文章目录
- 前言
- 一、GaussDB(DWS)工作负载管理介绍
- 1.工作负载管理满足的主要业务场景
- 2.工作负载管理概览
- 二、GaussDB(DWS)工作负载队列介绍与使用
- 1.工作负载队列机制介绍
- 2.并发管控能力
- 3.CPU管控
- 4.内存管控
- 5.空间管控
- 6.异常规则
- 7.工作负载队列案例
- 8.创建工作负载队列
- 9.并发管控测试
- 9.存储空间管控测试
- 三、GaussDB(DWS)工作负载计划介绍与使用
- 1.工作负载计划适用场景
- 2.启动工作负载计划
- 3.导入导出工作负载计划
- 四、GaussDB(DWS)模式空间管理介绍与使用
- 1.修改Schema空间限额
- 总结
前言
GaussDB(DWS)是一款具备分析及混合负载能力的分布式数据库,支持x86和Kunpeng硬件架构,支持行存储与列存储,提供GB~PB级数据分析能力、多模分析和实时处理能力,用于数据仓库、数据集市、实时分析、实时决策和混合负载等场景,广泛应用于汽车、制造、零售、物流、互联网、金融、政府、电信等行业分析决策系统。
相关使用文档地址:https://support.huaweicloud.com/mgtg-dws/dws_01_0018.html
本文主要介绍的内容如下:
- GaussDB(DWS)工作负载管理介绍
- GaussDB(DWS)工作负载队列介绍与使用
- GaussDB(DWS)工作负载计划介绍与使用
- GaussDB(DWS)模式空间管理介绍与使用
一、GaussDB(DWS)工作负载管理介绍
1.工作负载管理满足的主要业务场景
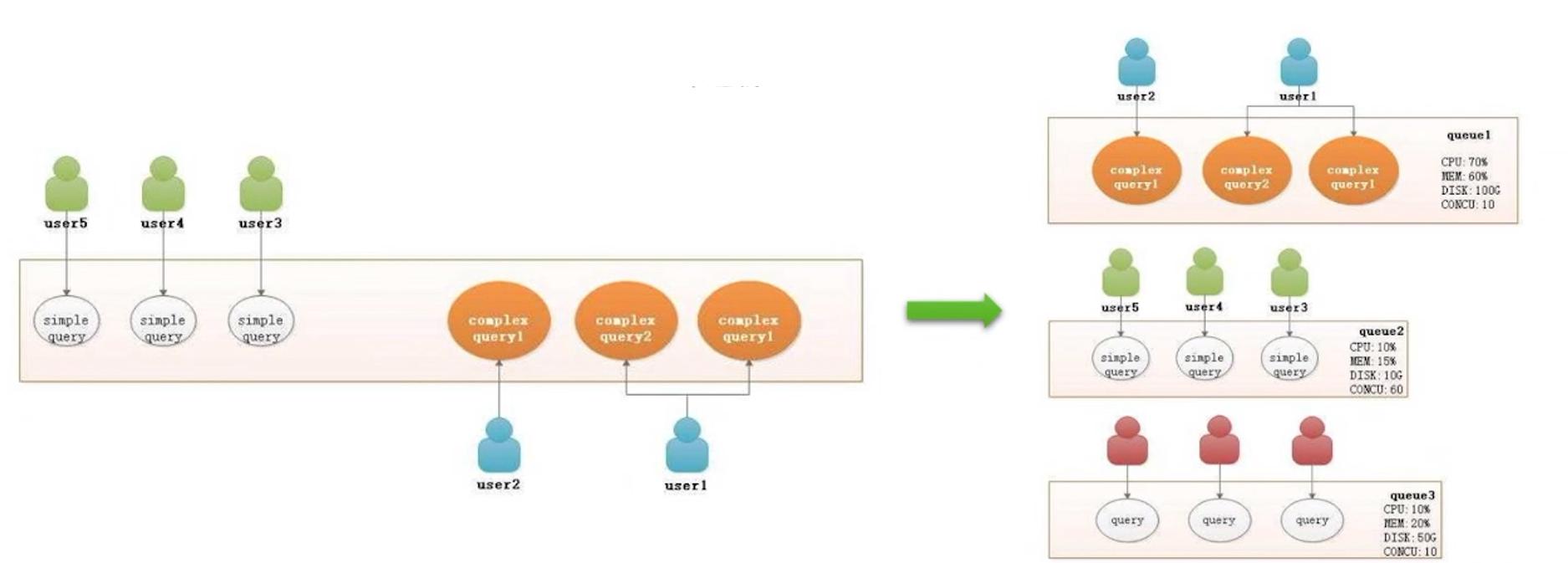
1、数据库多用户间的资源隔离
通过资源隔离达成多用户间执行业务不干扰
2、集群的负载控制
资源(CPU、内存、空间、并发)可控,保证集群不过载
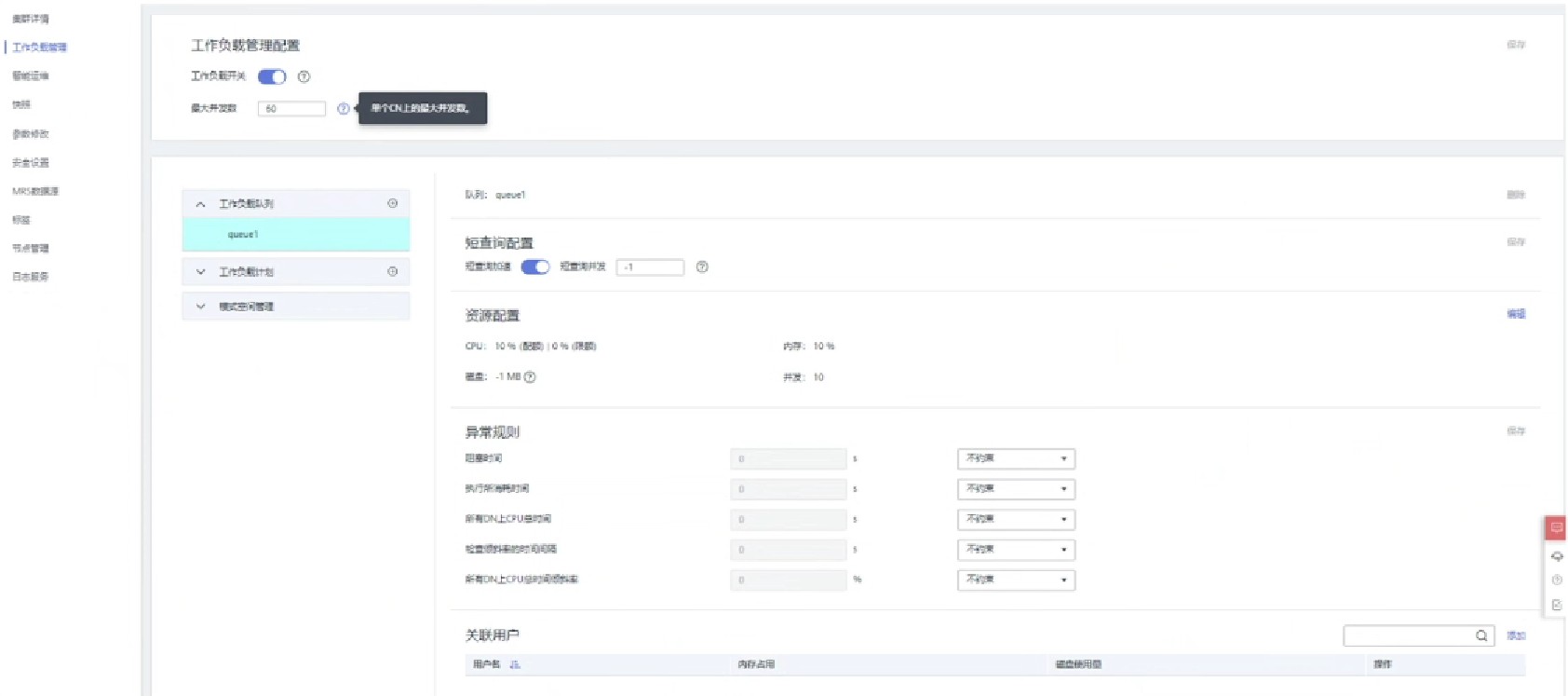
2.工作负载管理概览
二、GaussDB(DWS)工作负载队列介绍与使用
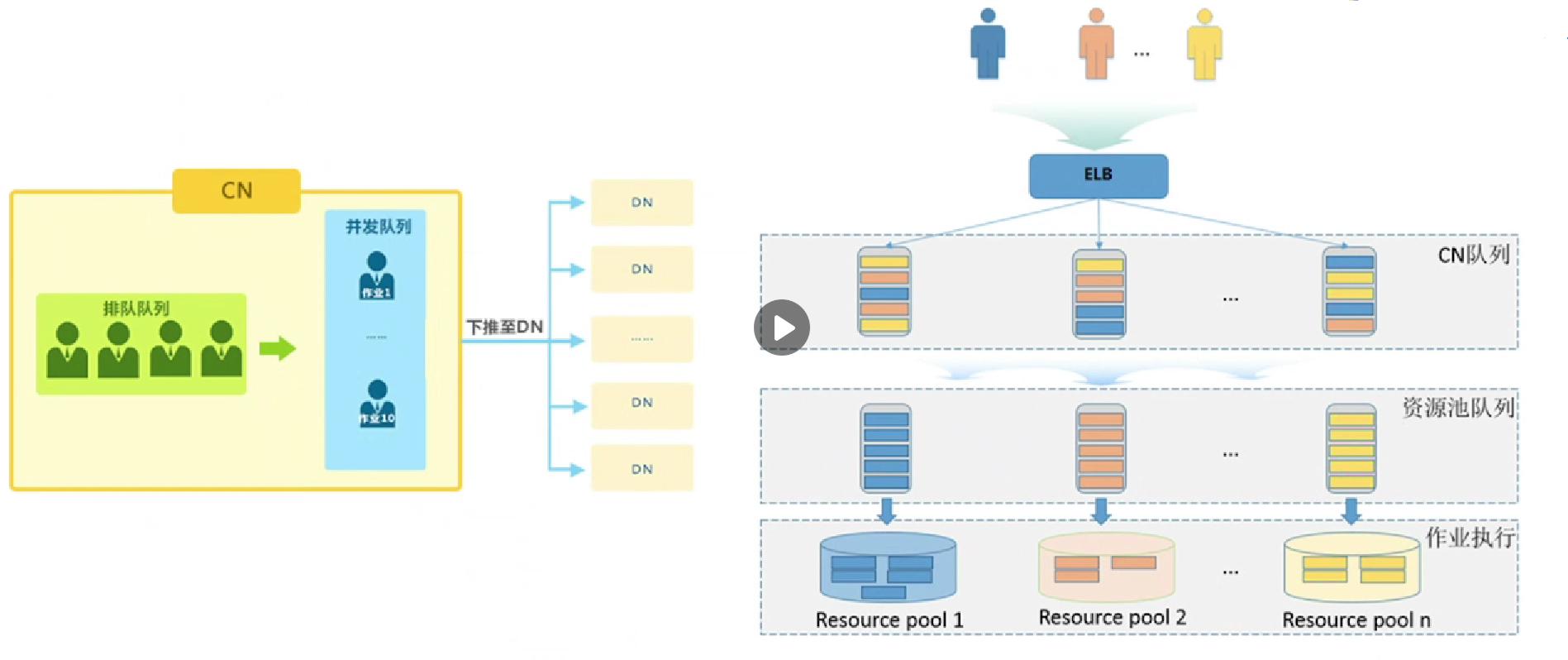
1.工作负载队列机制介绍
2.并发管控能力
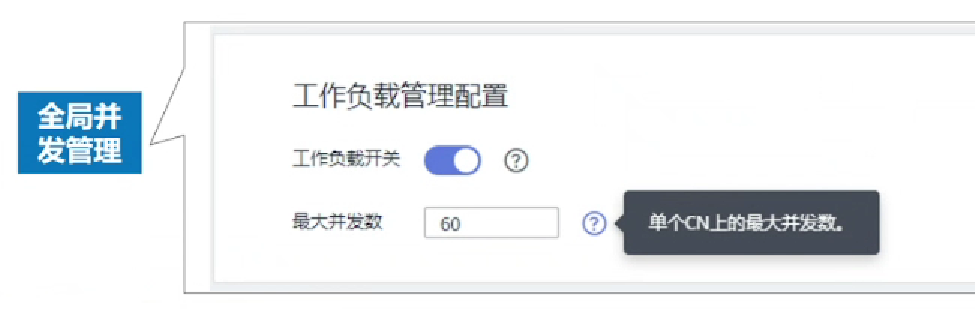
- 全局并发量:是指GaussDB(DWS)上允许同时运行的作业数量。
- 局部并发量:又称队列并发量,是指各个队列上允许运行的最大作业并发量。
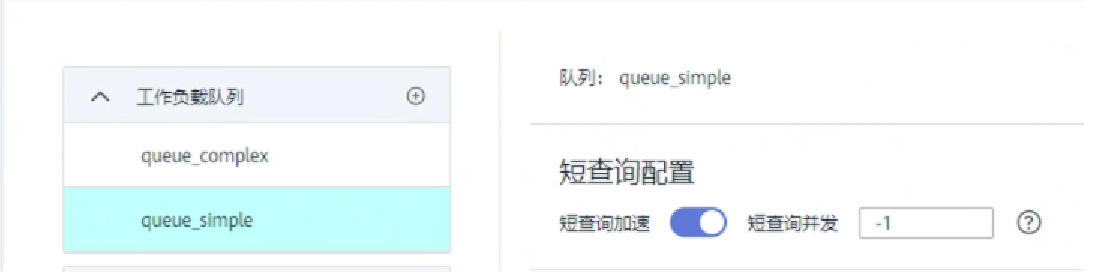
- 短查询并发:简单作业并发数,可以通过短查询开关进行控制,默认不限制。
3.CPU管控
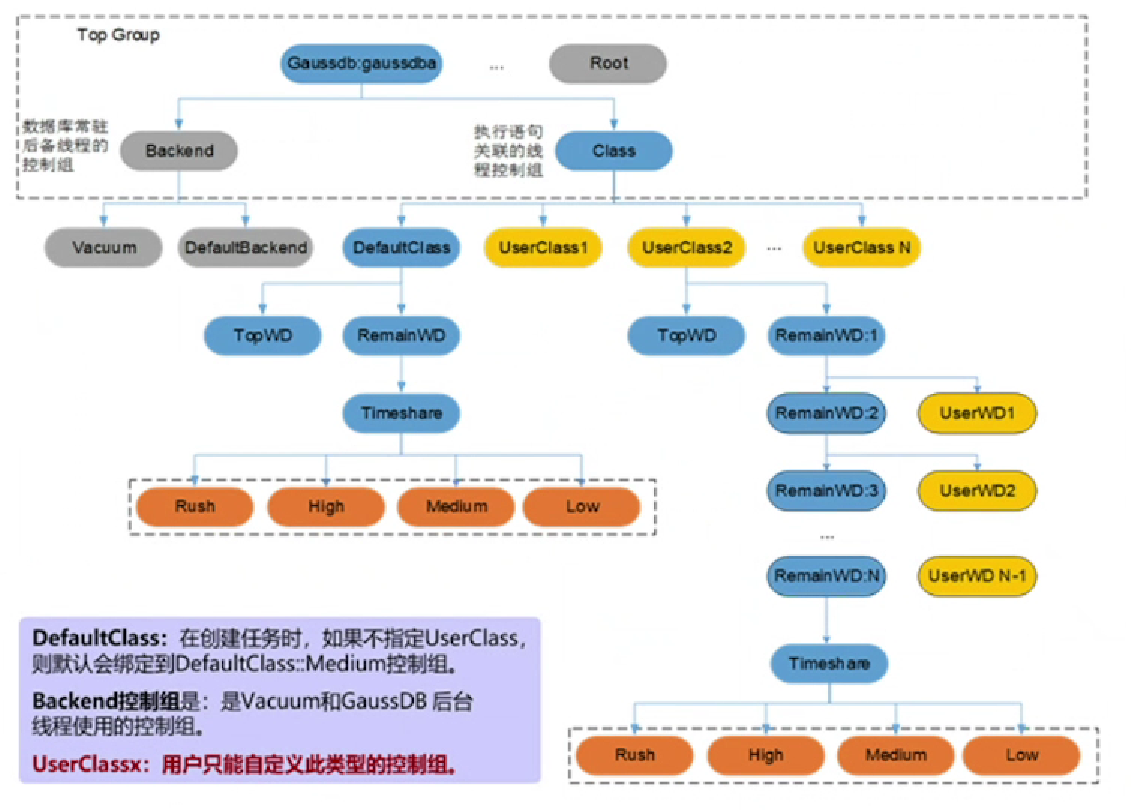
- GaussDB的CPU资源管理通过控制组(cgroup)实现,cgroup是Linux内核提供的一种可以限制单个进程或者多个进程所使用资源的机制, 可以对CPU,内存等资源实现精细化的控制。
- GaussDB支持两层的cgroup架构,包含Class控制组和Workload控制组,支持四个维度隔离:
- GaussDB与其他程序之间隔离
- 后台线程与作业线程之间隔离
- 多租户之间隔离
- 作业之间隔离
- GaussDB支持CPU核数隔离,通过指定cgroup能够使用的CPU核,实现控制组CPU核的隔离。
4.内存管控
- 默认GaussDB(DWS)使用的内存占主机Linux系统可用内存的80%。
- DN实例最大可用内存:max_process_memoryDN=(RAM*0.8)*0.7/(DN_CNT+1)
- CN实例最大可用内存:max_process_memoryCN = max_process_memoryDN/2
- 实例动态内存:max_dynamic _memory = max_process_memory- cstore_used_memory-max_shared_memory-udf_reserved_memory
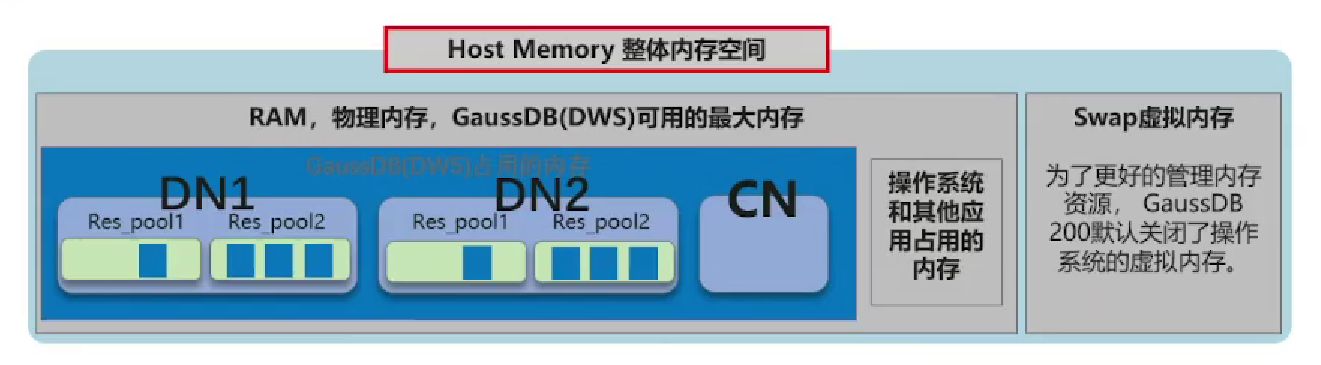
5.空间管控
集群磁盘空间管控
- CM检查数据盘空间占用率,超过阈值后设置集群只读default_transaction_read_only=on
- 只读情况下仅允许只读作业运行,发生写入操作即报错退出
用户空间管控
- 支持永久/临时/算子三个维度表空间管理
- 采用单实例空间管控(CN/DN实例各自管控自身磁盘空间),防止空间倾斜
- 语法:CREATE/ALTER USER…PERM/TEMP/SPILL SPACE
schema空间管控
- 支持schema空间管理
- 语法:CREATE/ALTER SCHEMA…PERMSPACE
单DN单SQL空间管控
- 避免单SQL在单DN上插入数据过大,引发DN数据倾斜
6.异常规则
| 类型 | 说明 |
|---|---|
| blocktime | 作业的阻塞时间,单位为秒。包括全局并发排队以及局部并发排队的总时间。 |
| elapsedtime | 已经被GaussDB(DWS)执行的作业,从开始执行到当前所消耗的时间,单位为秒。 |
| allcputime | 作业在所有datanode上执行时所耗费的cpu总时间,单位为秒。 |
| cpuskewpercent | 作业在datanode上执行时的cpu时间的倾斜率,有效范围为1~100。cpuskewpercent的分析依赖于qualificationtime设置。 |
| spillsize | 作业在DN上下盘数据量,单位MB |
| broadcastsize | 作业在DN上大表广播数据量,单位MB |
| mem_limit | 作业在DN上使用内存量,支持设置KB、MB、GB |
异常动作:
- Abort:退出操作。
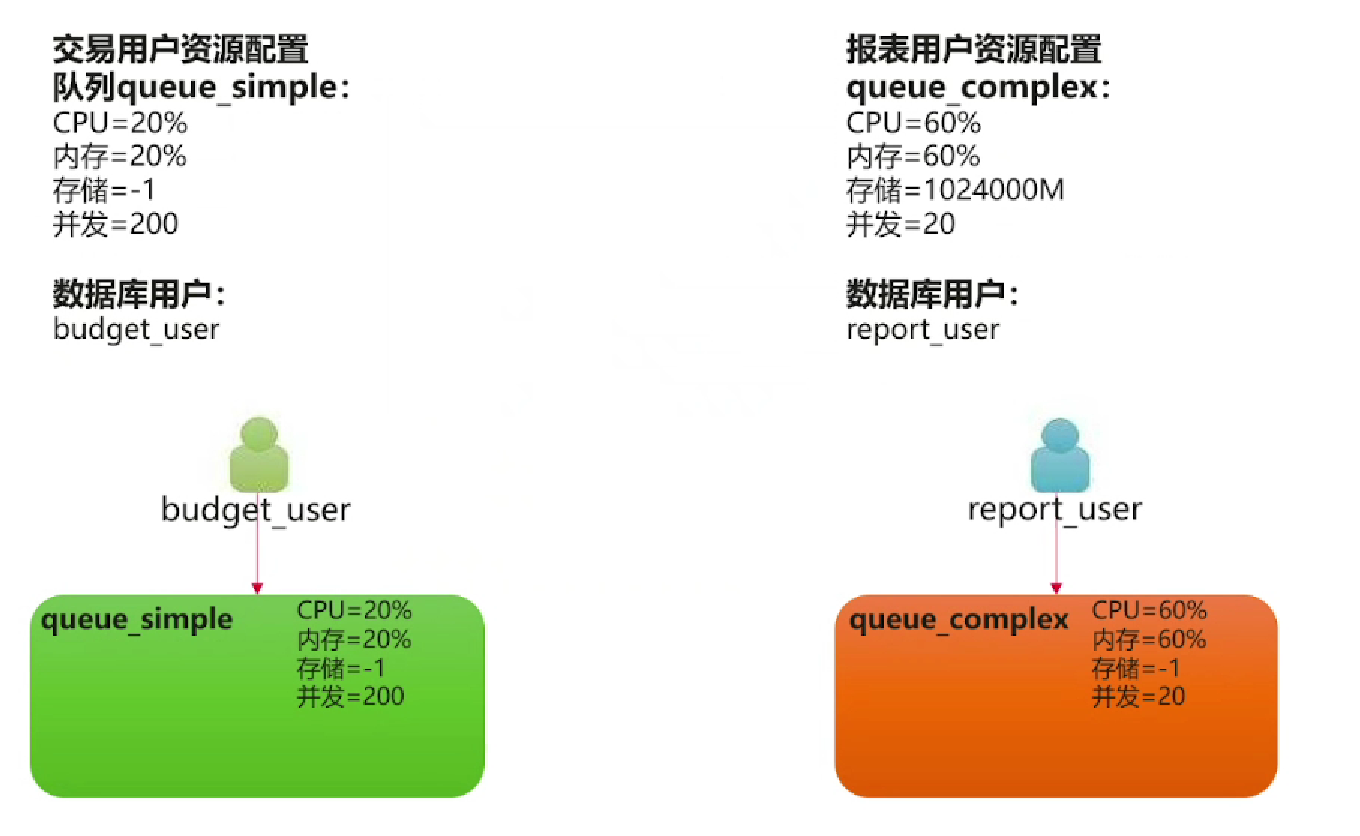
7.工作负载队列案例
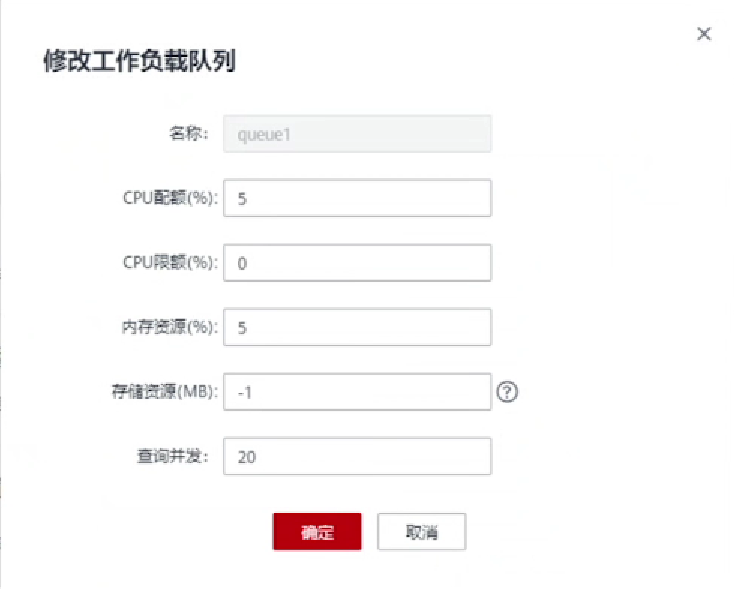
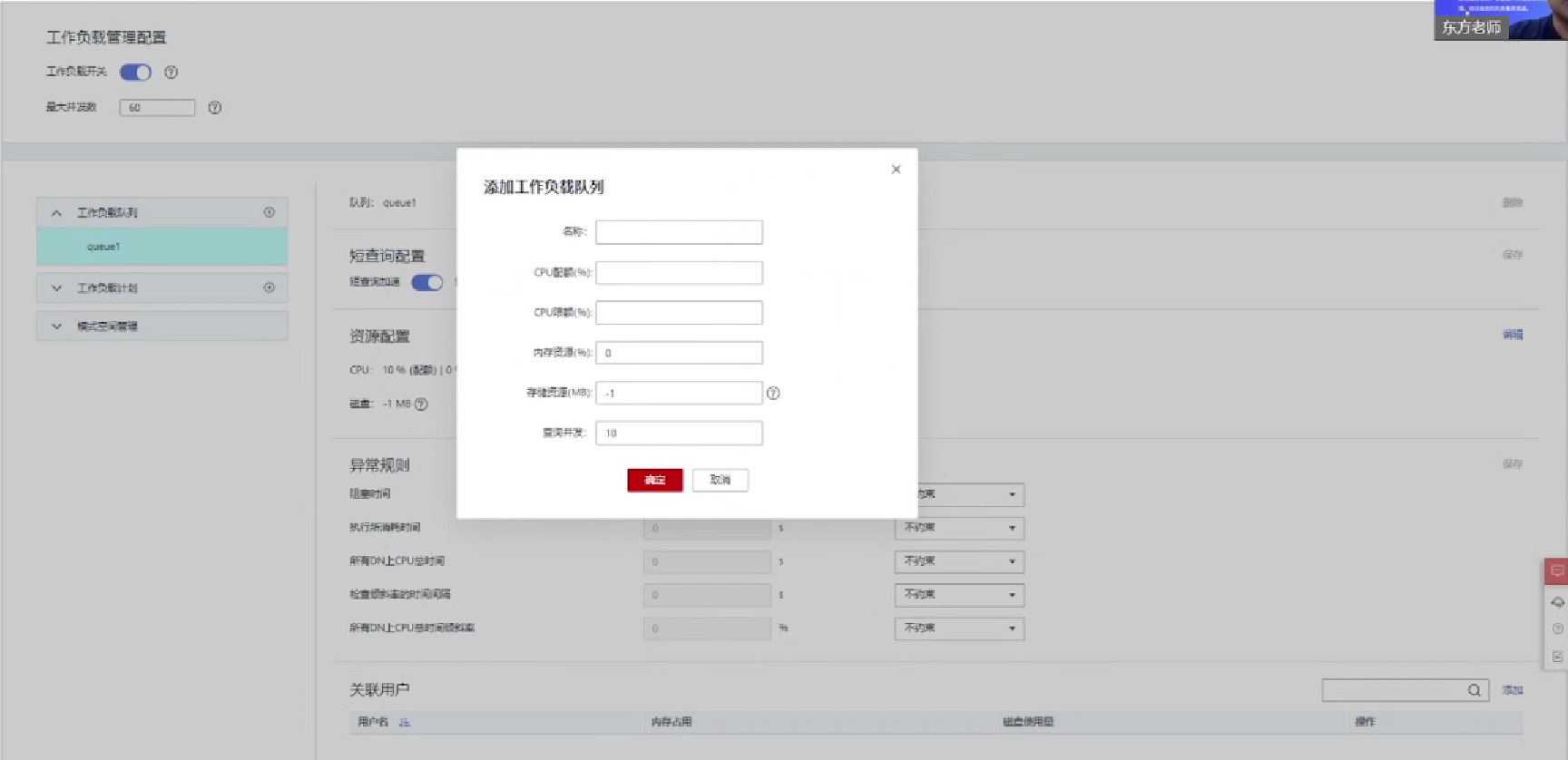
8.创建工作负载队列
9.并发管控测试
1、创建测试用户
create user report_user password 'report_user_12#$'
create user budget_user passwod 'budget_use_12#$'
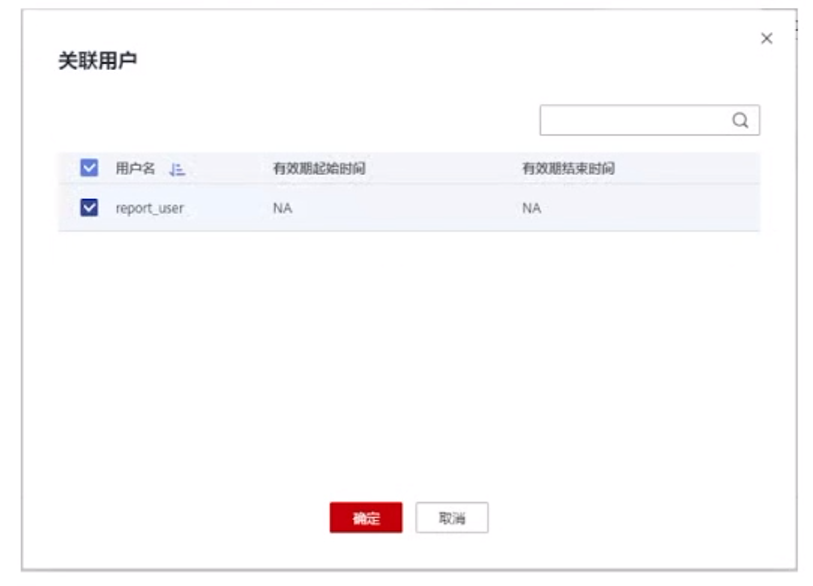
2、用户队列绑定
3、模拟耗时队列
select pg sleep()
9.存储空间管控测试
create table test (id int primary KEY,content text);
CREATE FUNCTION gen_test_data() RETURNS BOOLEAN
AS
$BODY$
DECLARE iINTEGER;
BEGIN
i=1;
FOR iin 0..200000 LOOP
INSERT INTO test VALUES (i,'abcdefghijkabcdefghijksafwr23498vj..');
END LOOP;
RETURN TRUE;
END;
$BODY$
LANGUAGE plpgsql;
select gen_test_data();
三、GaussDB(DWS)工作负载计划介绍与使用
1.工作负载计划适用场景
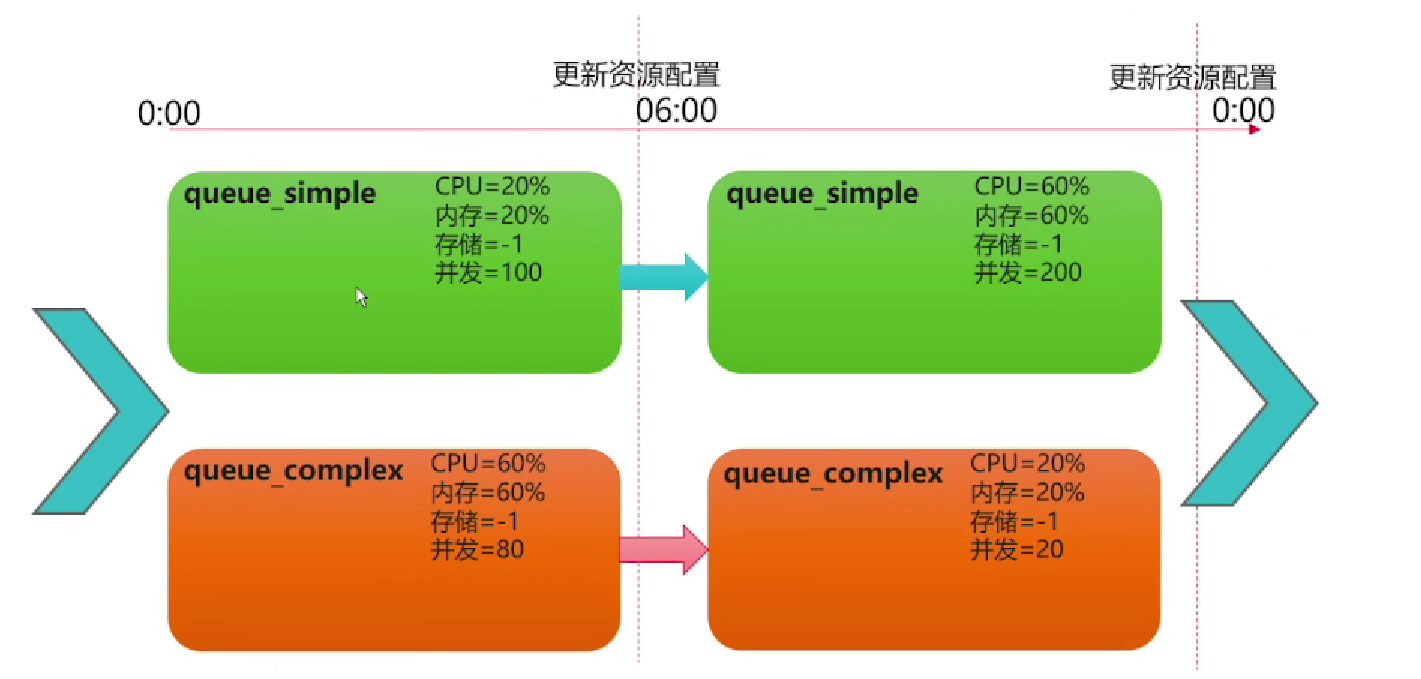
工作负载计划用于自动化的、周期性的对工作负载队列中的资源进行变更,以便实现灵活的负载管理,适应不同的业务需求;以queue_simple和queue_complex为例,每天的0:00-06:00之间交易量大大降低,开始进行批量分析,此时需要重新配置队列的资源占比。
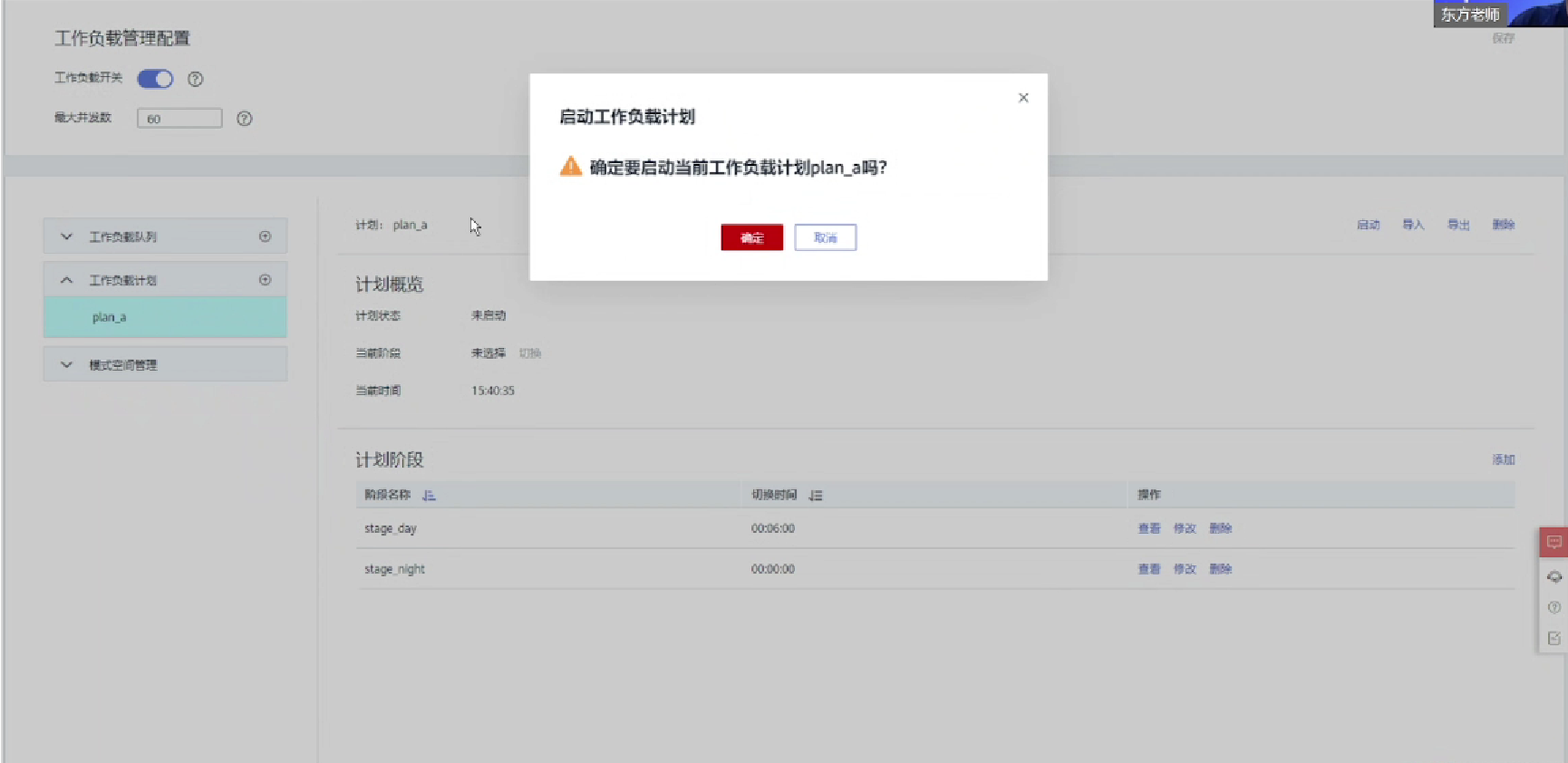
2.启动工作负载计划
3.导入导出工作负载计划
对于有多套集群或者有镜像测试环境的集群,可以在在一套集群中进行配置和测试后将配置导出,然后再导入生产集群或其他集群使用
四、GaussDB(DWS)模式空间管理介绍与使用
GaussDB(DWS)存储资源管理上还提供了Schema级别的空间管控能力,一方面可以实现单实例上的空间管控,避免数据库只读和磁盘满的情况出现;另一方面将空间管控和用户、队列解耦,实现了空间管控和权限的分离,降低用户使用空间管控的难度。
当一个Schema存在空间限制时,在业务执行过程中,如果该Schema下的表数据之和超过空间限制,则会导致业务报错"out of schemas' perm space limit"。
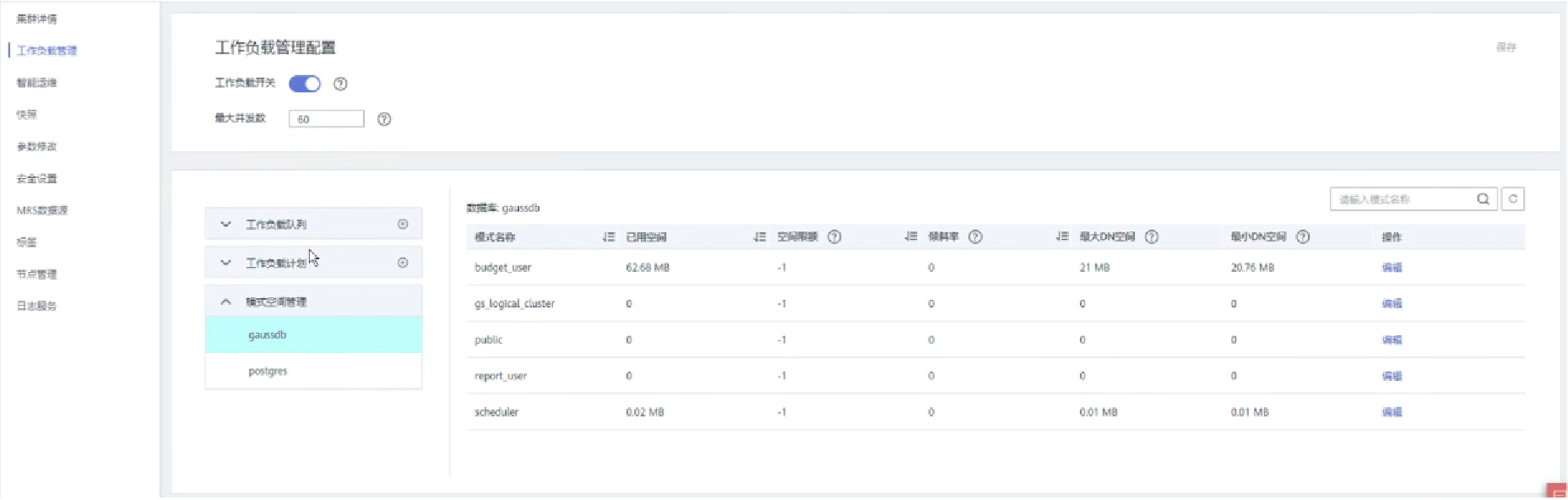
1.修改Schema空间限额
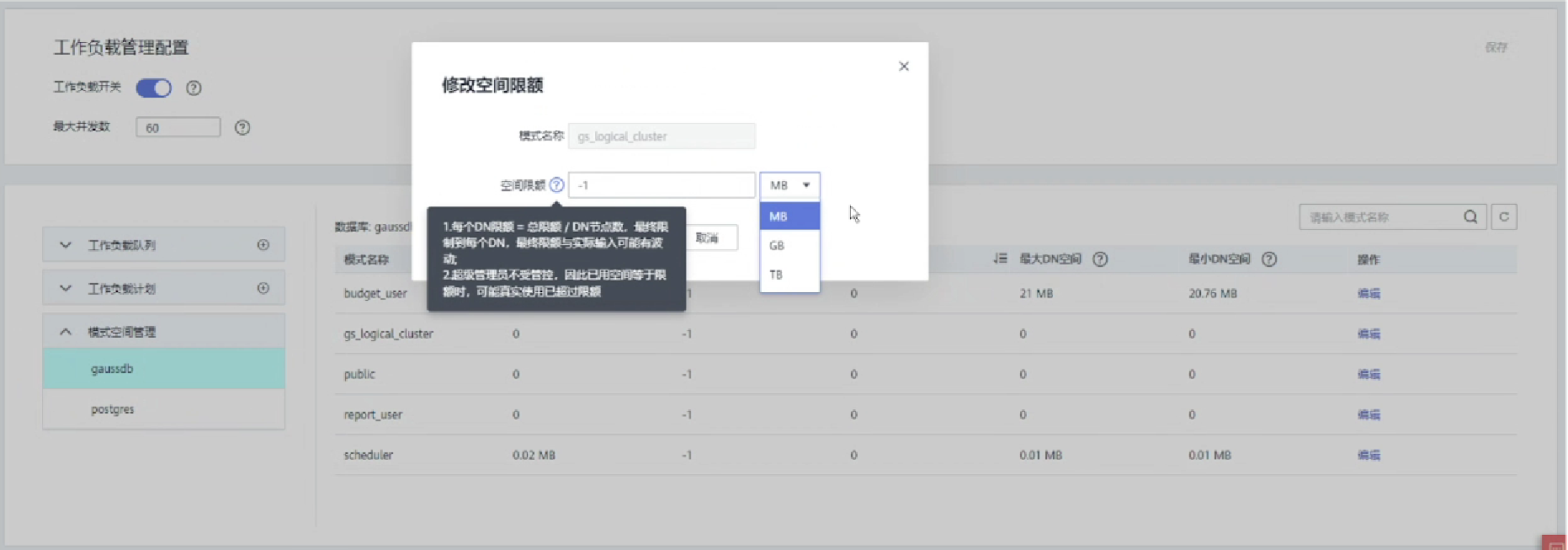
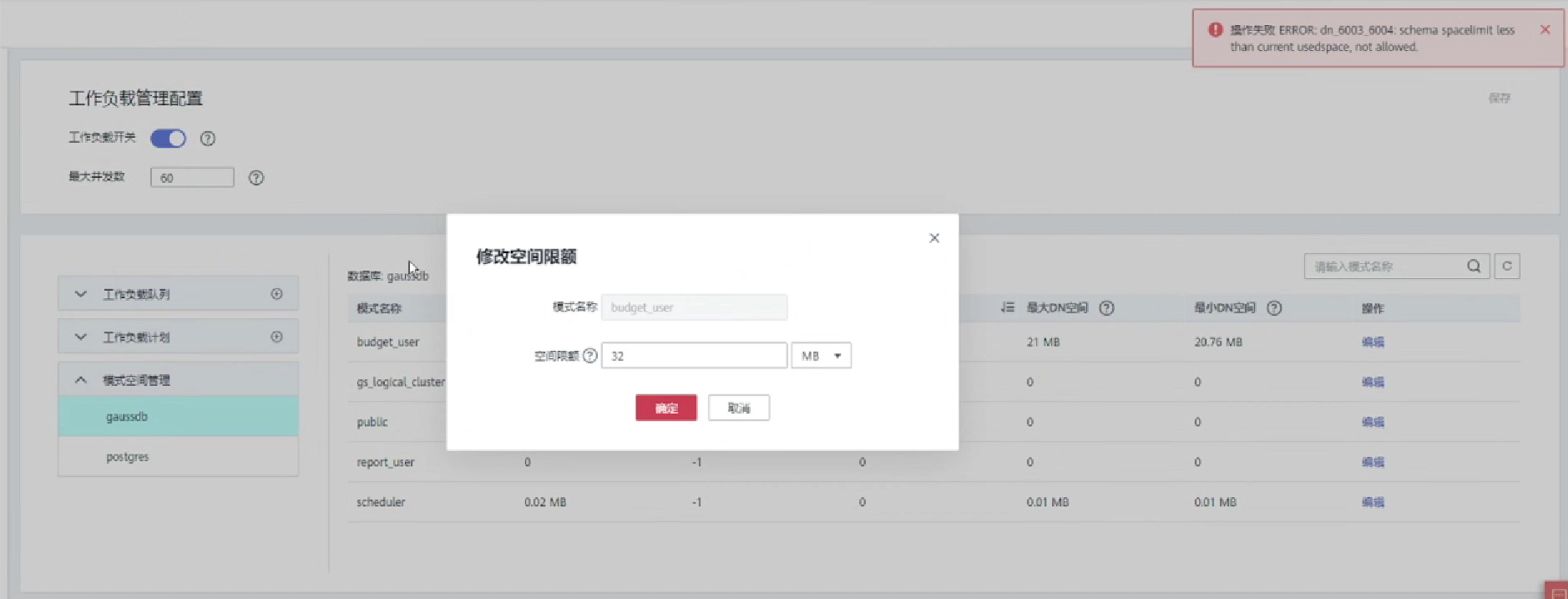
总结
本文讲解GaussDB(DWS)云数仓主要有四部分:GaussDB(DWS)工作负载管理介绍、GaussDB(DWS)工作负载队列介绍与使用、GaussDB(DWS)工作负载计划介绍与使用、GaussDB(DWS)模式空间管理介绍与使用。
在使用GaussDB(DWS)云数仓之前需要了解sql语法和消息队列,并发等知识点。
GaussDB(DWS)实时数仓的特点主要有:
- 快:实时数仓时序数据单机入库性能支持每秒10万条数据、每秒60万条流数据持续计算入库,并可线性扩展。
- 易:支持基于SQL完成复杂流式计算语义定义,简化开发。以Druid监控的一个场景为例,仅用150行SQL代码实现了原有1900行Druid脚本同样的功能。
- 简:实现了1 = N。在一个平台内,同时实现Flink/Spark Streaming(流数据处理)+Druid(流数据预聚合)+InfluxDB(时序数据处理),简化了开发和运维工作。
- 省:时序数据经过实时数仓的自适应压缩算法,可达40:1的压缩比,将多维度行列存储优化,数据冷热温自动分区,极大地减少存储空间,节省用户成本。
GaussDB(DWS)的形态主要有:
- 云数仓:高性价比,支持冷热数据分析,存储、计算弹性伸缩,无限算力、无限容量,并按需、按量计价。适用于“库、仓、市、湖”一体化的融合分析业务,是OLAP分析场景的首选。
- IoT数仓:在云数仓基础上,提供高效的时序计算和IoT分析能力,支持实时和历史数据关联,内置时序算子,最高40x压缩。适用于物联网IoT等实时分析场景。
- 实时数仓:在大规模数据查询和分析能力基础上,提供高并发、高性能、低时延、低成本的事务处理能力。适用于HTAP混合负载场景,“一库两用,生产即分析”,支持单机部署和集群部署两种部署方式。
本文整理自华为云社区【内容共创】活动第19期。
查看活动详情:https://bbs.huaweicloud.com/blogs/370132
相关任务详情:任务16.送一套环境,教您掌握工作负载管理,玩转云数仓
最后
以上就是尊敬大地最近收集整理的关于【云驻共创】GaussDB(DWS)云数仓工作负载管理流程体验前言一、GaussDB(DWS)工作负载管理介绍二、GaussDB(DWS)工作负载队列介绍与使用三、GaussDB(DWS)工作负载计划介绍与使用四、GaussDB(DWS)模式空间管理介绍与使用总结的全部内容,更多相关【云驻共创】GaussDB(DWS)云数仓工作负载管理流程体验前言一、GaussDB(DWS)工作负载管理介绍二、GaussDB(DWS)工作负载队列介绍与使用三、GaussDB(DWS)工作负载计划介绍与使用四、GaussDB(DWS)模式空间管理介绍与使用总结内容请搜索靠谱客的其他文章。








发表评论 取消回复