说到网络爬虫,就要提到正则表达式和urllib库
python自带re模块和urllib模块
--------------------------------------------------------------------------------------------------------------------------------
正则表达式
正则表达式,又称规则表达式,通常用来检索、替换那些符合某个模式(规则)的文本。
1.原子
w:用来匹配字母、数字、下划线;
d:用来匹配数字;
s:用来匹配空白字符;
W、D、S用来匹配与w、d、s相反的字符。
2、元字符
.:用来匹配任意字符;
^:用来匹配开始位置;
$:用来匹配结束位置;
*:表示重复0次及以上;
?:表示重复0次或一次;
+:表示重复一次及以上;
{3}:表示恰好出现3次;
{3,}:表示至少出现3次;
{4,7}:表示至少出现4次,至多出现7次;
t|s:表示出现t或者s;
[jsz]:表示出现j/s/z中的任意一个;
3.模式修正符
i:不区分大小写;
M:多行匹配;
U:根据unicode进行匹配;
S:让”.“也匹配换行符;
4.贪婪模式与懒惰模式
贪婪模式:尽可能多的匹配;
懒惰模式:尽可能少的匹配;
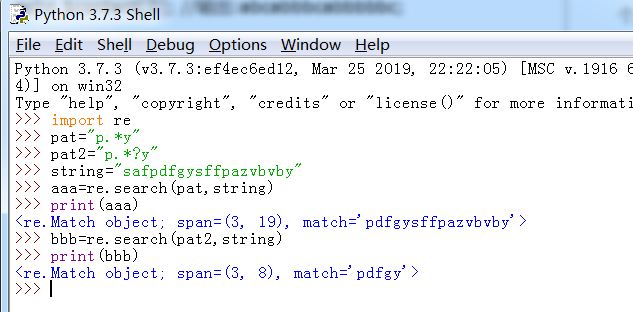
如上所示:pat就是贪婪模式,pat2就是懒惰模式。
5.正则表达式函数
有re.match函数、re.search函数、全局匹配函数和re.sub函数。
re.match函数要从头开始匹配,举例子如下:

全局匹配函数就要会找到所有符合规则的子字符串,而不像search函数只会匹配到第一个复合条件的。
re.compile(pat).findall(string)
pat指的是正则规则,string表示要查找的文本。
re.sub是个正则表达式方面的函数,用来实现通过正则表达式,实现比普通字符串的replace更加强大的替换功能。简单的替换功能可以使用replace()实现。
----------------------------------------------------------------------------------------------------------------------------------
要系统学习urllib模块,我们从urllib基础开始。这个知识点中,我会向大家介绍urlretrieve()函数、urlcleanup()函数、info()函数
以及getcode()函数、geturl()函数等。
urllib.request.urlretrieve(url,filename=None)
利用urlretrieve() 将数据下载到本地。
- 参数 finename 指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据。)
urlcleanup()
可以将urlretrieve()中的缓存清理掉;
info()
可以将当前的基本环境信息显示出来;
getcode()
获取当前的网页的状态码,geturl()获取当前的网页的网址, 200状态码表示网页正常,403表示不正常。
------------------------------------------------------------------------------------------------------------------------------------
自动模拟HTTP请求
1.get请求
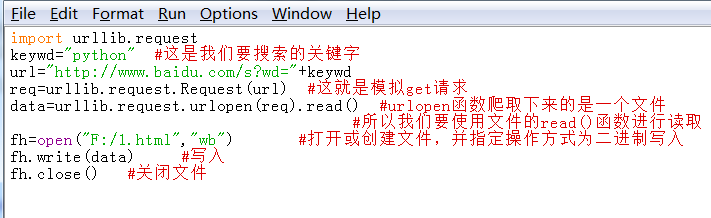
如上所示,这就是一个简单的get请求以及网络爬虫
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=python&oq=python&rsv_pq=97f9cf6d0003595c&rsv_t=fcb7JtYRoovz9V3yOoFkx6Q61ZRxJN73%2BKxJrCuYB2lpWty6GxAxo4uuUco&rqlang=cn&rsv_enter=1&rsv_sug2=0&rsv_dl=tb&inputT=6&rsv_sug4=7
这是一个百度搜索的网址,一些繁琐的东西我们可以拿掉,保留下重要的信息
http://www.baidu.com/s?wd= (这就是我们经过分析得到的规则)
2.post请求
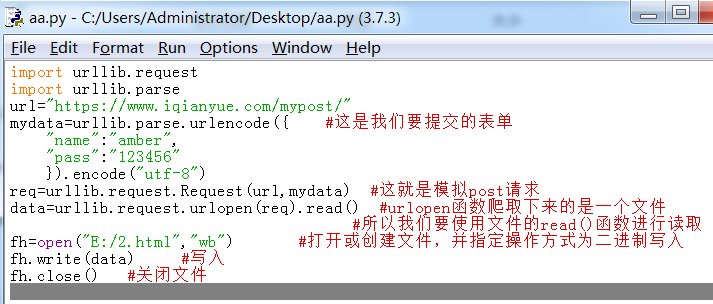
首先,我们打开https://www.iqianyue.com/mypost/网页,查看源代码,找到我们要提交的内容

name属性里面就是我们要提交的内容,有时候我们需要进行抓包,找到提交表单的正确url
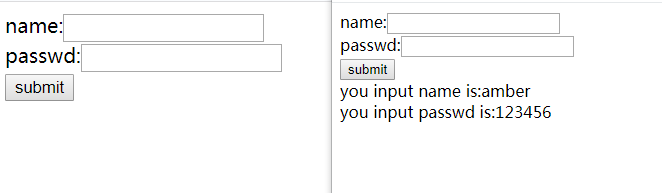
这就是提交表单前和表单后的网页。
学习一定要多敲代码,多敲,多敲,一点点地进步!!
最后
以上就是高兴寒风最近收集整理的关于pandas网络爬虫(一)的全部内容,更多相关pandas网络爬虫(一)内容请搜索靠谱客的其他文章。
![pd.IndexSlice[]应用疑问](https://www.shuijiaxian.com/files_image/reation/bcimg20.png)

![pandas中Dataframe的查询方法([], loc, iloc, at, iat, ix)](https://www.shuijiaxian.com/files_image/reation/bcimg22.png)





发表评论 取消回复