文章目录
- 创建 Series 的三种方式
- 通过数组(列表)创建
- 通过字典创建
- 通过常量创建
- 查询 Series 的四种方式
- 切片
- index 索引
- head()/tail()
- 条件查询
- 其他常用函数
- 新增一行数据
- 删除一行数据
- 去重
- 排序
- 缺失值检测
从今天开始连载数据分析利器 pandas 的系列文章,推荐 Pycharm 集成 Python3.6+;无论你是零基础小白,还是已经上手过 pandas,你都可以在本次系列中学到一些干货。
摘自百度百科:pandas 是基于 numpy 的一种工具,该工具是为了解决数据分析任务而创建的。pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas 提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使 Python 成为强大而高效的数据分析环境的重要因素之一。
虽然 pandas 基于 numpy,但是在开始 pandas 系列文章前,我并不打算先介绍 numpy 的具体使用,因为 numpy 着重解决的是多维列表或矩阵的数学运算问题,pandas 设计之初就是为了解决实际问题,我认为可以直接上手 pandas,在系列教程中,我会尽量预设读者朋友们没有 numpy 基础,或者说,需要 numpy 知识的地方,我会直接带着说出,我会尽量以 最简洁的文字最少的预备知识,讲完整个 pandas 系列。
作为系列的开篇,本文的中心任务是让每一个读者都熟悉 pandas 中的一种数据结构的概念和基本操作,它就是 Series 。

Series 是一种类似于 一维 数组的对象,由一组数据(数据类型可以是整数、浮点数、字符串和其他 Python 对象)和与之同长度的索引(或称标签)组成。举个例子:
import pandas as pd
# 标签 1 索引 数据'a', 标签 2 索引数据 'b'...
s = pd.Series(data=['a','b','c','d'],index=[1,2,3,4])
print(s)

创建 Series 的三种方式
对于构造函数 pd.Series(),我们最常关心的三个参数是 数据 data、索引 index 和 数据类型dtype,分别可以通过 Series 的 values、index 和 dtype 属性访问。
# 代码接上一段,后同
print(s.values)
print(s.index)
print(s.dtype)
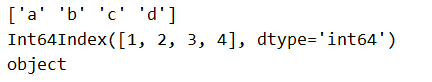
data 是必选参数,index 如缺省,其默认是 range(len(data)),如上面的代码没有指定 index,则 index = [0,1,2,3],而不是[1,2,3,4];dtype 如缺省,默认为 object;
通过数组(列表)创建
data = ['l','o','v','e']
s1 = pd.Series(data=data)
print(s1)

通过字典创建
data = {'math':100,'english':94,'chinese':'95'}
s2 = pd.Series(data=data)
print(s2)

可以看到,字典的键作为索引,值作为数据,创建了 Series
通过常量创建
通过这种方式创建,必须指定 index,他们都索引到同一个值,这个值就是我们给出的常量。
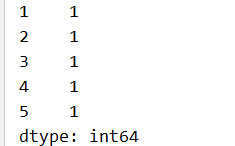
s3 = pd.Series(1,index=[1,2,3,4,5])
print(s3)
查询 Series 的四种方式
以 Series s2 为例:
切片
Series 类似于列表,也提供了切片操作:
print(s2[1:3])

对于切片,要注意两点:一是下标是从 0 开始的,二是前闭后开区间,[1:3] 只包括下标 1、2,也就是 Series 的第二、第三个数据,注意切片的下标和 index 没有关系。
index 索引
这种方式类似于字典的按键取值
print('math',s2['math'])
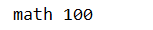
也可以 s2.get('math') 取到 100,如果不确定 math 是否存在于 s2 中,可以通过 s2.get('math',101) 设置缺省值 101,如果不存在,则会返回 101 而不会报错。
head()/tail()
见名知意,head() 是取前几个数据,tail() 是取后几个数据。
print(s2.head())
print(s2.head(2))
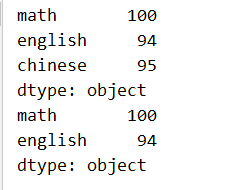
默认是取 5 个,如果不足 5 个则取全部。
条件查询
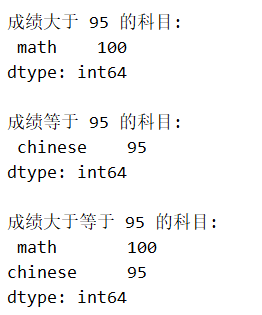
print("n成绩大于 95 的科目:n",s2[s2>95])
print("n成绩等于 95 的科目:n",s2[s2==95])
print("n成绩大于等于 95 的科目:n",s2[s2>=95])
其他常用函数
新增一行数据
有两个函数: append() 和 set_value() 可以完成该功能,不过 append() 只接受 Series/DataFrame 形式参数,是通过新建了一个 Series 完成了修改,必须接受它的返回值;set_value() 比较像 Python 内置的字典新增 item 的方式,是原地修改。
s2 = s2.append(pd.Series({'music':98}))
print(s2)
s2.set_value('history',99)
print(s2)
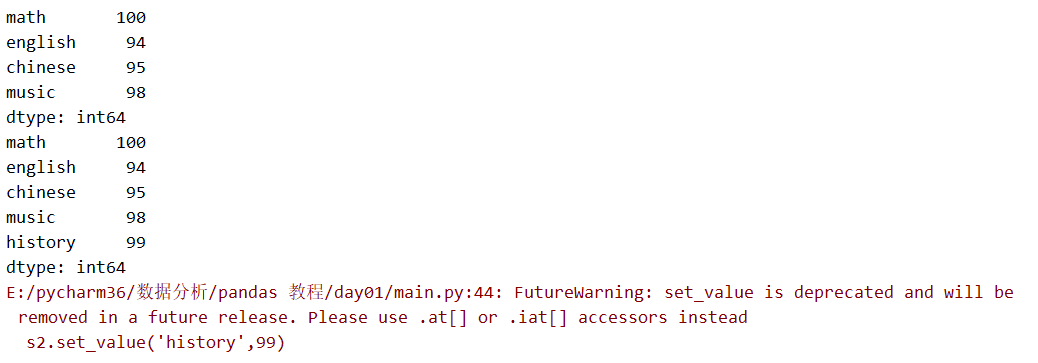
注意上面的警告,set_value() 会在未来的版本中废弃,推荐用 .at[] 或者 .iat[] 表达式。
s2.at['history'] = 93
s2.at['geo'] = 91
print(s2)
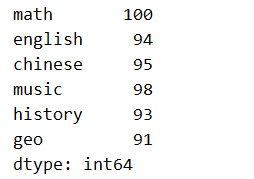
通过实验发现 .at[] 和前面的 index 索引查询效果几乎相同,都可查询,可修改,可新增;所以 .get()/[] 不仅是查询方式,还可以修改新增;.at[] 也可作为查询方式之一,用法灵活。
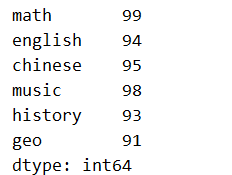
.iat[] 和 .at[] 仅一个 i 的区别,功能相同,这个 i 代表整数的英文 Integer,代表 .iat[] 仅可通过下标访问数据,如修改 math 的成绩为 99:
s2.iat[0] = 99
print(s2)
删除一行数据
使用 drop() 函数即可,注意它不默认是原地修改,需要接收返回值:
s2 = s2.drop('math')
print(s2)
可以通过设置参数 inplace=True 而变成原地修改,下面的代码和上面的代码效果完全相同:
s2.drop('math',inplace=True)
print(s2)
去重
如果仅仅是想获得 data 中的不重复数据,直接用 unique() , 它返回一个列表,Series 本身并没有变化;
如果想去掉 Series 里的重复数据,推荐用 drop_duplicates(),它也有 inplace 参数,另一个重要的参数是 keep,常取值 first/last,即在重复数据中,保留第一个/最后一个。
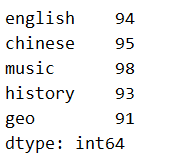
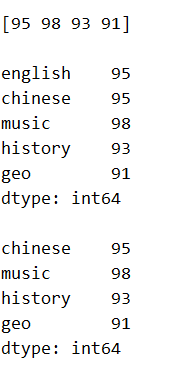
s2['english'] = 95
print(s2.unique(),'n')
print(s2,'n')
s2.drop_duplicates(keep='last',inplace=True)
print(s2)
排序
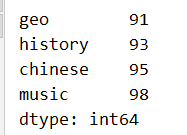
通过 sort_values() 完成排序,主要关注参数 inplace 和 ascending(是否按升序排序,默认为 True,即默认升序排列:
s2.sort_values(inplace=True,ascending=True)
print(s2)
缺失值检测
函数对 isnull()/notnull() 是一对反义函数,见名知意,缺失值检测,返回和 data 同长度的 bool 列表:
s2['bio'] = None
print(s2.isnull(),'n')
print(s2.notnull())

Series 到此为止,作为 pandas 两种数据结构之一,它是另一种数据结构 DataFrame 的基础,只不过 Series 是一维的,DataFrame 是二维表格式的,下一篇就谈 DataFrame,在此之前请先消化好 Series。
最后
以上就是傲娇火最近收集整理的关于数据分析利器 pandas 系列教程(一):从 Series 说起的全部内容,更多相关数据分析利器内容请搜索靠谱客的其他文章。
![pandas中Dataframe的查询方法([], loc, iloc, at, iat, ix)](https://www.shuijiaxian.com/files_image/reation/bcimg22.png)







发表评论 取消回复