最近在研究主动目标跟踪问题,导师给推荐了这篇文章,主要目的是了解主动目标跟踪问题是什么,但是既然论文看了,也把其中的内容写下来以供大家评鉴。
对于这篇文章的主要思想,新智元公众号里有一篇文章已经讲得很好了,把链接贴在这里,如果你只想了解其思想这个足够了。如果想细看论文的内容,也请先看这个链接中的内容,然后再回来读下面的内容。
论文链接
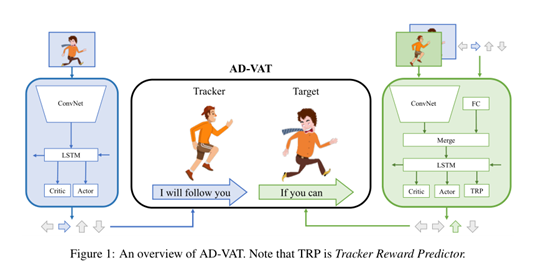
上图是这种非对称决斗的一个概况。
首先,为了解释这种非对称决斗机制,作者用使用了下面的数学表示:<S,O1,O2,A1,A2,r1,r2,P>
数学符号解释
下标1代表跟踪器,下标2代表目标,第二下标t(下面会出现)代表时间(可以看成是视频帧序列)
S:state space 环境状态空间
O:observation space 观察空间
A:action space 行动空间
r:reward function 奖赏函数
P:environment state transition probability 环境状态转换概率
部分观察情况(我的理解是不能够看到全局信息,比如在监控场景中,对应于用于细致观察目标的PTZ摄像机)下:O1,t=O1,t(St,St-1,Ot-1),在全观察情况下,退化为O1,t=St
(为什么部分观察情况下的观察受St-1和Ot-1影响还没有搞清楚,欢迎补充)
St+1由环境状态转移概率P(•|St,a1,t,a2,t)决定。
r1,t=r1,t(St,a1,t)
r2,t=r2,t(St,a2,t)
的意思是奖赏函数与环境状态和采取的行动有关。
跟踪器的策略
π1(a1,t|O1,t;θ1),公式代表一个用神经网络近似的函数,函数的意义是在O1,t的观察下采取行动a1,t所依据的策略,这个策略就是神经网络,其学习到的参数就是θ1。同理,有
目标的策略
π2(a2,t|O2,t;θ2),意义与前述相似,所不同的是这个策略并不是最终作者采用的策略,这部分稍后介绍。
“LOSS”
机器学习需要确立一个目标以评价学习的效果并依据效果不断改进。所以文章中给出了跟踪器和目标的“loss 函数”。跟踪器的目标是最大化在两个策略(π1、π2)的基础之上的所有时间t的奖赏值(r1,t)的和,公式如下:
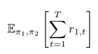
同理,目标的目标是最大化在两个策略(π1、π2)的基础之上的所有时间t的奖赏值(r2,t)的和,公式如下:
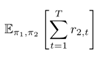
最大化的过程就是神经网络学习参数θ1、θ2的过程。
上面提到了奖赏值r1,t ,r2,t,那这两个值是怎么计算的?
首先来说一下奖赏结构,传统方法是零和奖赏结构,即r1,t +r2,t=0,作者提出了部分零和结构(partial zero-sum reward structure另一种翻译是不完全零和奖赏函数),这样做的理由是两个对手因为相距太远而不能够观察到对方的时候,在部分可观察博弈下,他们的行为很难直接影响对手的观察,在这种情况下,采样获取的经验对于提高agent(代理,用虚拟人物代理现实中的人物)的技能水平通常是无意义的、无效的。所以需要限制竞争在可观测范围内,提高学习效率。具体做法是在两个agent距离较近时,仅仅使用零和奖赏,较远时则施以惩罚。
然后具体说一下两个agent的奖赏函数:
跟踪器的奖赏函数:
以跟踪其为极坐标原点,假设目标的真实位置和期望位置为(ρ2,θ2)和(ρ2*,θ2*),
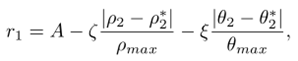
其中A是一个常数,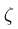 和
和 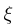 为惩罚项的系数,
为惩罚项的系数,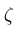 >0,代表永远有距离上的惩罚,
>0,代表永远有距离上的惩罚, 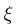 >=0,当等于0时对应2D环境,此时,不使用方向误差作为惩罚的一部分,因为在二维环境中观测是全方位的,
>=0,当等于0时对应2D环境,此时,不使用方向误差作为惩罚的一部分,因为在二维环境中观测是全方位的,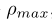 表示跟踪器的最大观测距离,
表示跟踪器的最大观测距离, 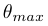 表示跟踪器的最大观测角,等价于通常所说的视野。当目标离预期位置较远时,为了避免过度惩罚,奖赏值被限定在[-A,A]范围内。
表示跟踪器的最大观测角,等价于通常所说的视野。当目标离预期位置较远时,为了避免过度惩罚,奖赏值被限定在[-A,A]范围内。
目标的奖赏函数:
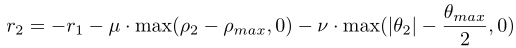
第一项是跟踪器奖赏值的负数,这样设置的原因很容易理解,r1越小,表示对跟踪器的惩罚越大,也就是说跟踪器的性能不好,此时,对于r2来说,r1越小,r2就越大,表示目标逃跑的越好,很自然的体现了两者性能的相对性。后面两个惩罚项一个限定不要距离跟踪器太远,一个限定不要逃离跟踪器的视野太远,其他参数的设置参照跟踪器的参数理解。
tracker-aware target
现在回到之前留下的那个问题,作者对π2(a2,t|O2,t;θ2)做了修改,作者借鉴孙子兵法中的知己知彼百战不殆的思想,将跟踪器的跟踪和动作反馈到目标网络中,以丰富目标的输入信息,加强target的能力以训练tracker,在最初的那幅图中训练target有个FC的输入,个人推测应该就是这里所说的反馈。所以,π2(a2,t|O2,t;θ2)变成了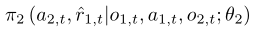
其中, 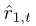 是对预测的跟踪器的直接奖赏,该辅助任务可以看做是一种“对手建模”,可以减轻其自身策略学习的难度。(这一部分为原文翻译,限于自己知识范围的限制,没懂作者什么意思。)
是对预测的跟踪器的直接奖赏,该辅助任务可以看做是一种“对手建模”,可以减轻其自身策略学习的难度。(这一部分为原文翻译,限于自己知识范围的限制,没懂作者什么意思。)
总结一下,实验结果表明,具有跟踪意识的目标能够产生更多样化的逃逸策略,并帮助生成更健壮的跟踪器。
以上所说的部分零和奖赏结构和知己知彼策略(tracker-aware target)就是本文的两个最重要的贡献。
实验部分的简单介绍:
环境:
2D环境:二维环境虽然在一定程度上表选出非真实感,但对于评价和量化各种方法的有效性,避开观测和行动中不受控制的噪声是理想的。地图(maps)的构建使用8080的矩阵,矩阵中的数字以0代表free space,1代表obstacle,2代表tracker,4代表target(3去哪了?),随机生成两种地图,街区和迷宫,前者用于训练,两者都用于测试,agent的视野为以自己为中心的1313的范围,跟踪器的目标是将目标尽可能靠近观察矩阵的中心,每次迭代中,跟踪器随即从map中的一个free space开始,目标则从以跟踪器为中心的3*3矩阵中的某个位置开始。agent可以向前后左右四个方向移动。
3D环境:三维环境显示了高保真度,旨在模拟真实世界的主动跟踪场景,活动空间被扩展成了七个,即前、后、左、右、左前、右前和不动。
具体的评价指标和结果请参看论文。
最后
以上就是称心飞机最近收集整理的关于《AD-VAT: AN ASYMMETRIC DUELING MECHANISM FOR LEARNING VISUAL ACTIVE TRACKING》ICLR2019论文阅读的全部内容,更多相关《AD-VAT:内容请搜索靠谱客的其他文章。





![fastDFS测试上传报错:[2018-01-04 16:37:54] ERROR - file: tracker_proto.c, line: 48, server: 192.168](https://www.shuijiaxian.com/files_image/reation/bcimg5.png)


发表评论 取消回复