以下内容也可以观看视频教程: https://space.bilibili.com/431152063
先来看下面的sql语句:
select * from orderinfo limit 1000000, 100目前orderinfo表中的数据大概是1亿行
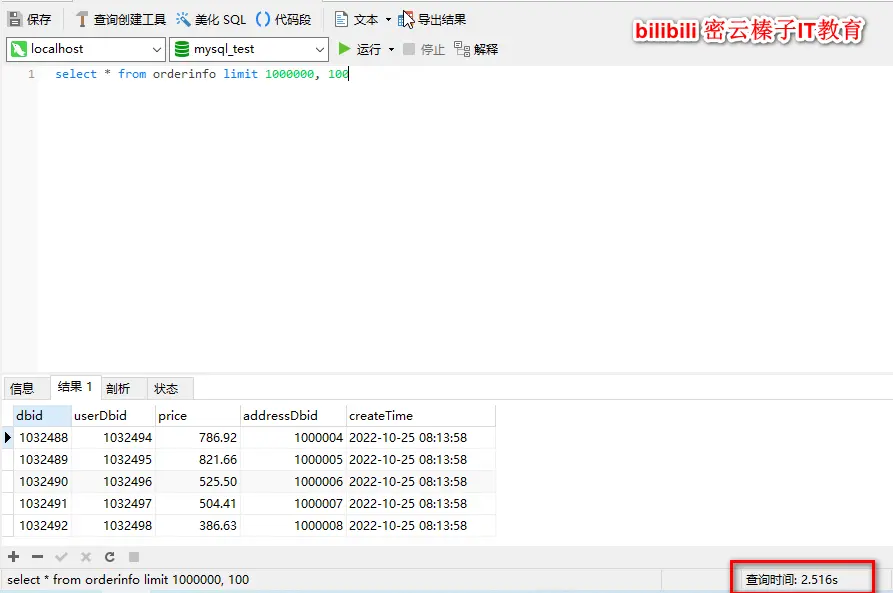
查询耗时大概2秒多,如果将sql中的返回所有字段改成只返回dbid字段(dbid是主键),查询耗时缩短为0.2秒。
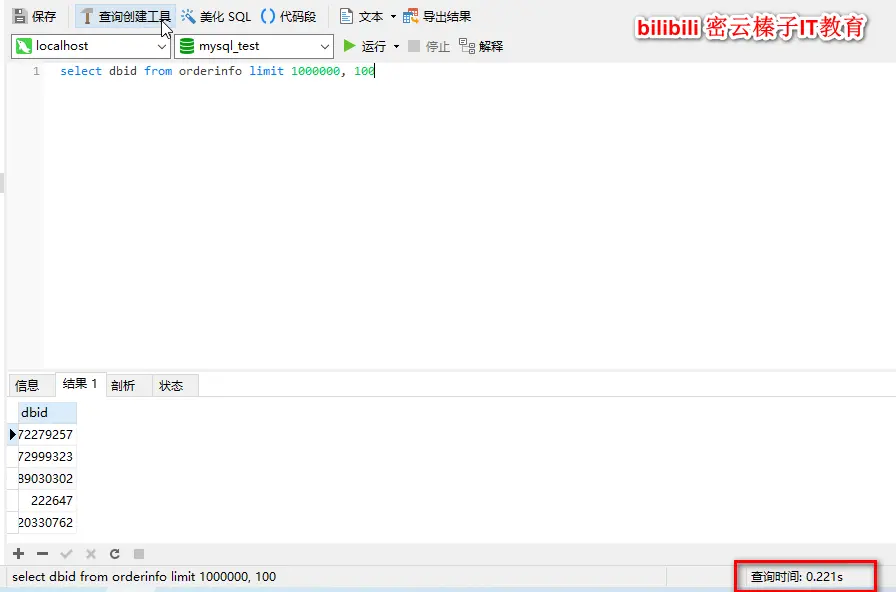
这是因为使用到了覆盖索引。
覆盖索引是指select查询返回的数据列都包含于索引中,这样从索引中就能获取数据,无需读取数据行。比如下面的sql语句:
select addressDbid from orderinfo limit 0, 100addressDbid列已经创建了索引,sql中只需要返回索引列addressDbid,所以用到了覆盖索引。
以下讨论都是基础innodb存储引擎的。
在mysql的innodb存储引擎中,所有的表数据都是存放到索引中的,并且以主键为索引列,这个索引叫聚集索引。聚集索引是mysql自动创建的。
而由我们创建的索引叫二级索引或辅助索引,二级索引中只保存索引列和主键,当select语句中要获取某一行的其他列,必须用主键去聚集索引中获取,这个过程叫“回表”。由于覆盖索引减少了“回表”步骤,所以速度明显提升。
现在回到这个sql语句:
select dbid from orderinfo limit 1000000, 100由于语句只使用到了聚集索引,而表的所有数据也都是存放到聚集索引中的,所以不存在“回表”这种情况,那这个语句速度为什么会快呢?
因为数据库表数据是以文件的形式存放到硬盘上,硬盘的速度相比内存要慢很多,频繁访问会非常耗时,上面的语句由于只需要返回dbid主键(也是聚集索引的索引列),不需要返回其他列,减少了访问硬盘,所以速度要快很多。
但是,平常使用时不会仅仅需要返回一个主键,而是需要这一行的所有列数据,改进一下上面的sql:
select * from orderinfo o
inner join (select dbid from orderinfo limit 10000000, 100) as o2 on o.dbid = o2.dbid 通过dbid连接一下原表orderinfo就可以了。
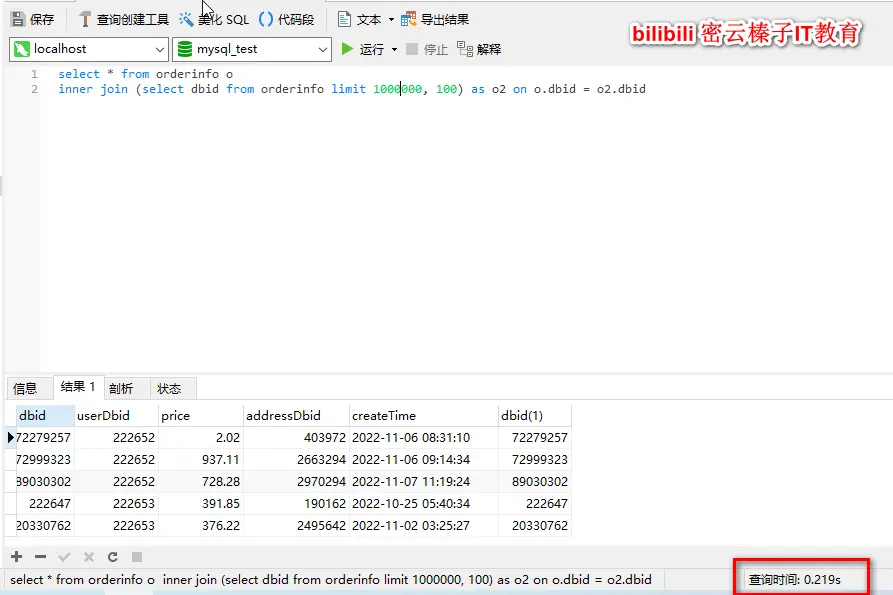
耗时基本没有影响。
最后
以上就是鳗鱼棉花糖最近收集整理的关于MySQL延时关联使查询速度提升N倍的全部内容,更多相关MySQL延时关联使查询速度提升N倍内容请搜索靠谱客的其他文章。








发表评论 取消回复