Oracle_Day11(存储函数、触发器、包、数据库管理和设计、数据库设计)
存储函数:
语法:
Create or replace function 函数名(参数 in/out 数据类型) return 数据类型 is
结果变量 数据类型;
Begin
函数体;
Return(结果变量);
End;
存储过程和函数的区别:
一般来讲,过程和函数的区别在于函数可以有一个返回值,而过程是没有返回值的。
但是,过程和函数都可以通过out指定一个或多个输出参数,在其中我们也可以利用out参数,在过程和函数中实现返回值的操作。
--使用函数来查询指定员工的年薪
create or replace function empincome (eno in emp.empno%type)
return number--指定返回值 的类型
is psal emp.sal%type;--我们返回结果的时候 结果的保存变量
pcomm emp.comm%type;
begin
select sal,comm into psal,pcomm from emp where empno = eno;
return psal * 12 +nvl(pcomm,0);
end empincome;
调用函数:
declare
income number;
begin
income := empincome(7369);
dbms_output.put_line(income);
end;
存储过程的实现,使用out参数来返回结果:
create or replace procedure empincomepro(eno in emp.empno%type,income out number)
is
psal emp.sal%type;
pcomm emp.comm%type;
begin
select sal,comm into psal,pcomm from emp where empno =eno;
income :=psal * 12 + nvl(pcomm,0);
end empincomepro;
存储过程的调用:
declare
income number;
begin
empincomepro(7369,income);
dbms_output.put_line(income);
end;
传参方式:
- 位置传参
declare
income number;
begin
empincomepro(7369,income);
dbms_output.put_line(income);
end;
- 名称传参
declare
income number;
begin
empincomepro(eno => 7369,income => income);
dbms_output.put_line(income);
end;
名称传参不受参数所在位置的限制
declare
income number;
begin
empincomepro(income => income,eno=>7369);
dbms_output.put_line(income);
end;
- 混合传参
declare
income number;
begin
empincomepro(7369,income=>income);
dbms_output.put_line(income);
end;
示例2:
-- 获取某部门的工资总和及部门人数
create or replace function get_salary(
dept_no number,--如果没有明确指定in/out 则默认为in
emp_count out number)
return number is
v_sum number;
begin
select sum(sal),count(*) into v_sum,emp_count from emp where deptno=dept_no;
return v_sum;
end get_salary;
函数的调用:
declare
v_num number;--作为输出参数,保存部门人数
v_sum number;--作为返回值 保存工资总和
begin
v_sum := get_salary(30,emp_count=>v_num);
dbms_output.put_line('工资总和为:' || v_sum||',人数为:'||v_num);
end;
在使用混合传参的时候 如果第一参数使用了名称表示法,则其后的所有的参数的传递必须使用名称表示法。
异常的处理:
-- 获取某部门的工资总和及部门人数
create or replace function get_salary(
dept_no number,--如果没有明确指定in/out 则默认为in
emp_count out number)
return number is
v_sum number;
begin
select sum(sal),count(*) into v_sum,emp_count from emp where deptno=dept_no;
return v_sum;
exception
when NO_DATA_FOUND THEN
dbms_output.put_line('你所查询的数据不存在');
when OTHERS then
dbms_output.put_line('发生了异常');
end get_salary;
触发器:
触发器是一个与表相关量的 存储的PLSQL程序,每当一个特定的数据操作语句发出时,Oralce会自定的执行的一个PLSQL程序。
触发器的应用时机:
- 数据的确认;
- 实施复杂的安全性检查
- 做审计,跟踪表上所作的数据操作等。
- 数据的备份和同步
触发器的类型:
语句级触发器:在指定的操作语句操作之前或之后执行一次,不论这条语句影响了多少行。
行级触发器:(for each row) 触发语句作用的每一条记录都被触发,在行级触发器中 可以使用old和new伪记录比那来那个,识别值的状态。
语法:
语法: create or replace trigger 触发器名称
【before|after】
[delete| insert |update [of 列名]] on 表名
For each row【when(条件)】
Begin
Plsql程序;
End;
示例:
--插入员工 信息后 打印一句话:新员工插入成功
create or replace trigger testTri
after insert on emp1
declare
begin
dbms_output.put_line('新员工插入成功');
end testTri;
当我们定义好触发器之后 ,我们不需要自己主动的去调用,当我们的操作满足触发器的触发条件的时候 ,oracle会自动的执行触发器。
行级触发器:
| 行级触发器中存在两个伪变量 : | old | new |
|---|---|---|
| Insert | 所有的字段都是null | 将要插入的数据 |
| Update | 更新以前改行的值 | 和更新后的值 |
| Delete | 删除以前改行的值 | 所有的字段都是空 |
示例:
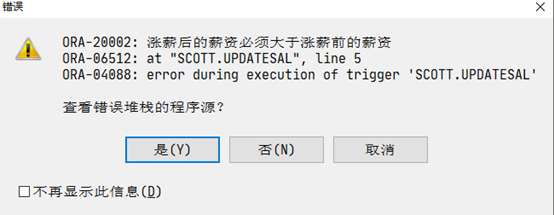
--当更新员工的薪资的时候,涨薪之后的薪资的值一定要大于涨薪之前的值
create or replace trigger updateSal
before update of sal on emp1
for each row
begin
if
:old.sal >= :new.sal
then
raise_application_error(-20002,'涨薪后的薪资必须大于涨薪前的薪资');
end if;
end updateSal;
测试:
update emp1 set sal = sal + 100;
update emp1 set sal = sal - 1;
使用触发器完成删除记录的备份:
当删除emp1表中的记录时,则将删除的记录保存到删除备份表中。
创建一个备份记录表:
create table emp_bak as select * from emp1 where 1=2;
触发器:
-- 当删除emp1表中的记录时,自定将删除的记录保存到emp_bak表中
create or replace trigger delemp_bak
before delete --触发时机:删除之前
on emp1 --作用在emp1表
for each row--行级触发器
declare
begin
insert into emp_bak(empno,ename,job,mgr,sal,comm,hiredate,deptno)
values(:old.empno,:old.ename,:old.job,:old.mgr,:old.sal,:old.comm,:old.hiredate,:old.deptno);
end delemp_bak;
包
包的使用:
create package 包名 as 是存储过程或函数
end;
定义包:
create package emp_addsal as
procedure getsal(eno emp.empno%type);
end;
包体:
create or replace package body emp_addsal as
procedure getsal(eno emp.empno%type) is
v_esal emp.sal%type;
begin
select sal into v_esal from emp where empno=eno;
dbms_output.put_line(v_esal);
end getsal;
end emp_addsal;
执行:
declare
eno emp.empno%type :=&eno;
begin
emp_addsal.getsal(eno);
end;
数据库管理和设计
数据库备份:
Oracle数据库有三种标准的备份方法,它们分别是导出/导入(EXP/IMP)、热备份和冷备份。导出备件是一种逻辑备份,冷备份和热备份是物理备份。
冷备份:
需要备份的文件
–数据文件
select status,enabled,name from v
d
a
t
a
f
i
l
e
;
−
−
控
制
文
件
s
e
l
e
c
t
∗
f
r
o
m
v
datafile; --控制文件 select * from v
datafile;−−控制文件select∗fromvcontrolfile;
–日志文件
select * from v$logfile;
热备份:
热备份是在数据库运行的情况下,采用archivelog mode(归档)方式备份数据库的方法。所以,如果你有昨天夜里的一个冷备份而且又有今天的热备份文件,在发生问题时,就可以利用这些资料恢复更多的信息。热备份要求数据库在Archivelog方式下操作,并需要大量的档案空间。一旦数据库运行在archivelog状态下,就可以做备份了。热备份的命令文件由三部分组成:
- 数据文件一个表空间一个表空间的备份。
(1) 设置表空间为备份状态
(2) 备份表空间的数据文件
(3) 回复表空间为正常状态 - 备份归档log文件
(1) 临时停止归档进程
(2) 备份下那些在archive redo log目录中的文件
(3) 重新启动archive进程
(4) 备份归档的redo log文件 - 用alter database backup controlfile命令来备份控制文件
热备份的优点是:
- 可在表空间或数据库文件级备份,备份的时间短。
- 备份时数据库仍可使用。
- 可达到秒级恢复(恢复到某一时间点上)。
- 可对几乎所有数据库实体做恢复 。
- 恢复是快速的,在大多数情况下可以再数据库仍工作时恢复。
热备份的不足是:
- 不能出错,否则后果严重。
- 若热备份不成功,所得结果不可用于时间点的恢复。
- 因难于维护,所以要特别仔细小心,不允许“以失败告终”。
导出与导入:
导出/导入(Export/Import)
利用Export可将数据从数据库中提取出来,利用Import则可将提取出来的数据送回到Oracle数据库中去。
简单导出数据(Export)和导入数据(Import)
Oracle支持三种方式类型的输出:
(1)表方式(T方式),将指定表的数据导出。
(2)用户方式(U方式),将指定用户的所有对象及数据导出。
(3)全库方式(Full方式),数据库中的所有对象导出。
数据导入(Import)的过程是数据导出(Export)的逆过程,分别将数据文件导入数据库和将数据库数据导出到数据文件
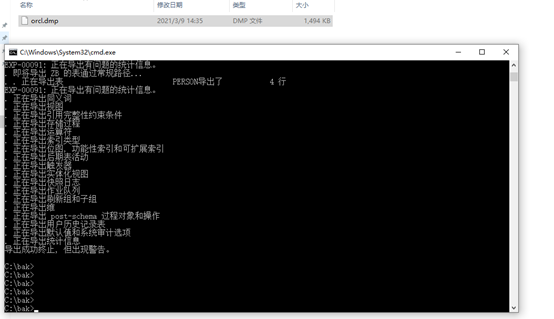
- 数据的导出操作
·首先建立一个文件夹,用于保存所有的导出数据,路径:d:backup;
·通过命令行方式进入到backup目录之中(cd backup);
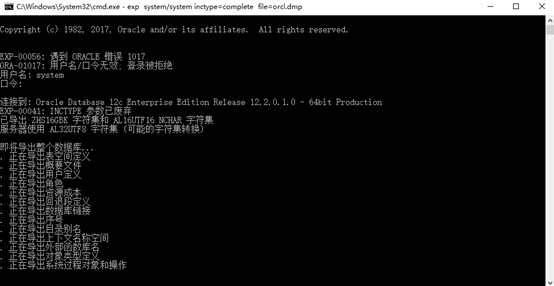
·执行exp指令;
|-输入用户名和密码:scott / tiger;
|-导出文件: EXPDAT.DMP;
exp 用户名/密码@SID file=f:xx.dmp owner=用户名 - 导入数据
进入到备份文件所在的路径;
·执行imp指令导入数据;
但是这样的数据导入只适合小数据量,因为在整个导出过程之中,事务是锁定的,所以很多时候如果非要使用此类方式导出,就需要针对于数据进行分区的概念。
增量导出包括三种类型:
- “完全”增量导出(Complete)
即备份三个数据库,比如:
exp system/system inctype=complete file=040731.dmp - “增量型”增量导出
备份上一次备份后改变的数据,比如:
exp system/system inctype=incremental file=040731.dmp - “累积型”增量导出
累计型导出方式是导出自上次“完全”导出之后数据库中变化了的信息。比如:
exp system/system inctype=cumulative file=040731.dmp
数据库管理员可以排定一个备份日程表,用数据导出的三个不同方式合理高效的完成。
比如数据库的被封任务可以做如下安排:
星期一:完全备份(A)
星期二:增量导出(B)
星期三:增量导出(C)
星期四:增量导出(D)
星期五:累计导出(E)
星期六:增量导出(F)
星期日:增量导出(G)
如果在星期日,数据库遭到意外破坏,数据库管理员可按一下步骤来回复数据库:
第一步:用命令CREATE DATABASE重新生成数据库结构;
第二步:创建一个足够大的附加回滚。
第三步:完全增量导入A:
imp system/system inctype=RESTORE FULL=y FILE=A
第四步:累计增量导入E:
imp system/system inctype=RESTORE FULL=Y FILE=E
第五步:最近增量导入F:
imp system/system inctype=RESTORE FULL=Y FILE=F
数据库设计
所谓的数据库设计范式指的设计高效的方便扩充数据库的准则,但是实际之中也只是作为一个参考。实际的工作之中,对于数据表的设计只有一个原则:“根据业务尽可能的减少多表查询”。
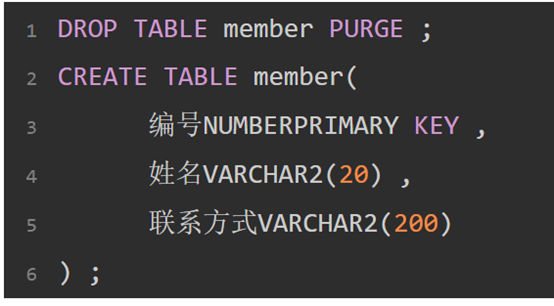
第一范式:
第一范式(单表):
数据表之中的每一个字段都不可再分,简单的理解就是都使用标准数据类型,
错误示例:
正确示例:
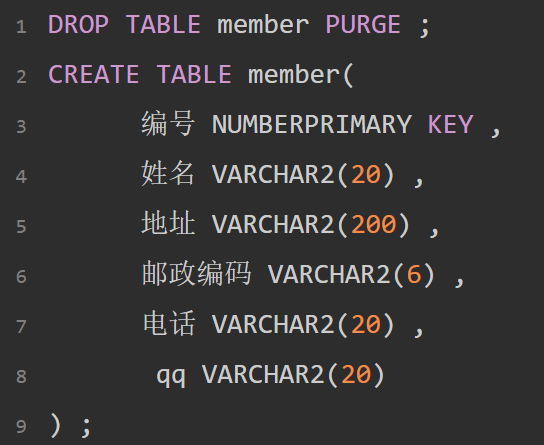
对于第一范式的两点说明:
- 如果系统在中国则名字就表示一个字段,如果在国外,则需要编写firstname、lastname,此不为不可再分的概念范畴;
- 在设计表的时候都使用标准类型(NUMBER、VARCHAR2、CLOB、DATE),所以在表示生日的时候,千万不要将生日拆分为三个字段:生日年(NUMBER(4))、生日月(NUMBER(2))、生日天(NUMBER(2))。
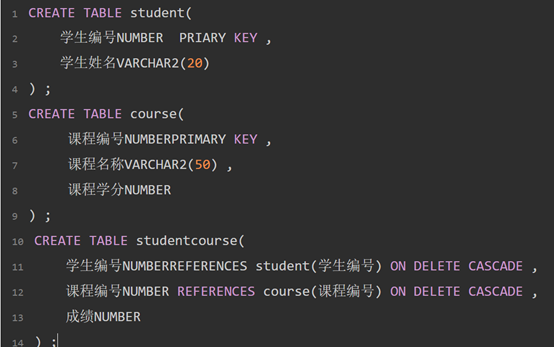
第二范式:
第二范式(多对多):确保表中的每列都和主键相关
数据表之中不存在非关键字段对任意一后选关键字段的部分函数依赖。
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。

第三范式:
第三范式(一对多):确保每列都和主键列直接相关,而不是间接相关
数据表之中不存在非关键字段对任意一后选关键字段的传递函数依赖。
现在要求完成这样的一个设计:一个学校可以多个学生,但是一个学生只能在一个学校。
如果此时使用了第一范式,那么多个学生所在的学校相同,就会导致学校重复;
如果此时使用了第二范式,表示一个学校有多个学生,但同时一个学生可以在多个学校;
与之类似的有一个关系:一个部门有多个雇员。当时是在雇员表之中存放了一个部门编号,那么现在也可以设计两张表,一个是学校表,一个是学生表

数据建模:
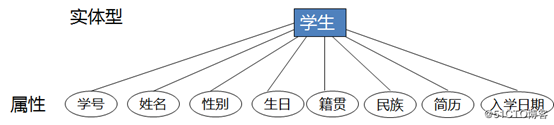
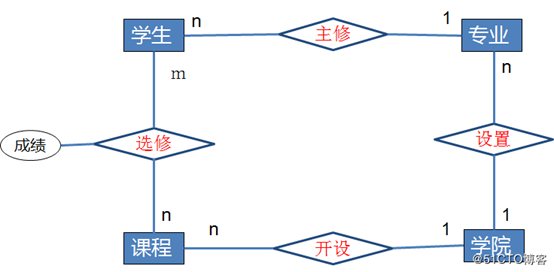
教学管理系统的E-R图
实体:学生、专业、学院、课程
实体表要记录的属性:
学生(学号、姓名、性别、生日、籍贯、民族、简历、入学日期)
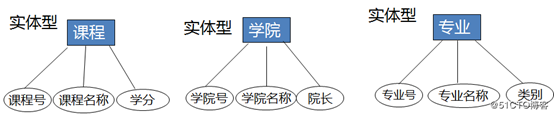
专业(专业号、专业名称、类别)
学院(学院号、学院名称、院长)
课程(课程号、课程名称、学分)
设计工具:
PowerDesigner简介:
PowerDesigner是Sybase公司的CASE工具集,使用它可以方便地对管理信息系统进行分析设计,它几乎包括了数据库模型设计的全过程。利用PowerDesigner可以制作数据流程图、概念数据模型、物理数据模型,可以生成多种客户端开发工具的应用程序,还可为数据仓库制作结构模型,也能对团队设计模型进行控制。它可与许多流行的数据库设计软件,例如:PowerBuilder,Delphi,VB等相配合使用来缩短开发时间和使系统设计更优化。
表结构设计器(EZDML):
这是一个数据库建表的小软件,可快速的进行数据库表结构设计,建立数据模型。类似大家常用的数据库建模工具如PowerDesigner、ERWIN、ER-Studio和Rational-Rose等的超级精简版
包含功能:
- 表结构设计:创建表、字段、主键、外键、索引和注释;
- 表描述:可直接编辑文字描述快速生成表结构,爱用键盘的人会喜欢这个功能;
- 模型图:自动生成模型图;可设计和显示物理/逻辑视图,支持自动布局、平移、缩小放大等操作;
- 导入数据库:导入数据库中的已有对象,即所谓的逆向工程(支持ORACLE、MYSQL、SQLSERVER和ODBC);
- 生成数据库:可生成直接创建数据库的SQL脚本;也可与现有数据库比较,然后生成同步脚本的功能,不至于丢失现有数据;
- 生成代码:目前可生成C++、Pas、C#和Java的简单类定义代码;
- 导出EXCEL。
最后
以上就是闪闪烤鸡最近收集整理的关于Oracle_Day11(存储函数、触发器、包、数据库管理和设计、数据库设计)Oracle_Day11(存储函数、触发器、包、数据库管理和设计、数据库设计)的全部内容,更多相关Oracle_Day11(存储函数、触发器、包、数据库管理和设计、数据库设计)Oracle_Day11(存储函数、触发器、包、数据库管理和设计、数据库设计)内容请搜索靠谱客的其他文章。








发表评论 取消回复