文章目录
- Spring Data JPA
- 1.ORM思想
- 2.hibernate与JPA概述
- 2.1.hibernate介绍
- 2.2.JPA介绍
- 2.3.JPA与hibernate的关系
- 2.4.JPA的优势*
- 3.JPA入门案例
- 3.1.需求
- 3.2.环境搭建
- 3.2.1.maven工程导入坐标
- 3.2.2.配置jpa核心配置文件
- 3.2.3.配置实体类和数据库表的映射关系
- 3.2.4.测试添加客户
- 4.JPA主键生成策略
- 5.JPA的API介绍
- 5.1.Persistence对象
- 5.2.EntityManagerFactory
- 5.3.EntityManager
- 5.4.EntityTransaction
- 6.抽取JPAUtil工具类
- 7.Jpa完成增删改查
- 7.2.查询
- 7.2.删除
- 7.3.更新
- 7.4.复杂查询
- 7.4.1.查询全部
- 7.4.2.排序查询
- 7.4.2.统计总数
- 7.4.3.分页查询
- 7.4.4.条件查询
- 8.Spring Data JPA
- 8.1 Spring Data JPA 与 JPA和hibernate之间的关系
- 9.SpringDataJpa案例入门
- 9.1.搭建环境
- 9.2.整合SpringDataJPA与Spring
- 9.3.编写符合Spring Data JPA规范的Dao层接口
- 9.4.测试接口
- 10.内部原理分析
- 10.1.Spring Data JPA常用接口分析
- 10.2.Spring Data JPA的实现过程
- 10.3.Spring Data JPA完整的调用过程分析
- 11.String Data JPA的查询方式
- 11.1. 使用Spring Data JPA中接口定义的方法进行查询
- 11.2.JPQL查询方式
- 11.3.SQL查询方式
- 11.4.方法名称规则查询
- 12.Specifications动态查询
- 12.1.单条件查询
- 12.2.多条件查询
- 12.3.模糊查询
- 12.4.排序
- 12.5.分页查询
- 12.6.方法对应关系
- 13.多表设计
- 13.1.JPA一对多操作
- 13.1.1.保存
- 13.1.2.删除
- 级联操作
- 13.2.JPA多对多
- 保存
- 删除
- 14.Spring Data JPA的多表查询
- 14.1.对象导航查询
- 14.2.Specification查询
Spring Data JPA
1.ORM思想
ORM(Object-Relational Mapping) 表示对象关系映射。在面向对象的软件开发中,通过ORM,就可以把对象映射到关系型数据库中。只要有一套程序能够做到建立对象与数据库的关联,操作对象就可以直接操作数据库数据,就可以说这套程序实现了ORM对象关系映射
ORM就是建立实体类和数据库表之间的关系,从而达到操作实体类就相当于操作数据库表的目的。
建立映射关系:
- 建立实体类和和表的映射关系
- 实体类中属性和表中字段的映射关系
ORM框架:Mybatis、Hibernate、JPA
2.hibernate与JPA概述
2.1.hibernate介绍
Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个全自动的orm框架,hibernate可以自动生成SQL语句,自动执行,使得Java程序员可以随心所欲的使用对象编程思维来操纵数据库。
2.2.JPA介绍
JPA的全称是Java Persistence API, 即Java 持久化API,是SUN公司推出的一套基于ORM的规范,内部是由一系列的接口和抽象类构成。
JPA通过JDK 5.0注解描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中。
2.3.JPA与hibernate的关系
JPA规范本质上就是一种ORM规范,注意不是ORM框架——因为JPA并未提供ORM实现,它只是制订了一些规范,提供了一些编程的API接口,但具体实现则由服务厂商来提供实现。
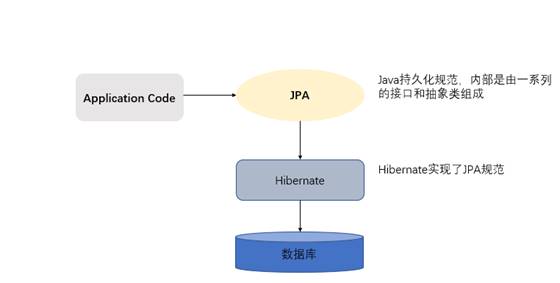
JPA和Hibernate的关系就像JDBC和JDBC驱动的关系,JPA是规范,Hibernate除了作为ORM框架之外,它也是一种JPA实现。JPA怎么取代Hibernate呢?JDBC规范可以驱动底层数据库吗?答案是否定的,也就是说,如果使用JPA规范进行数据库操作,底层需要hibernate作为其实现类完成数据持久化工作。
2.4.JPA的优势*
1. 标准化
JPA 是 JCP 组织发布的 Java EE 标准之一,因此任何声称符合 JPA 标准的框架都遵循同样的架构,提供相同的访问API,这保证了基于JPA开发的企业应用能够经过少量的修改就能够在不同的JPA框架下运行。
2. 容器级特性的支持
JPA框架中支持大数据集、事务、并发等容器级事务,这使得 JPA 超越了简单持久化框架的局限,在企业应用发挥更大的作用。
3. 简单方便
JPA的主要目标之一就是提供更加简单的编程模型:在JPA框架下创建实体和创建Java 类一样简单,没有任何的约束和限制,只需要使用 javax.persistence.Entity进行注释,JPA的框架和接口也都非常简单,没有太多特别的规则和设计模式的要求,开发者可以很容易的掌握。JPA基于非侵入式原则设计,因此可以很容易的和其它框架或者容器集成
4. 查询能力
JPA的查询语言是面向对象而非面向数据库的,它以面向对象的自然语法构造查询语句,可以看成是Hibernate HQL的等价物。JPA定义了独特的JPQL(Java Persistence Query Language),JPQL是EJB QL的一种扩展,它是针对实体的一种查询语言,操作对象是实体,而不是关系数据库的表,而且能够支持批量更新和修改、JOIN、GROUP BY、HAVING 等通常只有 SQL 才能够提供的高级查询特性,甚至还能够支持子查询。
5. 高级特性
JPA 中能够支持面向对象的高级特性,如类之间的继承、多态和类之间的复杂关系,这样的支持能够让开发者最大限度的使用面向对象的模型设计企业应用,而不需要自行处理这些特性在关系数据库的持久化。
3.JPA入门案例
3.1.需求
案例:客户的相关操作(增删改查)
3.2.环境搭建
- 创建maven工程,导入坐标
- 配置JPA的核心配置文件
- 编写客户实体类
- 配置实体类和表,类中属性和表中字段的映射关系
- 保存客户到数据库中
3.2.1.maven工程导入坐标
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.hibernate.version>5.0.7.Final</project.hibernate.version>
</properties>
<dependencies>
<!-- junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- hibernate对jpa的支持包 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>${project.hibernate.version}</version>
</dependency>
<!-- c3p0 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-c3p0</artifactId>
<version>${project.hibernate.version}</version>
</dependency>
<!-- log日志 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- Mysql and MariaDB -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
</dependencies>
3.2.2.配置jpa核心配置文件
位置:配置到类路径下一个叫做META-INF的文件下
命名:persistence.xml
<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns="http://java.sun.com/xml/ns/persistence" version="2.0">
<!--需要配置persitence-unit节点
持久化单元:
name:持久化单元名称
transaction-typ:事务管理的方式
JTA:分布式事务管理 不同的表存放在不同的数据库中
RESOURCE_LOCAL:本地事务管理 所有表存放在一数据库中
-->
<persistence-unit name="myJpa" transaction-type="RESOURCE_LOCAL">
<!--jpa的实现方式-->
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
<!--数据库信息
用户名:javax.persistence.jdbc.username
密码 javax.persistence.jdbc.password
驱动 javax.persistence.jdbc.driver
数据库地址 javax.persistence.jdbc.url
-->
<properties>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql:///jpa_test"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="javax.persistence.jdbc.password" value=""/>
<!--可选配置:配置jpa实现方的配置信息
显示sql: hibernate.show_sql 是否显示 false|true
自动创建数据库表 hibernate.hbm2ddl.auto
create :程序运行时创建数据库 (如果有表,先删除表再创建)
update :程序运行时创建表(如果有表不会创建表)
none :不会创建表
-->
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.format_sql" value="true" />
<property name="hibernate.hbm2ddl.auto" value="create" />
</properties>
</persistence-unit>
</persistence>
3.2.3.配置实体类和数据库表的映射关系
package com.composer.domain;
import javax.persistence.*;
/**
* 客户实体表
*
* 1.实体类和表的映射关系
* @Entity::声明实体类
* @Table:配置实体类和表的映射关系
* name:配置数据库表的名称
*
* 2.实体类属性和表的字段映射关系
*
*/
@Entity
@Table(name = "cst_customer")
public class Customer {
/**
* @Id :声明主键
* @GeneratedValue :配置主键的生成策略
* GenerationType.IDENTITY :自增 mysql (支持自增)
* *底层数据库必须自动增长(底层数据库支持的自动增长方式,对id自增)
* GenerationType.SEQUENCE :序列 oracle(不支持自增,只支持序列)
* * 底层数据库必须支持序列
* GenerationType.TABLE: jpa提供的一种机制,通过一张数据表的形式帮助完成主键自增
* GenerationType.AUTO :由程序自动的帮助选择主键生成策略
* @column: 配置属性和字段的映射关系
*/
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "cust_id")
private Long custId;
@Column(name = "cust_name")
private String custName;
@Column(name = "cust_source")
private String custSource;
@Column(name = "cust_level")
private String custLevel;
@Column(name = "cust_industry")
private String custIndustry;
@Column(name = "cust_phone")
private String custPhone;
@Column(name = "cust_address")
private String custAddress;
//get.set toString 方法略
}
3.2.4.测试添加客户
jpa 操作步骤
1.加载配置文件 创建工厂(实体管理器 工厂)对象
- Persistence: 静态方法(根据持久化单元名称创建实体管理器工厂)
createEntityManagerFactory(持久化单元名称)
作用:创建实体管理器工厂
2.通过实体管理类工厂获取实体管理器
EntityManagerFactory :获取EntityManager对象
方法:createEntityManager
* 内部维护的很多的内容
内部维护了数据库信息,
维护了缓存信息
维护了所有的实体管理器对象
再创建EntityManagerFactory的过程中会根据配置创建数据库表
* EntityManagerFactory的创建过程比较浪费资源
特点:线程安全的对象
多个线程访问同一个EntityManagerFactory不会有线程安全问题
* 如何解决EntityManagerFactory的创建过程浪费资源(耗时)的问题?
思路:创建一个公共的EntityManagerFactory的对象
* 静态代码块的形式创建EntityManagerFactory
3.获取事务对象,开启事务
EntityManager对象:实体类管理器
beginTransaction: 创建事务对象
presist : 保存
merge: 更新
remove: 删除
find/getRefrence: 根据id查询
Transaction:对象:事务
begin:开始
commit:提交
rollback : 回滚
4.完成增删改查操作
5.提交事务(回滚事务)
6.释放资源
@Test
public void testSave(){
//1.加载配置文件 创建工厂(实体管理器 工厂)对象
EntityManagerFactory factory = Persistence.createEntityManagerFactory("myJpa");
//2.通过实体管理类工厂获取实体管理器
EntityManager em = factory.createEntityManager();
//3.获取事务对象,开启事务
EntityTransaction tx = em.getTransaction();
tx.begin();
//4.完成增删改查操作
Customer customer = new Customer();
customer.setCustName("小圆");
customer.setCustIndustry("IT");
//保存
em.persist(customer);
//5.提交事务(回滚事务)
tx.commit();
//释放资源
em.close();
factory.close();
}
4.JPA主键生成策略
通过annotation(注解)来映射hibernate实体的,基于annotation的hibernate主键标识为@Id, 其生成规则由@GeneratedValue设定的.这里的@id和@GeneratedValue都是JPA的标准用法。
JPA提供的四种标准用法为TABLE,SEQUENCE,IDENTITY,AUTO。
**IDENTITY:主键由数据库自动生成(主要是自动增长型)**mysql
用法:
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long custId;
SEQUENCE:根据底层数据库的序列来生成主键,条件是数据库支持序列。
用法:
@Id
@GeneratedValue(strategy =GenerationType.SEQUENCE,generator="payablemoney_seq")
@SequenceGenerator(name="payablemoney_seq", sequenceName="seq_payment")
private Long custId;
@SequenceGenerator源码中的定义
@Target({TYPE, METHOD, FIELD})
@Retention(RUNTIME)
public @interface SequenceGenerator {
//表示该表主键生成策略的名称,它被引用在@GeneratedValue中设置的“generator”值中
String name();
//属性表示生成策略用到的数据库序列名称。
String sequenceName() default "";
//表示主键初识值,默认为0
int initialValue() default 0;
//表示每次主键值增加的大小,例如设置1,则表示每次插入新记录后自动加1,默认为50
int allocationSize() default 50;
}
AUTO:主键由程序控制
用法:
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long custId;
TABLE:使用一个特定的数据库表格来保存主键
用法:
genertor="" 表示主键生成器的名称
@Id
@GeneratedValue(strategy = GenerationType.TABLE, generator="payablemoney_gen")
@TableGenerator(name = "pk_gen",
table="tb_generator",
pkColumnName="gen_name",
valueColumnName="gen_value",
pkColumnValue="PAYABLEMOENY_PK",
allocationSize=1
)
private Long custId;
//@TableGenerator的定义:
@Target({TYPE, METHOD, FIELD})
@Retention(RUNTIME)
public @interface TableGenerator {
//表示该表主键生成策略的名称,它被引用在@GeneratedValue中设置的“generator”值中
String name();
//表示表生成策略所持久化的表名,例如,这里表使用的是数据库中的“tb_generator”。
String table() default "";
//catalog和schema具体指定表所在的目录名或是数据库名
String catalog() default "";
String schema() default "";
//属性的值表示在持久化表中,该主键生成策略所对应键值的名称。例如在“tb_generator”中将“gen_name”作为主键的键值
String pkColumnName() default "";
//属性的值表示在持久化表中,该主键当前所生成的值,它的值将会随着每次创建累加。例如,在“tb_generator”中将“gen_value”作为主键的值
String valueColumnName() default "";
//属性的值表示在持久化表中,该生成策略所对应的主键。例如在“tb_generator”表中,将“gen_name”的值为“CUSTOMER_PK”。
String pkColumnValue() default "";
//表示主键初识值,默认为0。
int initialValue() default 0;
//表示每次主键值增加的大小,例如设置成1,则表示每次创建新记录后自动加1,默认为50。
int allocationSize() default 50;
UniqueConstraint[] uniqueConstraints() default {};
}
//这里应用表tb_generator,定义为 :
CREATE TABLE tb_generator (
id NUMBER NOT NULL,
gen_name VARCHAR2(255) NOT NULL,
gen_value NUMBER NOT NULL,
PRIMARY KEY(id)
)
5.JPA的API介绍
5.1.Persistence对象
Persistence对象主要作用是用于获取EntityManagerFactory对象的 。通过调用该类的createEntityManagerFactory静态方法,根据配置文件中持久化单元名称创建EntityManagerFactory。
@Test
String unitName = "myJpa";
EntityManagerFactory factory= Persistence.*createEntityManagerFactory(unitName);
5.2.EntityManagerFactory
EntityManagerFactory 接口主要用来创建 EntityManager 实例
EntityManager em = factory.createEntityManager();
由于EntityManagerFactory 是一个线程安全的对象(即多个线程访问同一个EntityManagerFactory 对象不会有线程安全问题),并且EntityManagerFactory 的创建极其浪费资源,所以在使用JPA编程时,我们可以对EntityManagerFactory 的创建进行优化,只需要做到一个工程只存在一个EntityManagerFactory 即可
5.3.EntityManager
EntityManager是完成持久化操作的核心对象,实体类作为普通 java对象,只有在调用 EntityManager将其持久化后才会变成持久化对象。EntityManager对象在一组实体类与底层数据源之间进行 O/R 映射的管理。它可以用来管理和更新 Entity Bean, 根椐主键查找 Entity Bean, 还可以通过JPQL语句查询实体。
通过调用EntityManager的方法完成获取事务,以及持久化数据库的操作
- getTransaction : 获取事务对象
- persist : 保存操作
- merge : 更新操作
- remove : 删除操作
- find/getReference : 根据id查询
5.4.EntityTransaction
EntityTransaction是完成事务操作的核心对象,对于EntityTransaction在我们的java代码中承接的功能比较简单
- begin:开启事务
- commit:提交事务
- rollback:回滚事务
6.抽取JPAUtil工具类
/**
* 解决实体管理器工厂的浪费资源和耗时问题
* 通过静态代码块的形式,当程序第一次访问此工具时,创建一个公共的实体管理器工厂对象
*
* 第一次访问getEntityManger会创建EntityManagerFactory对象,再调用方法创建一个EntityManger对象
* 第二次访问 通过创建好的factory对象,创建EntityManager对象
*/
public class JpaUtils {
private static EntityManagerFactory factory;
static {
//1.加载配置文件,创建entityManagerFatory
factory = Persistence.createEntityManagerFactory("myJpa");
}
/**
* 获取EntityManager对象
*/
public static EntityManager getEntityManger(){
return factory.createEntityManager();
}
}
7.Jpa完成增删改查
7.2.查询
根据id查询
entityManager.find 立即加载
-
查询的对象就是当前客户对象本身
-
在调用find方法的时候,就会发送sql语句查询数据库
entityManager.getReference 延迟加载(懒加载):得到的是一个动态代理对象
- 获取的对象是一个动态代理对象
- 调用getReference方法不会立即发送sql语句查询数据库
- 当调用查询结果对象的时候,才会发送查询的sql语句:什么时候用,什么时候发送sql语句查询数据库
/**
* 根据id查询
*/
@Test
public void testFind(){
//通过工具类获取EntityManager
EntityManager entityManager = JpaUtils.getEntityManger();
//开启事务
EntityTransaction tx = entityManager.getTransaction();
tx.begin();
//执行CRUD
/**
* find 根据id查询数据
* class : 查询数据的结果需要包装的实体类类型的字节码
* id :查询主键的取值
*/
Customer customer = entityManager.find(Customer.class,4L);
System.out.println(customer.toString());
//提交事务
tx.commit();
//释放资源
entityManager.close();
}
7.2.删除
/**
* 删除客户
*/
@Test
public void testRemove(){
//通过工具类获取EntityManager
EntityManager entityManager = JpaUtils.getEntityManger();
//开启事务
EntityTransaction tx = entityManager.getTransaction();
tx.begin();
//执行CRUD 删除
//根据id查询客户,调用remove方法完成删除操作
Customer customer = entityManager.find(Customer.class,4L);
//调用remove方法完成删除操作
entityManager.remove(customer);
//提交事务
tx.commit();
//释放资源
entityManager.close();
}
7.3.更新
/**
* 更新操作 merge(customer)
*/
@Test
public void testUpdate(){
//通过工具类获取EntityManager
EntityManager entityManager = JpaUtils.getEntityManger();
//开启事务
EntityTransaction tx = entityManager.getTransaction();
tx.begin();
//执行CRUD 更新
//根据id查询客户,调用remove方法完成删除操作
//查找客户
Customer customer = entityManager.find(Customer.class,5L);
//更新
customer.setCustIndustry("IT-Java");
entityManager.merge(customer);
//提交事务
tx.commit();
//释放资源
entityManager.close();
}
7.4.复杂查询
JPQL全称Java Persistence Query Language
其特征与原生SQL语句类似,并且完全面向对象,通过类名和属性访问,而不是表名和表的属性。
- sql:查询的是表和表中表中的字段
- jpql:查询的是实体类和类中的属性
- *jpql和sql语句的语法相似
jpql执行查询步骤
- 根据jpql语句创建Query查询对象
- 对参数赋值
- 发送查询,并且封装结果
7.4.1.查询全部
/**
* 查询全部
* jpql; from com.composer.domain.customer
* sql : select * from cst_customer
*/
@Test
public void testFindAll(){
//获取entityManaer对象
EntityManager manager = JpaUtils.getEntityManger();
//开启事务
EntityTransaction tx = manager.getTransaction();
tx.begin();
//执行操作
String jpql = "from com.composer.domain.Customer"; //from Customer
Query query = manager.createQuery(jpql); //创建Query查询对象,query对象才是执行jpql的对象
//发送查询,并且封装结果集
List list = query.getResultList();
for (Object o : list){
System.out.println(o);
}
//提交事务
tx.commit();
//释放资源
manager.close();
}
7.4.2.排序查询
/**
* 排序查询: 倒序查询全部客户(根据id倒序)
* sql: select * from cst_customer ORDER BY cust_id DESC
* jpql: from Customer order by custId desc
*/
@Test
public void testFindAllDesc(){
//获取entityManaer对象
EntityManager manager = JpaUtils.getEntityManger();
//开启事务
EntityTransaction tx = manager.getTransaction();
tx.begin();
//执行操作
String jpql = "from Customer order by custId desc";
Query query = manager.createQuery(jpql); //创建Query查询对象,query对象才是执行jpql的对象
//发送查询,并且封装结果集
List list = query.getResultList();
for (Object o : list){
System.out.println(o);
}
//提交事务
tx.commit();
//释放资源
manager.close();
}
7.4.2.统计总数
/**
* 查询总数
* sql:select count(*) from cst_customer
* jpql: select count(custId) from Customer
*/
@Test
public void testCount(){
//获取entityManaer对象
EntityManager manager = JpaUtils.getEntityManger();
//开启事务
EntityTransaction tx = manager.getTransaction();
tx.begin();
//执行操作
String jpql = "select count(custId) from Customer";
Query query = manager.createQuery(jpql); //创建Query查询对象,query对象才是执行jpql的对象
//发送查询,并且封装结果集
Object count = query.getSingleResult();
System.out.println(count);
7.4.3.分页查询
/**
* 分页查询
* sql:select * from cst_customer limit 0,2
* jpql: from Customer
*/
@Test
public void testPage(){
//获取entityManaer对象
EntityManager manager = JpaUtils.getEntityManger();
//开启事务
EntityTransaction tx = manager.getTransaction();
tx.begin();
//执行操作
String jpql = " from Customer";
Query query = manager.createQuery(jpql); //创建Query查询对象,query对象才是执行jpql的对象
//对参数赋值 --分页参数
//起始索引
query.setFirstResult(0);
//每页查询的条数
query.setMaxResults(2);
//发送查询,并且封装结果集
List list = query.getResultList();
for (Object o : list ){
System.out.println(o);
}
7.4.4.条件查询
/**
* 条件查询
* 查询客户名称以 小开头的
* sql:select * from cst_customer where cust_name like ?
* jpql: from Customer where custName like ?
*/
@Test
public void testConditon(){
//获取entityManaer对象
EntityManager manager = JpaUtils.getEntityManger();
//开启事务
EntityTransaction tx = manager.getTransaction();
tx.begin();
//执行操作
String jpql = " from Customer where custName like ?";
Query query = manager.createQuery(jpql); //创建Query查询对象,query对象才是执行jpql的对象
//对参数赋值 --条件查询
// 第一参数 占位符 索引位置(从1开始) 第二个参数:取值
query.setParameter(1,"小%");
//发送查询,并且封装结果集
List list = query.getResultList();
for (Object o : list ){
System.out.println(o);
}
8.Spring Data JPA
8.1 Spring Data JPA 与 JPA和hibernate之间的关系
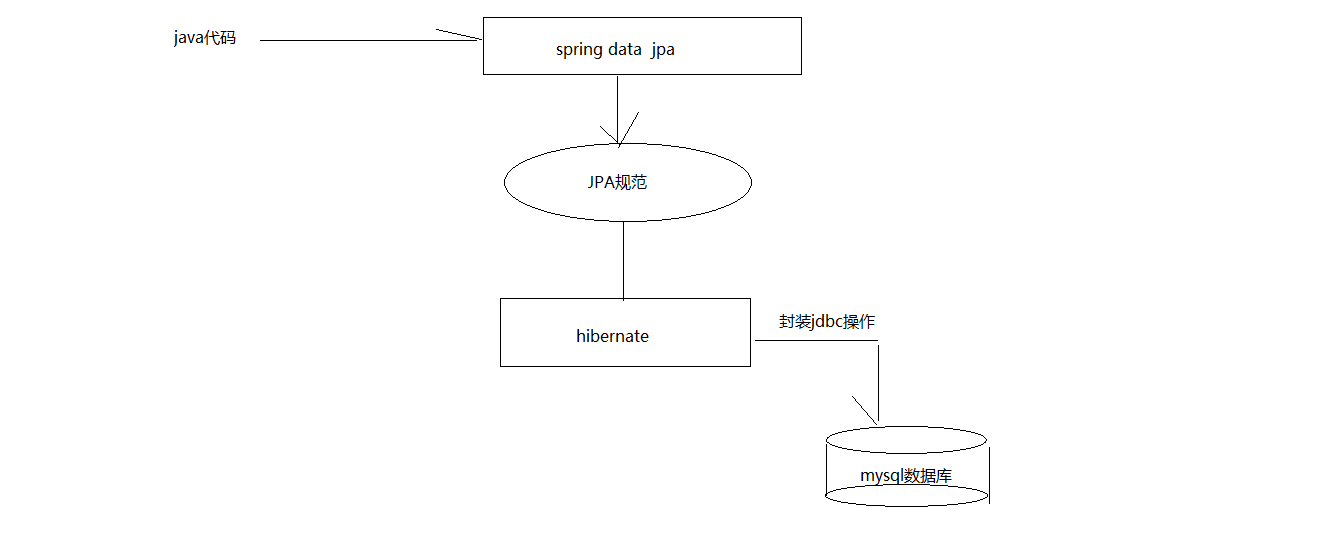
JPA是一套规范,内部是有接口和抽象类组成的。hibernate是一套成熟的ORM框架,而且Hibernate实现了JPA规范,所以也可以称hibernate为JPA的一种实现方式,我们使用JPA的API编程,意味着站在更高的角度上看待问题(面向接口编程)
Spring Data JPA是Spring提供的一套对JPA操作更加高级的封装,是在JPA规范下的专门用来进行数据持久化的解决方案。
9.SpringDataJpa案例入门
9.1.搭建环境
- 创建工程导入坐标
- 配置spring的配置文件
- 编写实体类,使用jpa注解配置映射关系
编写一个符合springDataJpa的dao层接口
Maven 坐标
<properties>
<spring.version>5.0.2.RELEASE</spring.version>
<hibernate.version>5.0.7.Final</hibernate.version>
<slf4j.version>1.6.6</slf4j.version>
<log4j.version>1.2.12</log4j.version>
<c3p0.version>0.9.1.2</c3p0.version>
<mysql.version>5.1.6</mysql.version>
</properties>
<dependencies>
<!-- junit单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.9</version>
<scope>test</scope>
</dependency>
<!-- spring beg -->
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
<version>1.6.8</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aop</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>${spring.version}</version>
</dependency>
<!-- spring end -->
<!-- hibernate beg -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>${hibernate.version}</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>${hibernate.version}</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
<version>5.2.1.Final</version>
</dependency>
<!-- hibernate end -->
<!-- c3p0 beg -->
<dependency>
<groupId>c3p0</groupId>
<artifactId>c3p0</artifactId>
<version>${c3p0.version}</version>
</dependency>
<!-- c3p0 end -->
<!-- log end -->
<dependency
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<!-- log end -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
<version>1.9.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>4.2.4.RELEASE</version>
</dependency>
<!-- el beg 使用spring data jpa 必须引入 -->
<dependency>
<groupId>javax.el</groupId>
<artifactId>javax.el-api</artifactId>
<version>2.2.4</version>
</dependency>
<dependency>
<groupId>org.glassfish.web</groupId>
<artifactId>javax.el</artifactId>
<version>2.2.4</version>
</dependency>
<!-- el end -->
</dependencies>
9.2.整合SpringDataJPA与Spring
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:jdbc="http://www.springframework.org/schema/jdbc" xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:jpa="http://www.springframework.org/schema/data/jpa" xmlns:task="http://www.springframework.org/schema/task"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/jdbc http://www.springframework.org/schema/jdbc/spring-jdbc.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd
http://www.springframework.org/schema/data/jpa
http://www.springframework.org/schema/data/jpa/spring-jpa.xsd">
<!--spring 和 spring Data Jpa 配置-->
<!--1.创建entityManagerFactory交给spring容器管理-->
<bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="dataSource" ref="dataSource" />
<!--配置扫描包下所有实体类-->
<property name="packagesToScan" value="com.composer.domain" />
<!--jpa的实现方-->
<property name="persistenceProvider" >
<bean class="org.hibernate.jpa.HibernatePersistenceProvider" />
</property>
<!--jpa的供应商适配器-->
<property name="jpaVendorAdapter">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter">
<!--配置是否自动创建数据库表-->
<property name="generateDdl" value="false" />
<!--指定数据库类型-->
<property name="database" value="MYSQL" />
<!--数据库方言,支持特有语法-->
<property name="databasePlatform" value="org.hibernate.dialect.MySQLDialect" />
<!--是否显示sql语句-->
<property name="showSql" value="true" />
</bean>
</property>
<!--jpa的方言,高级特性-->
<property name="jpaDialect">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaDialect"/>
</property>
</bean>
<!--2.创建数据库连接池-->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="user" value="root"/>
<property name="password" value=""/>
<property name="jdbcUrl" value="jdbc:mysql:///jpa_test?useUnicode=true&characterEncoding=UTF8"/>
<property name="driverClass" value="com.mysql.jdbc.Driver"/>
</bean>
<!--3.整合spring dataJpa-->
<jpa:repositories base-package="com.composer.dao" transaction-manager-ref="transactionManager" entity-manager-factory-ref="entityManagerFactory"></jpa:repositories>
<!--配置事务管理器-->
<bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager">
<property name="entityManagerFactory" ref="entityManagerFactory"></property>
</bean>
<!--4.声明式事务-->
<!-- 4.txAdvice-->
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="save*" propagation="REQUIRED"/>
<tx:method name="insert*" propagation="REQUIRED"/>
<tx:method name="update*" propagation="REQUIRED"/>
<tx:method name="delete*" propagation="REQUIRED"/>
<tx:method name="get*" read-only="true"/>
<tx:method name="find*" read-only="true"/>
<tx:method name="*" propagation="REQUIRED"/>
</tx:attributes>
</tx:advice>
<!-- 6.aop-->
<aop:config>
<aop:pointcut id="pointcut" expression="execution(* com.composer.service.*.*(..))" />
<aop:advisor advice-ref="txAdvice" pointcut-ref="pointcut" />
</aop:config>
<!--7.配置包扫描-->
<context:component-scan base-package="com.composer"></context:component-scan>
</beans>
9.3.编写符合Spring Data JPA规范的Dao层接口
/**
* 符合SpringDataJpa的dao层接口规范
* JpaRepository<操作的实体类类型,实体类中对应的主键类型>
* *封装了基本的CRUD操作
* JpaSpecificationExecutor<操作的实体类类型>
* *封装了复杂查询 (分页)
*/
public interface CustomerDao extends JpaRepository<Customer,Long>, JpaSpecificationExecutor<Customer> {
}
9.4.测试接口
@RunWith(SpringJUnit4ClassRunner.class) //声明spring提供的单元测试环境
@ContextConfiguration(locations = "classpath:applicationContext.xml") //指定spring容器的配置信息
public class CustomerDaoTest {
@Autowired
private CustomerDao customerDao;
@Test
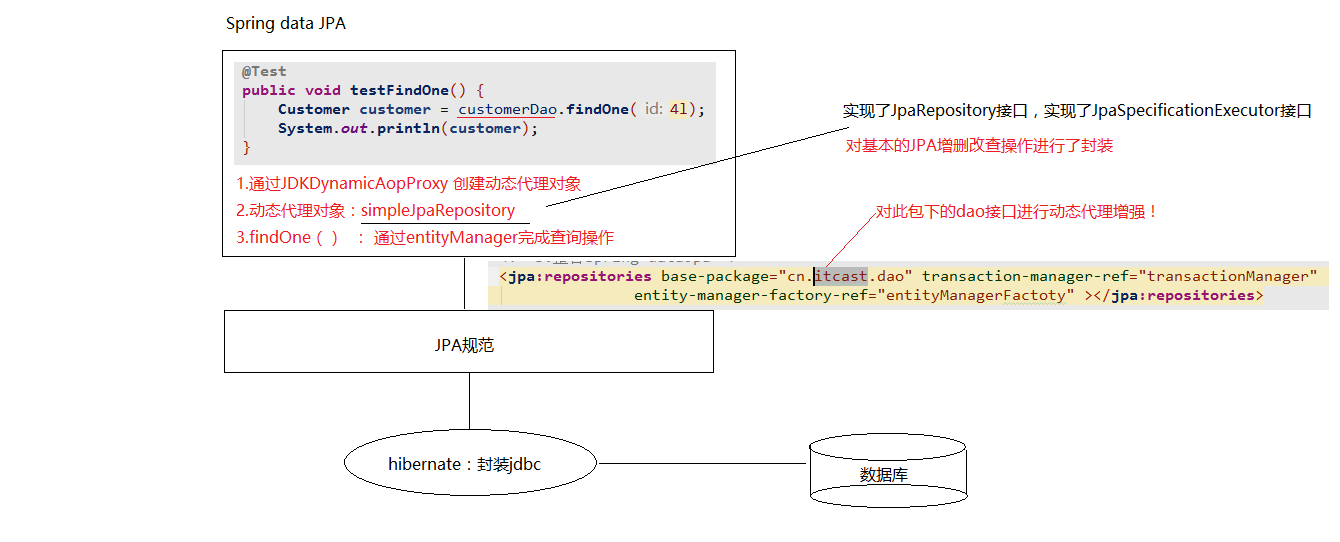
public void testFindOne(){
Customer customer = customerDao.findOne(5L);
System.out.println(customer);
}
/**
* save 保存或者更新
* 根据传递的是对象是否存在主键id,如果没有id主键属性,保存
* 否则 更新
*/
@Test
public void testSave(){
Customer customer = new Customer();
customer.setCustName("小白白");
customer.setCustAddress("安阳");
customerDao.save(customer);
}
@Test
public void testUpdate(){
Customer customer = new Customer();
customer.setCustId(8L);
customer.setCustName("小白白");
customerDao.save(customer);
}
@Test
public void testDel(){
customerDao.delete(8L);
}
@Test
public void testFindAll(){
List<Customer> list = customerDao.findAll();
for (Customer c : list){
System.out.println(c);
}
}
}
10.内部原理分析
10.1.Spring Data JPA常用接口分析
在客户的案例中,我们发现在自定义的CustomerDao中,并没有提供任何方法就可以使用其中的很多方法,那么这些方法究竟是怎么来的呢?答案很简单,对于我们自定义的Dao接口,由于继承了JpaRepository和JpaSpecificationExecutor,所以我们可以使用这两个接口的所有方法。
10.2.Spring Data JPA的实现过程
通过对客户案例,以debug断点调试的方式,通过分析Spring Data JPA的原来来分析程序的执行过程
以findOne方法为例进行分析
- l 代理子类的实现过程
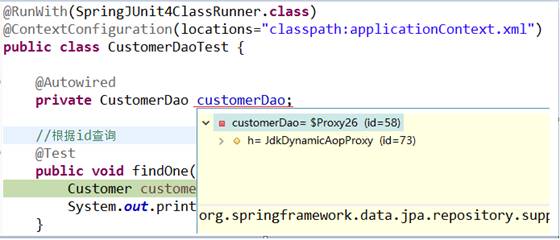
断点执行到方法上时,我们可以发现注入的customerDao对象,本质上是通过JdkDynamicAopProxy生成的一个代理对象
- l 代理对象中方法调用的分析
当程序执行的时候,会通过JdkDynamicAopProxy的invoke方法,对customerDao对象生成动态代理对象。根据对Spring Data JPA介绍而知,要想进行findOne查询方法,最终还是会出现JPA规范的API完成操作,那么这些底层代码存在于何处呢?答案很简单,都隐藏在通过JdkDynamicAopProxy生成的动态代理对象当中,而这个动态代理对象就是SimpleJpaRepository
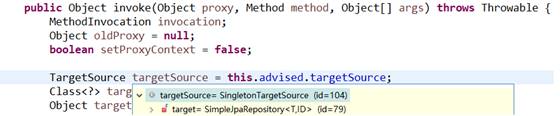
通过SimpleJpaRepository的源码分析,定位到了findOne方法,在此方法中,返回em.find()的返回结果,那么em又是什么呢?

带着问题继续查找em对象,我们发现em就是EntityManager对象,而他是JPA原生的实现方式,所以我们得到结论Spring Data JPA只是对标准JPA操作进行了进一步封装,简化了Dao层代码的开发
10.3.Spring Data JPA完整的调用过程分析
11.String Data JPA的查询方式
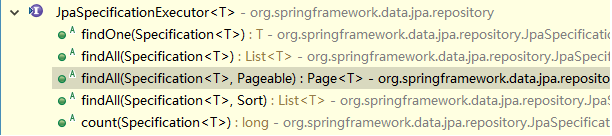
11.1. 使用Spring Data JPA中接口定义的方法进行查询
l 继承JpaRepository后的方法列表

l 继承JpaSpecificationExecutor的方法列表
11.2.JPQL查询方式
使用Spring Data JPA提供的查询方法已经可以解决大部分的应用场景,但是对于某些业务来说,我们还需要灵活的构造查询条件,这时就可以使用@Query注解,结合JPQL的语句方式完成查询
@Query 注解的使用非常简单,只需在方法上面标注该注解,同时提供一个JPQL查询语句即可
/**
* 根据客户名称查询客户
* 使用jpql查询
* jqpl: from Customer where custName = ?
* 配置jpql语句,使用的@Query注解
*/
@Query(value = "from Customer where custName = ?")
public Customer findJpql(String custName);
@Query(value = "from Customer where custName = ?1 and custId = ?2")
public Customer findByCustNameAndCustIdAnd(String custName,Long custId);
更新操作
@Modifying 来将该操作标识为修改查询
/**
* @Query 代表查询
* 需要声明更新操作
* spring Data JPA使用jpql完成
* 需要手动添加事务支持
* 默认会执行结束之后,回滚事务
* @param id
* @param name
*/
@Query(value = "update Customer set custName = ?2 where custId = ?1")
@Modifying
public void update(Long id,String name);
/**
* spring Data JPA使用jpql完成
* 需要手动添加事务支持
* 默认会执行结束之后,回滚事务
**/
@Test
@Transactional
@Rollback(value = false)
public void updateByNameAndId(){
customerDao.update(5L,"小黑黑");
}
11.3.SQL查询方式
/**
* nativeQuery :(true) 使用本地sql的方式查询,sql查询
* (false) 使用jpql查询
*/
@Query(value="select * from cst_customer",nativeQuery=true)
public List<Customer> findSql();
11.4.方法名称规则查询
方法命名规则查询就是根据方法的名字,就能创建查询。只需要按照Spring Data JPA提供的方法命名规则定义方法的名称,就可以完成查询工作。Spring Data JPA在程序执行的时候会根据方法名称进行解析,并自动生成查询语句进行查询
按照Spring Data JPA 定义的规则,查询方法以findBy开头,涉及条件查询时,条件的属性用条件关键字连接,要注意的是:条件属性首字母需大写。框架在进行方法名解析时,会先把方法名多余的前缀截取掉,然后对剩下部分进行解析。
具体的关键字,使用方法和生产成SQL如下表所示
| Keyword | Sample | JPQL |
|---|---|---|
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is,Equals | findByFirstnameIs, findByFirstnameEquals | … where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age ⇐ ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull | findByAgeIsNull | … where x.age is null |
| IsNotNull,NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 (parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1 (parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection age) | … where x.age not in ?1 |
| TRUE | findByActiveTrue() | … where x.active = true |
| FALSE | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstame) = UPPER(?1) |
12.Specifications动态查询
有时我们在查询某个实体的时候,给定的条件是不固定的,这时就需要动态构建相应的查询语句,在Spring Data JPA中可以通过JpaSpecificationExecutor接口查询。相比JPQL,其优势是类型安全,更加的面向对象
/**
* JpaSpecificationExecutor中定义的方法
**/
public interface JpaSpecificationExecutor<T> {
//根据条件查询一个对象
T findOne(Specification<T> spec);
//根据条件查询集合
List<T> findAll(Specification<T> spec);
//根据条件分页查询
//查询全部,分页
//pageable:分页参数
//返回值:分页pageBean(page:是springdatajpa提供的)
Page<T> findAll(Specification<T> spec, Pageable pageable);
//排序查询查询
//Sort:排序参数
List<T> findAll(Specification<T> spec, Sort sort);
//统计查询
long count(Specification<T> spec);
}
对于JpaSpecificationExecutor,这个接口基本是围绕着Specification接口来定义的。我们可以简单的理解为,Specification构造的就是查询条件
Specification接口中只定义了如下一个方法:
//构造查询条件
/**
* root :Root接口,代表查询的根对象,可以通过root获取实体中的属性
* query :代表一个顶层查询对象,用来自定义查询
* cb :用来构建查询,此对象里有很多条件方法
**/
public Predicate toPredicate(Root<T> root, CriteriaQuery<?> query, CriteriaBuilder cb);
12.1.单条件查询
@Test
public void testSpec(){
/**
* 自定义查询条件
* 1.实现Specification接口(提供泛型:查询的对象类型)
* 2.实现toPredicate方法(构造查询条件)
* 3.借助方法参数中的两个参数(
* root:获取需要查询的对象属性
* CriteriaBuilder:构造查询条件的,内部封装了很多的查询条件(模糊匹配,精准匹配)
* )
*
* 案例:根据客户名称查询,查询客户名为小圆的客户
* 1.查询方式
* cb对象
* 2.b比较的属性名称
* root对象
*/
Specification<Customer> spec = new Specification<Customer>() {
public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder cb) {
//获取比较的属性
Path<Object> custName = root.get("custName");
//构造查询条件 select * from cst_customer where cust_name = ''
/** 第一个参数:需要比较的属性
* 第二个参数:当前需要比较的取值
*/
Predicate predicate = cb.equal(custName,"小白白"); //进行精准匹配 (比较的属性,比较的属性的取值)
return predicate;
}
};
Customer customer = customerDao.findOne(spec);
System.out.println(customer);
}
12.2.多条件查询
/**
* 多条件查询
* 查询客户名 和客户所属行业查询(IT)
*/
@Test
public void testSpecTwo(){
/**
* root:获取属性
* 客户名
* 所属行业
* cb:构造查询
* 1.构造客户名的精准查询
* 2.构造所属行业的精准匹配查询
* 3.将以上两个查询联系起来
*/
Specification<Customer> spec = new Specification<Customer>() {
public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
Path<Object> custName = root.get("custName");
Path<Object> custIndustry = root.get("custIndustry");
//构造查询
//构造客户名精准查询
Predicate p1 = cb.equal(custName,"小圆");
//构造行业精准查询
Predicate p2 = cb.equal(custIndustry,"IT");
//将多个查询条件组合到一起:组合(满足条件一并且条件二、满足条件一或条件二)
Predicate and = cb.and(p1,p2); //以与的形式拼接多个查询条件
//cb.or();//以或的方式拼接多个查询条件
return and;
}
};
Customer customer = customerDao.findOne(spec);
System.out.println(customer);
}
12.3.模糊查询
/**
* 模糊查询 根据客户名称 以“小”开头的
* equal:直接得到path对象 然后进行比较即可
* gt,lt,le,like 得到path对象,根据path指定比较的参数类型,再去进行比较
* 指定参数类型:path.as(类型的字节码对象)
*/
@Test
public void testLike(){
Specification<Customer> spec = new Specification<Customer>() {
public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder cb) {
//查询实行
Path<Object> custName = root.get("custName");
//查询方式:模糊匹配
Predicate like = cb.like(custName.as(String.class),"小%");
return like;
}
};
List<Customer> customers = customerDao.findAll(spec);
for (Customer customer : customers){
System.out.println(customer);
}
}
12.4.排序
@Test
public void testLikeSort(){
Specification<Customer> spec = new Specification<Customer>() {
public Predicate toPredicate(Root<Customer> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder cb) {
//查询实行
Path<Object> custName = root.get("custName");
//查询方式:模糊匹配
Predicate like = cb.like(custName.as(String.class),"小%");
return like;
}
};
//添加排序,
//创建排序对象 需要调用构造方法实例化sort对象
//第一个参数:排序的顺序(倒序,正序)
// Sort.Direction.DESC:倒序
// Sort.Direction.ASC: 升序
//第二个参数:排序的属性名称
Sort sort = new Sort(Sort.Direction.DESC,"custId");
List<Customer> customers = customerDao.findAll(spec,sort);
for (Customer customer : customers){
System.out.println(customer);
}
}
12.5.分页查询
/**
* 分页查询
* Specification:查询条件
* Pageable:分页参数
* findAll(Specification,Pageable)
* findAll(Pageable) 没有条件的分页
* 返回:Page(springData Jpa封装好的pageBean对象,数据列表,总条数)
*/
@Test
public void testPage(){
Specification<Customer> spec = null;
//PageRequest是pageable的实现类
/**
* 创建PageRequest()对象需要调用构造方法传入两个参数
* 第一个参数:当前查询的页数(从0开始)
* 第二个参数:每页查询的数量
*/
Pageable pageable = new PageRequest(0,2);
//分页查询
Page<Customer> page = customerDao.findAll(spec, pageable);
System.out.println(page.getContent()); //得到数据集合列表
System.out.println(page.getTotalPages()); //得到总页数
System.out.println(page.getTotalElements()); //得到总条数
}
12.6.方法对应关系
| 方法名称 | Sql对应关系 |
|---|---|
| equle | filed = value |
| gt(greaterThan ) | filed > value |
| lt(lessThan ) | filed < value |
| ge(greaterThanOrEqualTo ) | filed >= value |
| le( lessThanOrEqualTo) | filed <= value |
| notEqule | filed != value |
| like | filed like value |
| notLike | filed not like value |
13.多表设计
表关系
-
一对一
-
一对多
一的一方:主表
多的一方:从表
外键:指的是从表中有一列,取值参照主表的主键,这一列就是外键。
-
多对多
中间表:中间表中最少应该由两个字段组成,两个字段作为外键指向两张表的主键,又组成联合主键
公司对员工:一对多关系
实体类中的关系
包含关系:可以通过实体类中的包含关系描述表关系
继承关系
分析步骤
- 明确表关系
- 确定表关系(描述 外键|中间表)
- 编写实体类,在实体类中描述表关系(包含关系)
- 配置映射关系
13.1.JPA一对多操作
案例:
客户:指的是一家公司,我们记为A。
联系人:指的是A公司中的员工。
1.表关系建立

2.确认表关系
主表:客户表
从表:联系人表
在从表上添加外键
3.编写实体类,在实体类中描述表关系
客户:客户的实体类中包含一个联系人的集合
联系人:在联系人的实体类中包含一个客户的对象
4.配置映射关系
使用jpa注解配置一对多映射关系
顾客实体类映射关系配置
/**
* 顾客实体类
* 实体类和表的映射关系
* 类中属性和表中字段的映射关系
*/
@Entity
@Table(name = "cst_customer")
public class Customer {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "cust_id")
private Long custId;
@Column(name = "cust_address")
private String custAddress;
@Column(name = "cust_industry")
private String custIndustry;
@Column(name = "cust_level")
private String custLevel;
@Column(name = "cust_name")
private String custName;
@Column(name = "cust_phone")
private String custPhone;
@Column(name = "cust_source")
private String custSource;
//配置客户和联系人的关系(一对多)
/**
* 注解配置一对多关系
* 1.声明关系
* @oneToMany:配置一对多关系
* targetEntity:对方对象的字节码对象
* 2.配置外键(中间表)
* @JoinColumn:配置外键
* name:外键字段名称
* referencedColumnName:参照主表的主键字段名称
* 在客户实体类上(一的一方)添加了外键配置,对于客户而言,也具备了维护外键的作用
*/
//@OneToMany(targetEntity = LinkMan.class)
//@JoinColumn(name = "lkm_cust_id",referencedColumnName = "cust_id") //双向关系
/**
* 放弃外键维护权
* mappedBy:对方配置关系的属性名称
*/
@OneToMany(mappedBy = "customer")
private Set<LinkMan> linkMans = new HashSet<LinkMan>();
//get、set、toString 方法略
}
联系人实体类映射关系配置
@Entity
@Table(name = "cst_linkman")
public class LinkMan {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "lkm_id")
private Long lkmId; //联系人编号(主键)
@Column(name = "lkm_name")
private String lkmName; //联系人姓名
@Column(name = "lkm_gender")
private String lkmGender; //联系人性别
@Column(name = "lkm_phone")
private String lkmPhone; //联系人办公电话
@Column(name = "lkm_mobile")
private String lkmMobile; //联系人手机
@Column(name = "lkm_email")
private String lkmEmail; //联系人邮箱
@Column(name = "lkm_position")
private String lkmPosition; //联系人职位
@Column(name = "lkm_memo")
private String lkmMemo; //联系人备注
/**
* 联系人到客户的多对一关系
* 使用注解的形式配置多对一关系
* 1.配置表关系
* @ManyToOne(多对一)关系
* targetEntity:对方的实体类字节码
* 2.配置外键(中间表)
* 配置外键的过程,配置到了多的一方,就会在多的一方维护外键
*/
@ManyToOne(targetEntity = Customer.class)
@JoinColumn(name = "lkm_cust_id",referencedColumnName = "cust_id")
private Customer customer;
}
注解说明
@OneToMany:
作用:建立一对多的关系映射
属性:
targetEntityClass:指定多的多方的类的字节码
mappedBy:指定从表实体类中引用主表对象的名称。
cascade:指定要使用的级联操作
fetch:指定是否采用延迟加载
orphanRemoval:是否使用孤儿删除
@ManyToOne
作用:建立多对一的关系
属性:
targetEntityClass:指定一的一方实体类字节码
cascade:指定要使用的级联操作
fetch:指定是否采用延迟加载
optional:关联是否可选。如果设置为false,则必须始终存在非空关系。
@JoinColumn
作用:用于定义主键字段和外键字段的对应关系。
属性:
name:指定外键字段的名称
referencedColumnName:指定引用主表的主键字段名称
unique:是否唯一。默认值不唯一
nullable:是否允许为空。默认值允许。
insertable:是否允许插入。默认值允许。
updatable:是否允许更新。默认值允许。
columnDefinition:列的定义信息。
13.1.1.保存
@Test
@Transactional
@Rollback(value = false)
public void testAdd(){
//创建一个客户 创建一联系人
Customer customer = new Customer();
customer.setCustName("百度");
LinkMan linkMan = new LinkMan();
linkMan.setLkmName("小白");
/**
* 由于客户中配置了 客户到联系人的关系 客户可以对外键进行维护
* 从客户角度上:发送两条insert语句,发送一条更新语句更新数据库(更新外键)
*
*/
//customer.getLinkMans().add(linkMan);
/**
* 由于配置了联系人到客户的关系(多对一)
* 只发送了两条insert语句
*/
linkMan.setCustomer(customer);
customerDao.save(customer);
linkManDao.save(linkMan);
}
13.1.2.删除
删除操作的说明如下:
删除从表数据:可以随时任意删除。
删除主表数据:
- 有从表数据
1、在默认情况下,它会把外键字段置为null,然后删除主表数据。如果在数据库的表 结构上,外键字段有非空约束,默认情况就会报错了。
2、如果配置了放弃维护关联关系的权利,则不能删除(与外键字段是否允许为null,没有关系)因为在删除时,它根本不会去更新从表的外键字段了。
3、如果还想删除,使用级联删除引用0
- 没有从表数据引用:随便删
在实际开发中,级联删除请慎用!(在一对多的情况下)
级联操作
级联操作:指操作一个对象同时操作它的关联对象
- 需要区分操作主体
- 需要在操作主体的实体类上,添加级联属性(需要添加到多表映射关系的注释上)
- cascade(配置级联)
/**
* 放弃外键维护权
* mappedBy:对方配置关系的属性名称
* cascade:配置级联
* CascadeType.ALL 所有
* CascadeType.MERGE 更新
* CascadeType.REMOVE 删除
* CascadeType.PERSIST 保存
*/
@OneToMany(mappedBy = "customer",cascade = CascadeType.REMOVE)
private Set<LinkMan> linkMans = new HashSet<LinkMan>();
级联添加
案例:当保存一个客户的同时保存联系人
/**
* 级联添加:保存一个客户的同时保存客户的所有联系人
* 需要在操作主体的实体上,配置casacde属性
*/
@Test
@Transactional
@Rollback(value = false)
public void testAddCas(){
//创建一个客户 创建一联系人
Customer customer = new Customer();
customer.setCustName("百度");
LinkMan linkMan = new LinkMan();
linkMan.setLkmName("小白");
customer.getLinkMans().add(linkMan);
linkMan.setCustomer(customer);
customerDao.save(customer);
}
级联删除
案例:在删除一个客户的同时,也删除此客户的所有联系人
/**
* 级联删除:删除一个客户的同时保存客户的所有联系人
* 需要在操作主体的实体上,配置casacde属性
*/
@Test
@Transactional
@Rollback(value = false)
public void testDelCas(){
//查询客户
Customer customer = customerDao.findOne(1L);
//删除
customerDao.delete(customer);
}
13.2.JPA多对多
案例
用户和角色 (多对多关系)
分析步骤
-
明确表关系 多对多关系
-
确定表关系(描述 外键|中间表)
中间表
-
编写实体类
用户:包含角色的聚合
@Entity @Table(name = "sys_user") public class User { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "user_id") private Long userId; @Column(name = "user_name") private String userName; @ManyToMany(targetEntity = Role.class) @JoinTable(name = "sys_user_role", //joinColumns: 当前对象在中间表中的外键 joinColumns = {@JoinColumn(name = "sys_user_id",referencedColumnName = "user_id")}, //inverseJoinColumns: 对方对象在中间表的外键 inverseJoinColumns = {@JoinColumn(name = "sys_role_id",referencedColumnName = "role_id")} ) private Set<Role> roles = new HashSet<Role>(); //getsettoString 方法省去 }角色:包含用户的集合
@Entity @Table(name = "sys_role") public class Role { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "role_id") private Long roleId; @Column(name = "role_name") private String roleName; @ManyToMany(mappedBy = "roles") //配置多表关系 对方配置映射属性的值 private Set<User> users = new HashSet<User>(); //getsettoString 方法省去 }保存
/** * 保存一个用户保存一个角色 * 多对多当中,放弃维护权:被动的一方放弃 */ @Test @Transactional @Rollback(false) public void testManyToMany(){ User user = new User(); user.setUserName("小李"); Role role = new Role(); role.setRoleName("java工程司"); //配置用户到角色的关系,可以对中间表中的数据进行维护 user.getRoles().add(role); //配置角色到用户的关系,可以对中间表中的数据进行维护 role.getUsers().add(user); userDao.save(user); //级联保存和一对多相同 roleDao.save(role); }
注意!在多对多(保存)中,如果双向都设置关系,意味着双方都维护中间表,都会往中间表插入数据,中间表的2个字段又作为联合主键,所以报错,主键重复,解决保存失败的问题:只需要在任意一方放弃对中间表的维护权即可,推荐在被动的一方放弃,配置如下:
//放弃对中间表的维护权,解决保存中主键冲突的问题
@ManyToMany(mappedBy="roles")
private Set<User> users = new HashSet<User>(0);
删除
/**
* 删除操作
* 在多对多的删除时,双向级联删除根本不能配置
* 禁用
* 如果配了的话,如果数据之间有相互引用关系,可能会清空所有数据
*/
@Test
@Transactional
@Rollback(false)//设置为不回滚
public void testDelete() {
userDao.delete(1l);
}
14.Spring Data JPA的多表查询
14.1.对象导航查询
查询一个对象的同时,通过此对象查询他的关联对象
对象图导航检索方式是根据已经加载的对象,导航到他的关联对象。它利用类与类之间的关系来检索对象。例如:我们通过ID查询方式查出一个客户,可以调用Customer类中的getLinkMans()方法来获取该客户的所有联系人。对象导航查询的使用要求是:两个对象之间必须存在关联关系。
案例:客户和联系人
查询一个客户,获取该客户下的所有联系人
执行LEFT JOIN 左外连接查询
//could not initialize proxy - no Session
//测试对象导航查询(查询一个对象,通过此对象查询所有的关联对象)
/**
* 对象导航查询
* 默认使用的是延迟加载的形式查询
* 调用get方法不会立即发送查询,而是在使用关联对象的时候才会查询
* 取消延迟加载
* 修改配置,将延迟加载改为立即加载
* fetch:需要配置到多表映射关系的注释上
*/
@Test
@Transactional //解决java代码中 no Session问题
public void testQuery1(){
//查询id为1的客户
Customer customer = customerDao.findOne(1L);
Set<LinkMan> linkmens = customer.getLinkMans();
for (LinkMan o : linkmens){
System.out.println(o);
}
}
我们查询客户时,要不要把联系人查询出来?
分析:如果我们不查的话,在用的时候还要自己写代码,调用方法去查询。如果我们查出来的,不使用时又会白白的浪费了服务器内存。
解决:采用延迟加载的思想。通过配置的方式来设定当我们在需要使用时,发起真正的查询。
/**
* fetch:配置关联对象的加载方式
* EAGER : 立即加载
* LAZY : 延迟加载
*/
@OneToMany(mappedBy = "customer",cascade = CascadeType.ALL,fetch = FetchType.EAGER)
private Set<LinkMan> linkMans = new HashSet<LinkMan>();
对象导航查询时
一方查询多方:默认使用延迟加载
多方查询一方:默认使用立即加载
14.2.Specification查询
/**
* Specification的多表查询
*/
@Test
public void testFind() {
Specification<LinkMan> spec = new Specification<LinkMan>() {
public Predicate toPredicate(Root<LinkMan> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
//Join代表链接查询,通过root对象获取
//创建的过程中,第一个参数为关联对象的属性名称,第二个参数为连接查询的方式(left,inner,right)
//JoinType.LEFT : 左外连接,JoinType.INNER:内连接,JoinType.RIGHT:右外连接
Join<LinkMan, Customer> join = root.join("customer", JoinType.INNER);
return cb.like(join.get("custName").as(String.class),"传智播客1");
}
};
List<LinkMan> list = linkManDao.findAll(spec);
for (LinkMan linkMan : list) {
System.out.println(linkMan);
}
}
最后
以上就是冷傲蜡烛最近收集整理的关于JavaEE进阶——Spring Data JPA笔记Spring Data JPA1.ORM思想2.hibernate与JPA概述3.JPA入门案例4.JPA主键生成策略5.JPA的API介绍6.抽取JPAUtil工具类7.Jpa完成增删改查8.Spring Data JPA9.SpringDataJpa案例入门10.内部原理分析11.String Data JPA的查询方式12.Specifications动态查询13.多表设计14.Spring Data JPA的多表查询的全部内容,更多相关JavaEE进阶——Spring内容请搜索靠谱客的其他文章。








发表评论 取消回复