-
HDFS 海量数据的存储系统
管理者:NameNode 工作者:DataNode -
MapReduce 海量数据计算框架
-
YARN 资源调度框架
管理者:ResourceManager 工作者:DataManager -
Common:Hadoop工具包,支持其他模块的工具模块(Configuration、RPC、序列化机制、日志操作)
Namenode的作用
a.维护,管理文件系统的名字空间(元数据信息)
b.负责确定指定文件块到具体的DataNode节点的映射关系
c.维护管理DataNode上报的心跳信息
Secondary NameNode在HDFS中是什么作用,他能不能替代NameNode?
Secondary NameNode主要作用是辅助namenode管理元数据信息,
负责辅助NameNode管理工作。他不能替代NameNode。
DataNode的作用
-
1.执行数据的读写(响应的是客户端)。
-
2.周期向NameNode汇报。(若datanode 10分钟没有向NameNode做汇报,表示已丢失(已宕机)
心跳周期 3秒 -
3.执行流水线的复制(一点一点复制)
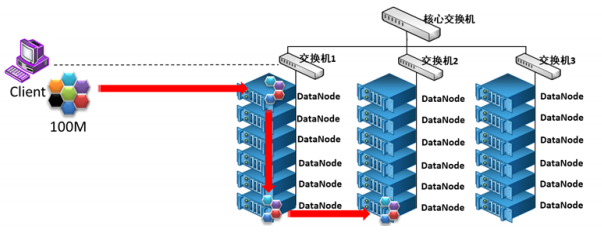
最后
以上就是愤怒金鱼最近收集整理的关于hadoop 组成部分的全部内容,更多相关hadoop内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复