一、什么是模块
模块就是一组功能的集合体,模块组织形式有以下几种
1、一个python文件是一个模块,文件名是module.py,模块名则是module(自定义模块的常见格式)
2、 已被编译为共享库或DLL的C或C++扩展
3、使用C编写并链接到python解释器的内置模块
4、把一系列模块组织到一起的文件夹(注:文件夹下有一个__init__.py文件,该文件夹称之为包)
二、为什么要用模块
1、可以将程序中频繁用来的一些公共的功能组织到一个文件中,从而减少代冗余
2、直接使用内置或者第三方的模块中的功能,这种拿来主义可以提升开发效率
三、如何用模块
导入模块的方式:
import sudada #导入一个模块sudada(在当前目录下)
from sudada import xx #导入一个模块sudada,只使用模块内的xx这个变量
from sudada.X.X import xx as rename #导入多个模块,并给这些模块定义一个别名
from sudada.X.X import * #导入多个模块,使用模块内所有的变量(*代表所有)
模块导入需要注意的点:
导入多个相同的模块,只会执行一次
四、模块的导入与使用
4.1 import 方式
首次导入模块spam:spam为一个测试的文件(内容如下: )
print('from the spam.py')
money=1000
read1=100
read2=200
def szq():
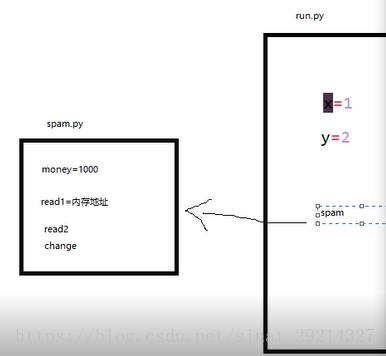
print("from sudada")1、会产生一个模块spam的名称空间。
2、会执行spam模块文件里的代码,将产生的名字放到spam模块的名称空间中。
3、会在当前run.py名称空间中拿到一个模块名spam,该模块名spam指向spam.py模块的名称空间。
import parm # 导入模块parm
print(parm.money) # 引用parm模块中的money时,不能直接写变量名(直接写money找到的是当前文件内的变量money),需要在变量名前加模块名(parm.money)
>>: 1000
import parm as sm # 导入模块指定一个别名为sm,那么引用这个别名sm即可
print(sm.money)
>>: 1000
import parm, sudada, ssp #引用多个模块,中间用逗号隔开
from spam import szq # 引用模块内的一个值(函数),那么加()即可执行
szq()
>>:from sudada优点:指名道姓的访问模块名称空间的名字,不会与当前名称空间的名字冲突
缺点:每次引用模块时都需要加模块名前缀
4.2 from ... import ... 方式
首次导入模块:spam为一个测试的文件(内容如下: )
print('from the spam.py')
money=1000
read1=100
read2=200
1、会产生一个模块的名称空间。
2、会执行模块文件的代码,将产生的名字放到模块的名称空间中。
3、会在当前名称空间中直接拿到一个模块名称空间的名字。
强调:来自于模块parm名称空间内的函数,调用该函数时一定是以模块parm内的名称空间为准的。
from parm import money #导入模块parm中的money
print(money)
>>: 1000
from parm import money,read1,read2 #导入模块parm中的money,read1,read2,用逗号分开
print(money)
print(read1)
print(read2)
>>: 1000
>>: 100
>>: 200
from parm import money as sm #导入模块parm中的money并给money定义别名为sm
print(sm)
>>: 1000优点:使用方便简介
缺点:容易与当前名称空间的名字冲突
导入模块内所有的名字 -- 不推荐使用,因为导入模块内所有的内容时,容易与当前名称空间的名字冲突。除非在我们需要引入模块中很多名字的时候,可以用*,起到一个节省代码的作用。
from parm import * #导入模块parm中的所有名称空间的名字(*表示所有),不推荐使用
print(money)
print(read1)
print(read2)
5、自定义导入模块内的某个名字 -- 那么在使用该模块时只能使用指定的名字
spam为一个测试的文件(内容如下: )
print('from the spam.py')
money=1000
read1=100
read2=2001.在模块内(文件的开头)写一个内置变量"__all__=['money','read1']"
__all__=['money','read1']2.使用from parm import *时,*号表示的就是money和read1这2个变量了
from parm import *
print(money)
print(read1)
五、Python脚本与Python模块的区别
5.1、使用内置函数"__name__"来区分Python脚本与Python模块
1、当sparm.py这个文件当做Python脚本使用时,使用print(__name__)得到的返回值为"__main__"
# 在spqrm.py文件里面填上代码:只写一行
print(__name__)
>> :__main__ #运行python文件时,返回值为"__main__"表示当前文件为python脚本文件2、当sparm.py这个文件当做Python模块导入使用时,使用print(__name__)得到的返回值为为"sparm(模块名)"
# 在run.py文件里面使用import sparm,然后右键执行
import sparm
>>:sparm #被当做模块引用时,返回值为"sparm(模块名称)"
5.2、区分python文件的用途 Python脚本或Python模块
1、通常在一个被当做模块使用的(python文件)末尾加上条件判断,定义这个python文件的用途(当做模块还是脚本文件)
if __name__ == '__main__':
money
read1()
read2()
# 当这个python文件被当做脚本使用时,会调用money,read1(),read2()三个参数
# 当这个python文件被当做模块使用时,则不会调用任何参数
六、模块的搜索路径
6.1、查找模块的先后顺序 -- 内存--->内置--->sys.path (环境变量)
查看当前模块所在的路径:sys模块 -- sys.path的值是以当前执行文件为准(sys.path的值为当前文件所在的目录)
import sys
print(sys.path)
>>:['C:\Users\stsud\Desktop\Pycharm文档', 'C:\Users\stsud\Desktop\Pycharm文档', 'C:\Install Path\Python3.6\python36.zip', 'C:\Install Path\Python3.6\DLLs', 'C:\Install Path\Python3.6\lib', 'C:\Install Path\Python3.6', 'C:\Install Path\Python3.6\lib\site-packages', 'C:\Install Path\Python3.6\lib\site-packages\pip-10.0.1-py3.6.egg', 'C:\Install Path\Pycharm-破解版\PyCharm 2018.1\helpers\pycharm_matplotlib_backend']
6.1.1、当一个python文件导入另外一个python文件,并且2个文件都不在同一目录时,那么需要把被导入的文件所在的目录加入到全局路径:
import sys
sys.path.append(r'C:UsersstsudDesktopPycharm文档ATM-1core') #指定目标文件所在的路径6.2、查看当前文件所在的路径(使用OS模块)
import os
查看当前代码所在的文件绝对路径
print(os.path.abspath(__file__))
>>:C:UsersstsudDesktopPycharm文档ATM-1binstart.py
查看当前代码所在文件的目录
print(os.path.dirname(os.path.abspath(__file__))) 或者
print(os.path.dirname(__file__))
>>:C:UsersstsudDesktopPycharm文档ATM-1bin
查看当前代码所在文件的上一级目录
print(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
>>:C:UsersstsudDesktopPycharm文档ATM-1
七、软件开发的目录规范 -- 新建一个项目,然后在项目的运行文件run.py内,把整个项目的根目录加入到环境变量里面。
7.1、在run.py文件内导入不同目录下的python模块 # run.py是程序的执行文件,由于run.py在处理环境变量时,把ATM这个目录加入到环境变量里面去了,所以整个代码都是以run.py的环境变量为准的!
将run.py文件所在的上一级目录作为整个项目的根目录,然后将这个根目录添加到环境变量里面去:
import sys
import os
BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) #BASE_DIR就是整个项目的根目录
sys.path.append(BASE_DIR) #把定义的根目录追加到"sys.path"(系统的环境变量)里面
print(BASE_DIR) # C:UsersstsudDesktopPycharm文档ATM-1
from core import src #使用from导入core目录下的src模块
if __name__ == '__main__': #条件判断python文件是脚本使用还是当做模块使用
src.run() #运行src模块下的函数run() 强调:在run.py文件内把"BASE_DIR"也就是整个项目的根目录加到"sys.path.append(BASE_DIR) "系统的环境变量 里面去之后,在run.py文件内就可以使用"from 目录名 import 模块名"导入根目录下任何模块,当前根目录下的其他python文件在导入某一个模块时,同样可以使用 "from 目录名 import 模块名"的方式导入。
7.2、在python代码里面如何调用一个 "非python文件类型的文件(python文件可以直接使用from XX import *的方式引用)" ,比如 *.json文件,*.log文件。
1、获取一个目录的绝对路径,方法:DB_PATH=os.path.join(/root,'db'),那么DB_PATH的值就是 "/root/db"
注释: os.path.join:合理地拼接一个或多个路径。返回值是 path 和 "paths" 所有值的连接,
例:os.path.join( /root/ , "/conf" ) 拿到的值就是 /root/conf 这个目录的绝对路径。
例:os.path.join( /root/ , "access.log" ) 拿到的值就是 /root/access.log 这个文件的绝对路径。(拿到这个文件的全局路径,就可以直接调用这个文件了)
一、先定义根目录
import os
1、BASE_PATH=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
2、定义"DB_PATH"对应的是根目录下的哪个目录
DB_PATH=os.path.join(BASE_PATH,'db') #os.path.join后面接"根目录"以及"DB_PATH"所在的目录
二、在其他python文件里面如何调用"DB_PATH"里面的文件
1、from conf import setting #先导入定义了"DB_PATH"所在的模块
2、json_file=os.path.join(setting.BASE_DB, 'test.json') #调用"BASE_DB"下的"test.json"文件
八、模块的一种使用形式--包
8.1、什么是包?
包本质就是模块:意味着包就是用来被导入使用的。
包就是有一个包含有__init__.py文件的文件夹。
包的用途:是来组织/存放多个子模块。
8.2、包下面的__init__.py文件的作用是什么?
导入一个包(文件夹),由于文件夹里面没有任何代码,所以导入这个包什么都拿不到。但是import的语法不会改变,import会导入一个文件,并产生名称空间, 并执行文件里面的代码。
所以这个包(文件夹)里面就需要一个文件(__init__.py),这个文件就是这个包(文件夹)的替代品。那么在导入这个包(文件夹)时,就去找__init__.py这个文件(替代品),以__init__.py文件为基础生成名称空间,并执行__init__.py文件里面的代码。
综上所述:导入一个包,会生成名称空间并执行代码,由于文件夹不能做这个事,所以需要为每个文件内配置一个__init__.py文件来做这个事。
8.3、首次导入包aaa:
1、以包下的__init__.py为准产生一个名称空间,那么每次取值都会去__init__.py文件里面找名称空间。
2、执行__init__.py文件,将执行过程中产生的名字都放入名称空间中。
3、在当前执行文件中会拿到一个名字aaa,aaa就是指向__init__.py的名称空间。
最后
以上就是现代豌豆最近收集整理的关于Python(三)模块使用部分1——模块的导入与使用,包的使用的全部内容,更多相关Python(三)模块使用部分1——模块内容请搜索靠谱客的其他文章。








发表评论 取消回复