由于本专业(信息与计算科学)这学期新开了一门数据分析的课程,然后我在就业招聘信息上也看到近几年数据分析师的岗位薪资还是蛮不错的,所以打算入手学一下数据分析,在了解这一职业时发现很多大神们都是利用业余时间自学了数据分析,这一发现带给我这个小白无限打击,要知道我可是本来打算把它作为我将来的职业,可是很多人把它当做了副业并且学会了。。不得不说人外有人从众!那么既然如此,我就自己先学着咯,主业也好副业也罢,也是自己的本事。所以这也是我开通这个博客的一个重要原因啦,监督自己!把学习中发现的有趣的问题写到这里,希望看到的大神也一起帮忙解答解答咯。
入门Python是从看廖雪峰老师的课程开始的,前面一些基础的还好,看到后面IO编程这一部分就感觉越来越枯燥,寒假就是因为这个原因放弃了然后再也没拿起过。。不管怎么说,新的学期新的开始,那么就稍微看了一下这一部分,首先看到的就是读写文件,嗯,是读文件,我是在这里遇到了一揽子事。
首先是这样,
f=open('C:UsersLenovo1Desktopabc.docx','r')
f.read()---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-64-267fb7a37d17> in <module>()
1 f=open('C:\Users\Lenovo1\Desktop\abc.docx','r')
----> 2 f.read()
UnicodeDecodeError: 'gbk' codec can't decode byte 0xb2 in position 55: illegal multibyte sequence
def file_operation():
with open('C:UsersLenovo1Desktopabc.docx'.encode("utf-8"), 'r') as f:
r = f.readlines()
print(r)
file_operation()大神说 .encode(“utf-8”)是将文件中非法编码转为utf-8编码,然鹅,结果如下:
File "<ipython-input-16-148c828a24fb>", line 2
with open('C:UsersLenovo1Desktopabc.docx'.encode("utf-8"), 'r') as f:
^
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated UXXXXXXXX escape英语小渣又去查了某翻译软件,syntax语法,又变成了语法错误
import docx
file=docx.Document("D:\abc.docx")
for p in file.paragraphs:
print(p.text)然后又一位大神给了我这样的代码
import docx
file=docx.Document("D:\abc.docx")
for p in file.paragraphs:
print(p.text)这次运行出来是正确的,但是!之前还是有一段波折滴,是从import docx引起...
有人提出,不应该去读c盘下面的文件,因为C盘下面有中文目录,然后我把文件换到了D盘,既然D盘可以读取的话,那么这样是不是也可以呢
f=open('D:abc.docx','r')
f.read()---------------------------------------------------------------------------
OSError Traceback (most recent call last)
<ipython-input-20-62895ba8a8f9> in <module>()
----> 1 f=open('D:abc.docx','r')
2 f.read()
OSError: [Errno 22] Invalid argument: 'D:x07bc.docx'又出现了OS错误,什么鬼!据说是转义错误,我也不清楚。。
这时,我的某位大神同学说是不是因为要打开的文件是.docx,如果换成.txt或许能打开,于是乎我在电脑中找了一个.txt文件,因为前面有人提到文件没有close,所以我打算用with语句
with open('C:UsersLenovo1Desktopxg.txt', 'r',encoding='ch01',errors='ignore') as f:
r = f.read()
print(r)with open('C:/Users/Lenovo1/Documents/JS1602080311/ch01/ch01.txt', 'r') as f:
r=f.read()
print(r)这个结果对我来说至今还是个谜
File "<ipython-input-63-91a668a5e479>", line 1
with open('C:/Users/Lenovo1/Documents/JS1602080311/ch01/ch01.txt', 'r') as f:
^
SyntaxError: invalid character in identifier看起来并没有什么错误
这时,某位大神同学发来了这样一段程序,可以读取.docx文件
import docx
from docx import Document
path="C:\Users\Lenovo1\Desktop\abc.docx"
document=Document(path)
for paragraph in document.paragraphs:
print(paragraph.text)和前面那位大致意思差不多,只是我第一次运行这个代码显示没有docx模块,然后同学教我打开命令行(cmd)输入
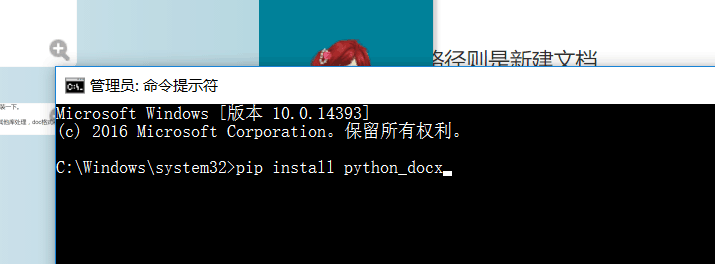
这样就下载了docx模块,咦,代码中的文件名中右斜杠全部都是两个一起用,对了,是需要被转义的,所以要\,之后又查了博客,也可以把window文件中的右斜杠直接改为左斜杠或在文件之前加r表示转义。所以,这样就正常运行了
with open('C:\Users\Lenovo1\Desktop\xg.txt', 'r') as f:
r = f.read()
print(r)最后
以上就是矮小跳跳糖最近收集整理的关于刚刚入手用Python读写文件遇到的一揽子事的全部内容,更多相关刚刚入手用Python读写文件遇到内容请搜索靠谱客的其他文章。








发表评论 取消回复