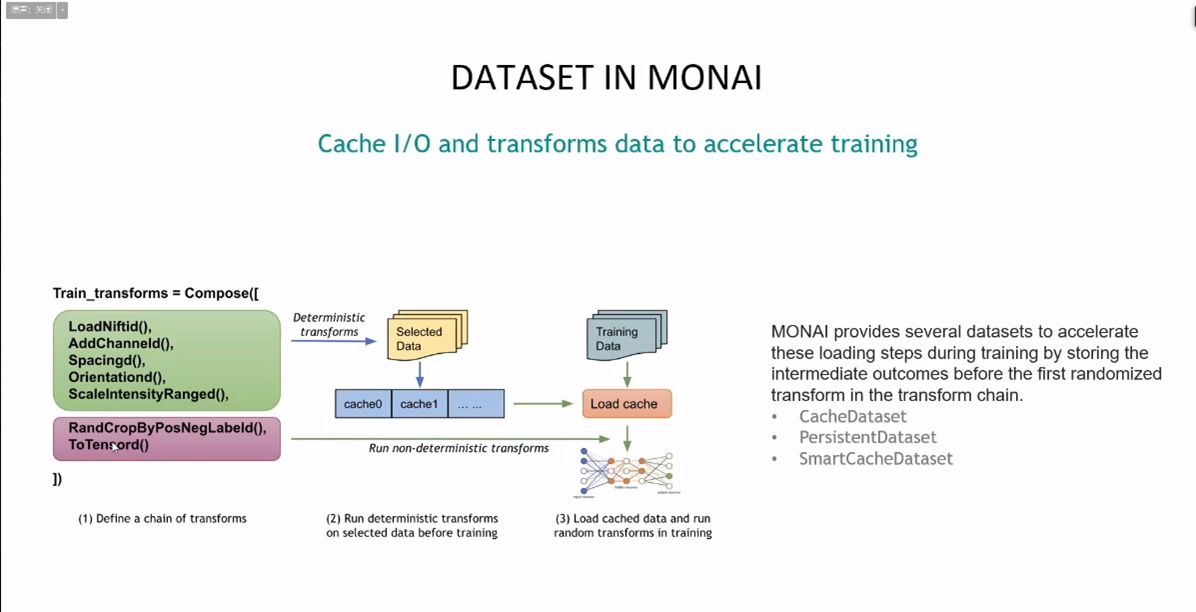
- catchdataset不需要每次从磁盘读数据,降低计算量(不需要每次计算非随机那部分)
- persistentdataset把非随机结果保存到磁盘上而不是内存中(数据大的时候)
- smartcachedataset不同于cacheset值她只缓存一部分数据。后台会每次epoch替换缓存的那一部分
主要思路就是把第一个epoch的时候把数据cache下来。以后拿训练数据的时候就不要总是去磁盘上读了,transform的时候也不用总是cpu在transform一遍(他们后面在讲gpu加速的时候又提到可以将数据catch到gpu上去充分利用gpu)。另外还有一点catch的好处是,我们可以把catch数据分享给其他的研究人员。
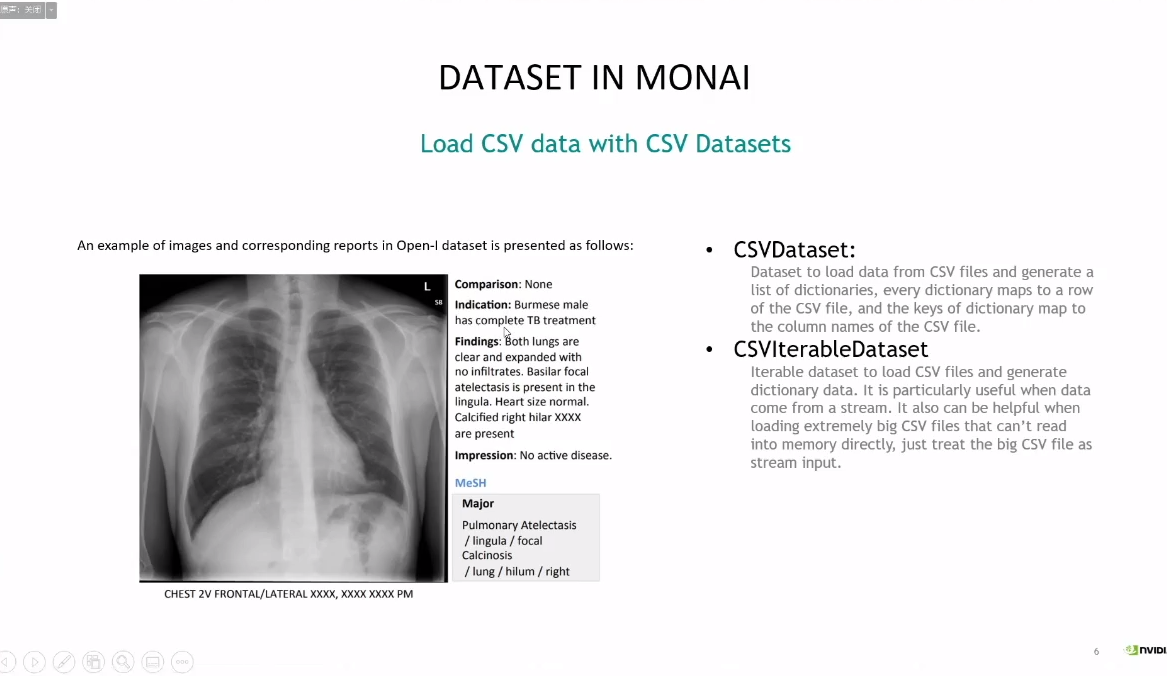
在然后就是将了如何应对多模态数据。以往我们在做视觉相关任务的时候一般可能只要有array图像信息就够了,但是医疗图像中实际上市有很多meta数据的。如果我们想把meta数据也应用上的话,也提供了dataset去应对这种情况(主要是方便,读csv的功能也帮我们封装好了,当然没有他我们也可以自己写233)
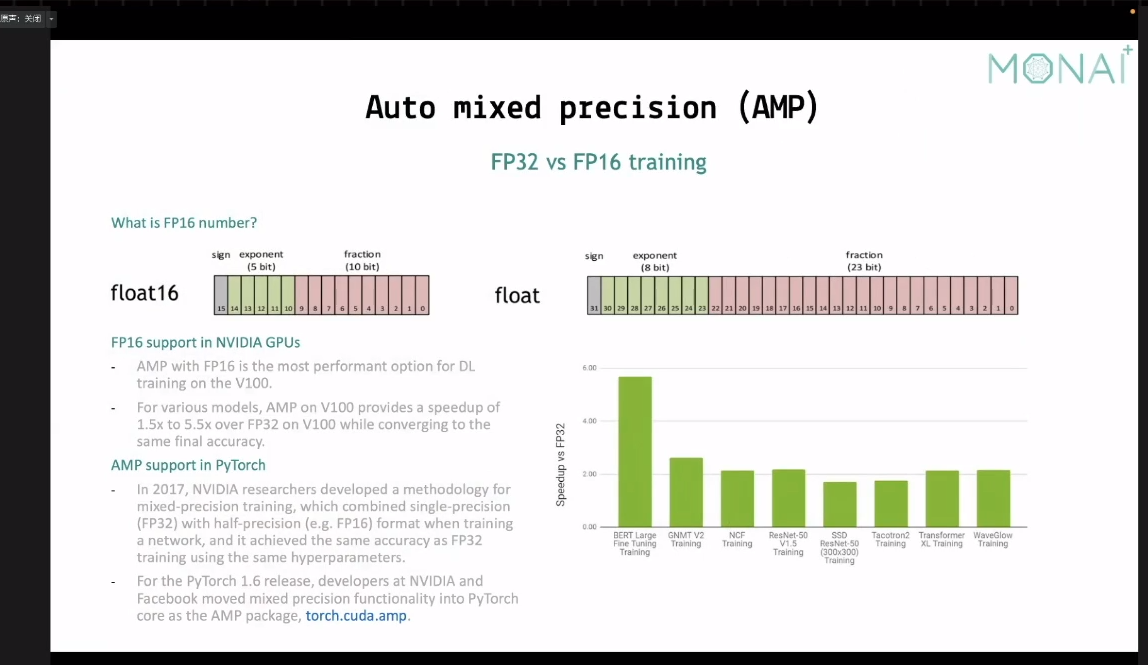
训练加速部分
半精度计算,这个很早就有的没啥好说的
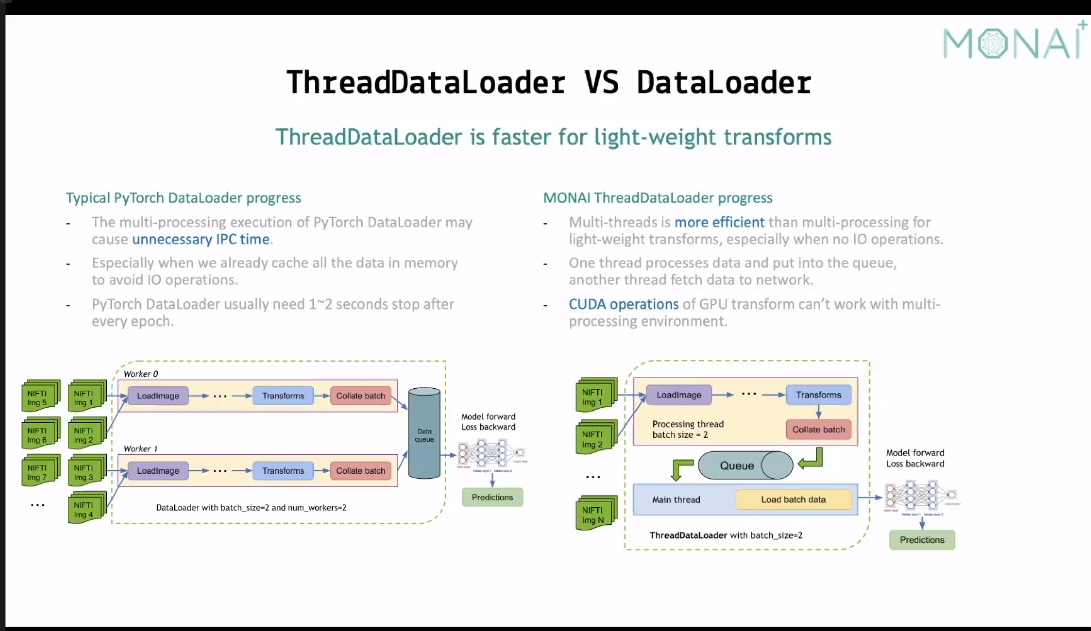
在gpu上进行transform。配合前面提到的dataset进行cache的思路。

threaddataloader讲的是我们平时pytorch dataloader在epoch训练的间隔之间是停了一段时间的,导致有一些时间段gpu是处于空闲状态。说线程在这里优于进程(大概是这个意思,具体太底层了我也不懂233,反正去用就对了)。
最后是一个医生大佬分享了一下个人用monai的体悟,讲了自己的一些经历,大概如下图



最后
以上就是犹豫万宝路最近收集整理的关于开始monai的全部内容,更多相关开始monai内容请搜索靠谱客的其他文章。








发表评论 取消回复