此博客仅为我业余记录文章所用,发布到此,仅供网友阅读参考,如有侵权,请通知我,我会删掉。
本文章纯野生,无任何借鉴他人文章及抄袭等。坚持原创!!
1. 前言
本文章主要介绍利用Python去规范Excel表格数据,算得上是简单的数据清洗。!!!
相信可以帮助部分读者朋友们不怎么有效的整理Excel表格。
2. 数据清洗概念
下图引用于—百度百科:数据清洗。
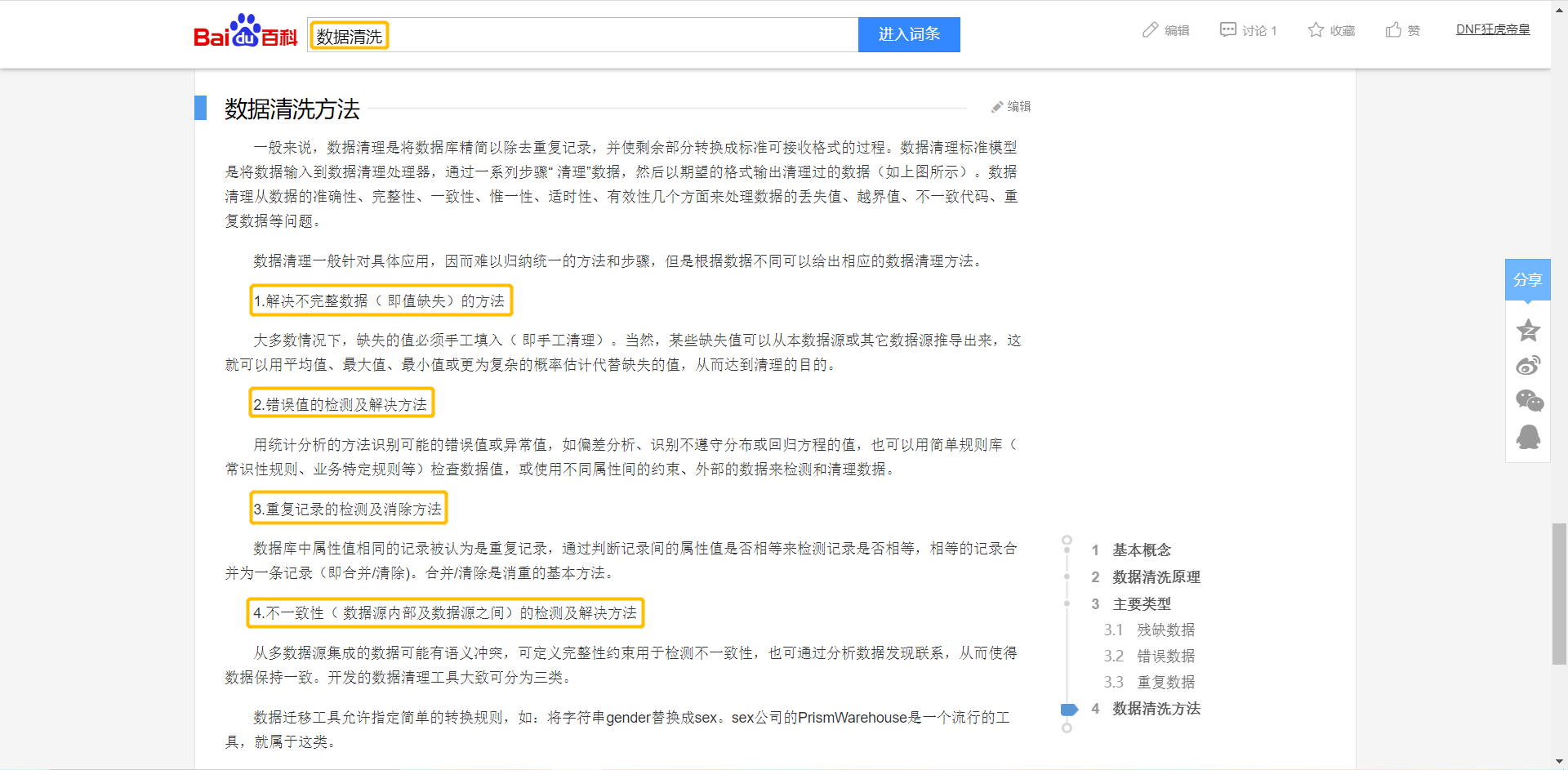
总结一下(个人拙见),数据清洗的方法就是以下四个特性:
- 完整性
.如带有缺失值(NaN)需要填写上。 - 合理性
.如某人年龄到200岁,体重到800千克,明显不合理。 - 唯一性
.如个别数据出现了重复,需要去重。 - 一致性
.如单位的千克和磅,需要转换成一致。
下面就是具体的使用代码执行这四个特性啦。
3. 数据展示
示例数据如图:
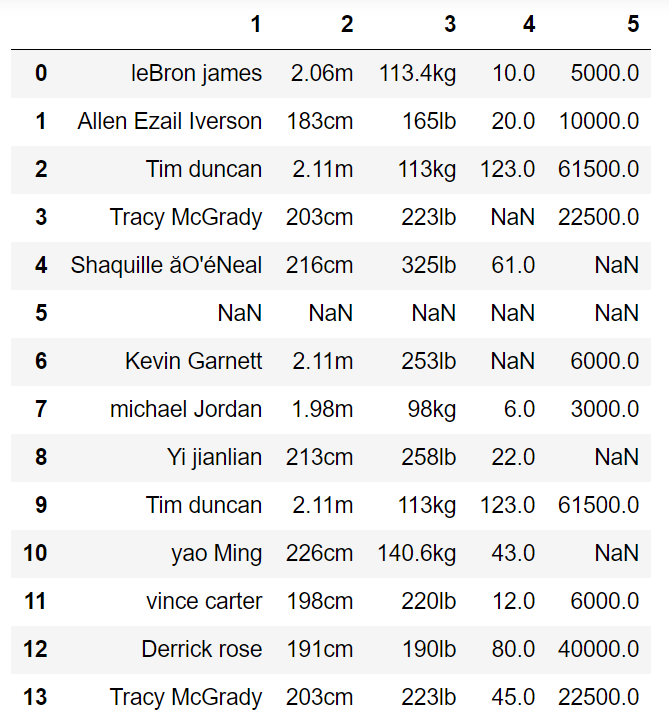
上图看的很蒙蔽吧!!连数据标识都没有,这都是什么跟什么啊???这就是那盛传的脏乱差数据吖!!!
其实这是一个球员工作表的数据。
| 方法 | 说明 | 列名 |
|---|---|---|
| 第一列 | 姓名 | name |
| 第二列 | 身高 | height |
| 第三列 | 体重 | weight |
| 第四列 | 工作天数 | working |
| 第五列 | 工资 | salary |
这都是一些球星和身高体重,后面的工作天数和工资都是我瞎编的。。。
看到姓名这一列,首字母有的大写、有的小写。身高和体重这一列单位不大一样,还存在空行,空值(NaN)非ASCII字符等!!! 看起来着实令人头疼。
特别说明一下,这里选用英文名字是为了更好的说明案例!!
还有!!需要给每一列加上列名,不然无法进行后续操作。
4. 代码执行
这里主要用到的模块就是Pandas了,也只用到Pandas模块。
如果出现看不懂代码是什么意思,请耐心往下看,文章下面会有文章所有演示代码的释义!!!
安装模块
pip install pandas
导入模块
import pandas as pd
这里的Excel表格文件名为data.xls.
# 导入Excel表格文件
df = pd.read_excel('data.xls')
4.1 完整性
- 删除空行
df.dropna(how='all', inplace=True)
- 填充空值(此处有两个方法,取平均值或最高频次)
# 对工作天数 和 工资列 取该列平均值
df['working'].fillna(round(df['working'].mean()), inplace=True)
df['salary'].fillna(round(df['salary'].mean()), inplace=True)
# 最高频次
# work_maxf = df['working'].value_counts().index[0]
# df['working'].fillna(work_maxf, inplace=True)
# 最高频次
# work_maxf = df['salary'].value_counts().index[0]
# df['salary'].fillna(work_maxf, inplace=True)
4.2 合理性
- 这里的
Shaquille O'Neal看起来带了非ASCII字符,需要删除非ASCII字符
# 正则匹配 删除 非ASCII字符
df['name'].replace({r'[^x00-x7F]+':''}, regex=True, inplace=True)
4.3 唯一性
- 看到有个别行是重复的,需要进行删除
# 删除name、weight、height三个字段都一样的重复行,保留第一行
df.drop_duplicates(['name', 'height', 'weight'], inplace=True)
4.4 一致性
- 姓名统一首字母大写
# title()为首字母大写 upper()为全部大写 lower()为全部小写
df['name'] = df['name'].str.title()
- 身高单位统一转换成厘米(cm)
for index, data in df.iterrows(): # 1
height = data['height']
if 'cm' not in height: # 2
height = round(float(height[:-1]) * 100) # 3
df.at[index, 'height'] = f'{height}cm' # 4
## 代码释义:
1 -- 返回一个元组(index,row) 索引和数据
2 -- 判断 'cm'是否在 'height'里边
3 -- 对单位为 'm'的数据取浮点,并去掉最后一位'm',乘100转换为 'cm'
4 -- 获取某个位置的值,例如,获取第0行,第a列的值,df.at[0, 'a']
- 体重统一转换成千克(kg)
rows_with_lb = df['weight'].str.contains('lb', na=False) # 1
for index, data in df[rows_with_lb].iterrows(): # 2
weight = int(float(data['weight'][:-2]) / 2.2) # 3
df.at[index, 'weight'] = f'{weight}kg' # 4
## 代码释义:
1 -- 获取 weight 数据列中单位为 lb 的数据
2 -- 返回一个元组(index,row) 索引和数据
3 -- 截取从头开始到倒数第三个字符之前,即去掉lbs,并将磅转换为千克:磅 * 2.2 = 千克
4 -- 获取某个位置的值,例如,获取第0行,第a列的值,df.at[0, 'a']
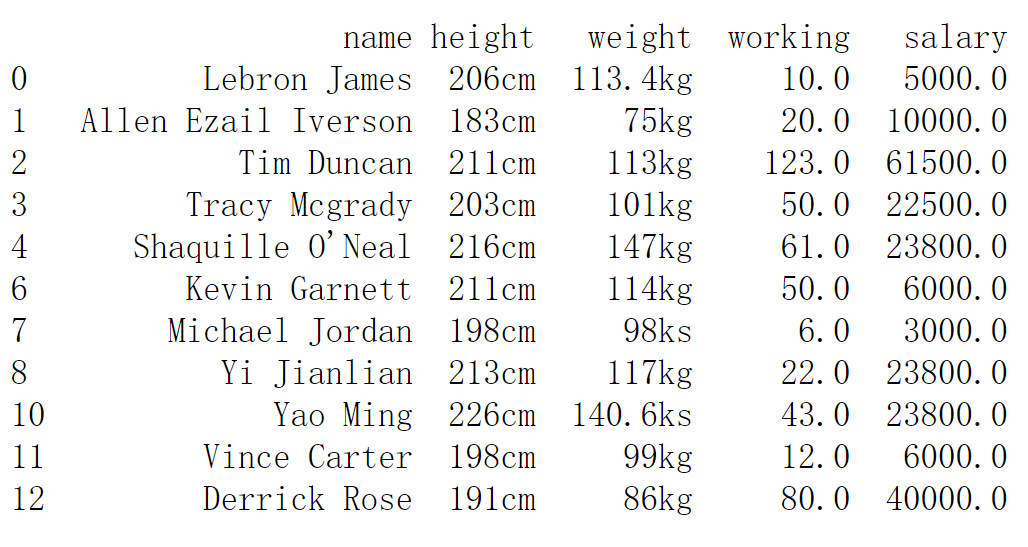
4.5 处理后的数据表
处理后的数据表如下,怎么样。看起来好看很多了吧!!!
4.6 保存处理后的数据
# 保存为Excel表格
df.to_excel('clean_data.xls')
# 保存为csv表格
df.to_csv('clean_data.csv')
4.7 总结
回过头来看看,本次文章对文中示例的数据做了那些操作。
- 删除空行
- 填充空值
- 删除
非ASCII字符 - 删除重复行
- 姓名统一首字母大写
- 身高单位统一转换成厘米(cm)
- 体重统一转换成千克(kg)
- 最后就是将清洗后的数据保存为心的表格文档啦。
诚然,本文章不能作为标准的数据清洗学习,但是也有一定的参考价值!!!
至此!!相信你已经可以对类似文中示例的脏乱差数据进行清洗了。
5. 文章用到的pandas代码整合
5.1 删除空行
df.dropna(how='all', inplace=True) # 删除空行
5.2 删除重复的数据行
传参为判断的重复与否的列,
默认删除保留重复数据第一条,keep用于指定删除留下哪一列,first留下第一条,last留下最后一条,False表示删除所有重复数据。
# 删除重复数据行
df.drop_duplicates(['name', 'height', 'weight'], keep='last', inplace=True)
5.3 填充空值
# 取salary列平均值
df['salary'].fillna(round(df['salary'].mean()), inplace=True)
# 取Age列最高频次
salary_maxf = df['salary'].value_counts().index[0]
df['salary'].fillna(salary_maxf, inplace=True)
5.4 查找包含某个字符的行
lb为 查询包含带有lb的行
na=False为不填充空值
rows_with_lb = df['weight'].str.contains('lb', na=False)
print(df[rows_with_lb])
5.5 替换字符
df.replace,可替换全部,也可替换某一列
regex默认为Flase,表示正则匹配,如果regex不为True,则需全匹配
5.5.1 替换某列单个字符
df['name'].replace('xxx', '1', regex=True, inplace=True)
5.5.2 替换某列多个字符
多个字符匹配需用字典
# 替换所有的 非ASCII字符 为 空
df['name'].replace({r'[^x00-x7F]+': '123'}, regex=True, inplace=True)
5.3 获取某行某列的数据
作用:获取某个位置的值,例如,获取第0行,第a列的值,
data = df.at[0, 'a'] # 即:index=0,columns='a',
5.4 返回每行数据的可迭代对象
返回对象是一个元组(index,row) 索引和数据
一般定义两个变量接收返回,第一个为索引,第二个为行数据。
for index,value in df.iterrows():
print(index,value) # 取Age列的数据 value[Age]
5.5 拆分某列并生成新列
expand,将拆分的字符串展开为单独的列。默认为False,
df[['first_name', 'last_name']] = df['name'].str.split(expand=True)
df.drop('name', axis=1, inplace=True) # 删除name列,需要指定axis
后话
好了,本次的分享就到这里。
有任何疑问欢迎留言。
最后
以上就是爱撒娇香水最近收集整理的关于遇到“脏乱差”的Excel数据怎么办??利用Python规范Excel表格数据(数据清洗)1. 前言2. 数据清洗概念3. 数据展示4. 代码执行5. 文章用到的pandas代码整合后话的全部内容,更多相关遇到“脏乱差”的Excel数据怎么办??利用Python规范Excel表格数据(数据清洗)1.内容请搜索靠谱客的其他文章。








发表评论 取消回复