author: En1y
time:2022-11-19
school:xidian university
第二部分:语法分析器(完整代码在结尾)
测试文本:
origin is (350,400); scale is (10,10); rot is pi; for t from 0 to 2*pi step pi/10000 draw(16*sin(t)*sin(t)*sin(t),13*cos(t)-5*cos(2*t)-2*cos(3*t)-cos(4*t)); --桃心线 origin is (200,200); scale is (100,100); for t from 0 to 2*pi step pi/10000 draw(cos(t)*cos(t)*cos(t),sin(t)*sin(t)*sin(t)); --星型线
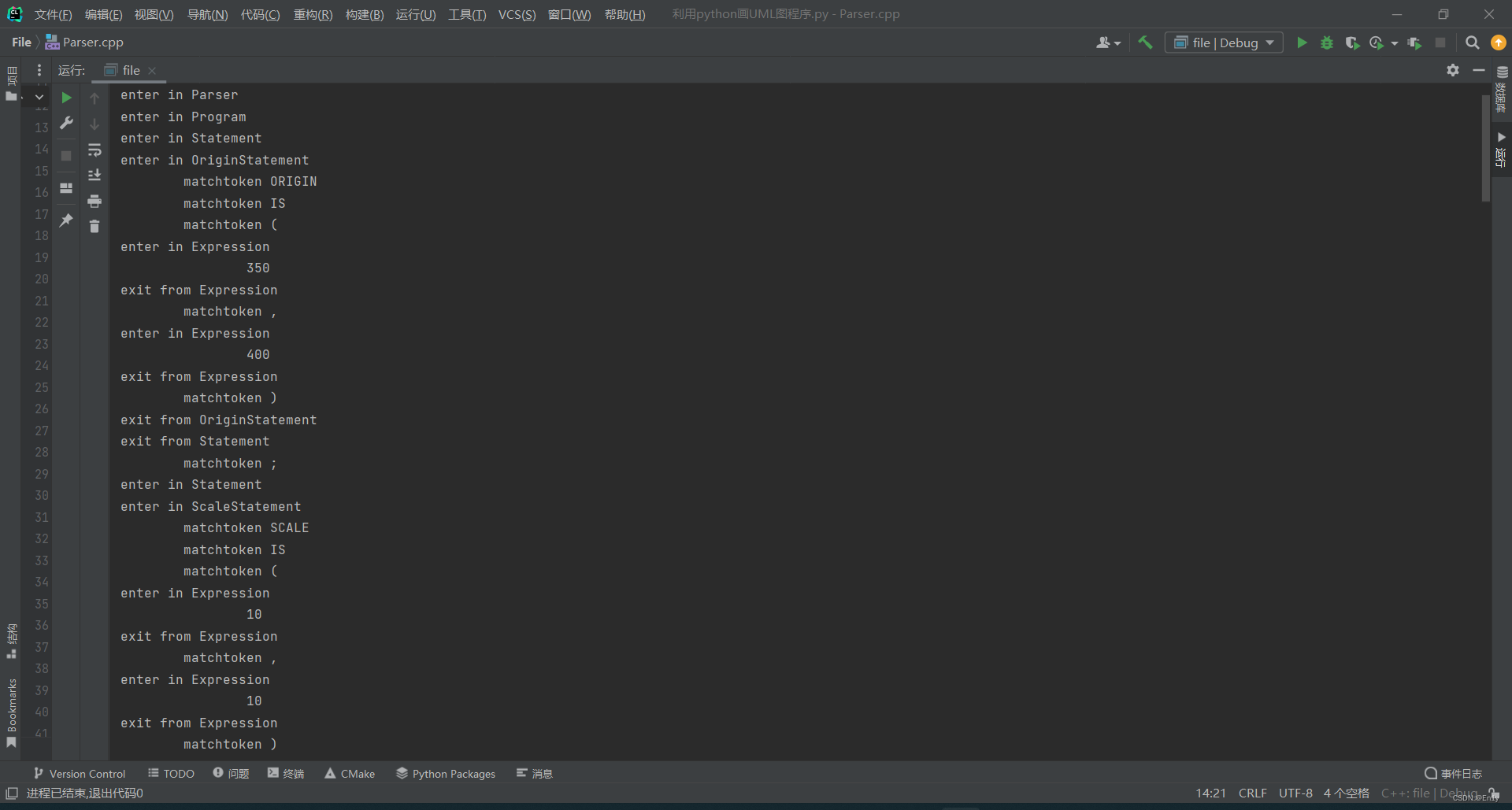
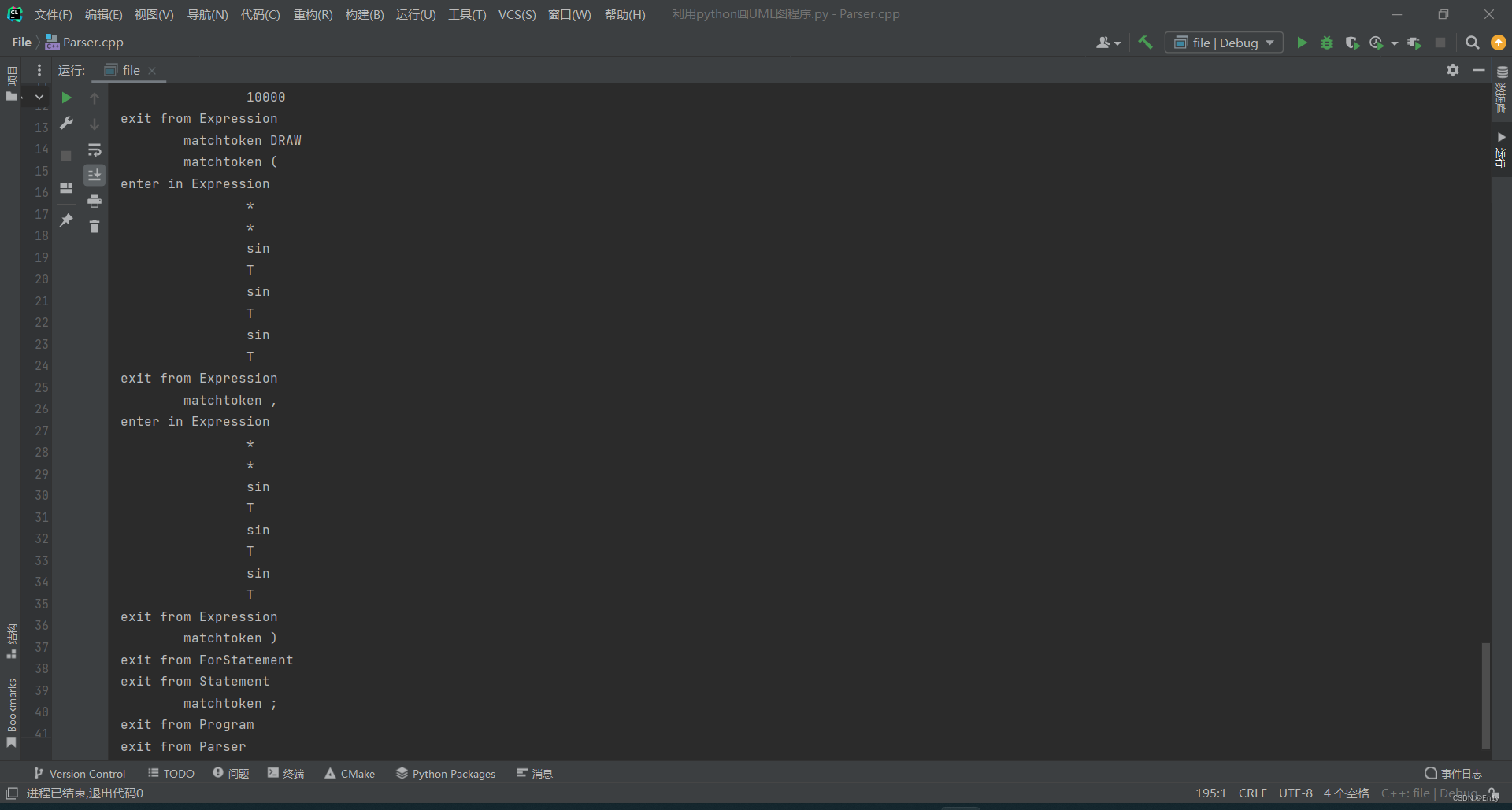
语法分析器的目的是判断词法分析器得到的记号是否合法,以及记号组成的句子是否合法。
语法分析器的设计思路:
比如文本里装的是:
ORIGIN IS (-16+5**3/cos(pi),2*120);
我们通过第一部分的词法分析器就能得到一个记号流:
ORIGIN IS L_BRACKET CONST_ID MUL CONST_ID COMMA CONST_ID MUL CONST_ID R_BRACKET SEMICO
我们现在从记号流里面取出第一个记号ORIGIN,所以我们要匹配OriginStatement,继续取下一个记号,要想符合OriginStatement的语法,下一个记号应该匹配IS,如果下一个记号不能匹配IS,那就语法报错后退出;如果下一个记号匹配的是IS,我们就继续匹配,如果我们在匹配过程中取到了ERRTOKEN类型的记号,那么就词法报错后退出。
所以设计思路就是:
依次取记号,如果是ERRTOKEN类型就词法报错,如果匹配不了语法,那就语法报错。
需要注意到的是括号和逗号之间的是两个表达式,所以我们要设计一个表达式树结构,比如给的这个例子我们匹配完左括号之后,要生成一个表达式树来表示-16+5**3/cos(pi)。
表达式树的节点可以分为三类:
1.叶节点: 常数CONST_ID、参数T
2.有两个孩子的节点 也就是运算符节点: 加PLUS、减MINUS、乘MUL、除DIV、幂运算POWER (这时候有两个特例就是一元加和一元减,比如+5,这个+的左孩子就是NULL,右孩子是5,就将+5转换成5了;还有-5,这个-的左孩子就是0,右孩子就是5,就将-5转换成0-5了)
3.有一个孩子的节点 也就是函数节点: 函数FUNC
表达式树节点代码:
typedef double (*FuncPtr)(double);
struct ExprNode{
Token_Type OpCode;
union{
struct{
ExprNode *Left, *Right;
} CaseOperator;
struct{
ExprNode *Child;
FuncPtr MathFuncPtr;
}CaseFunc;
double CaseConst;
double *CaseParmPtr;
}Content;
};表达式树节点的生成,本来我是根据匹配的记号类型的不同设计四个函数生成不同类型的节点,但是PPT上给出的利用可变列表生成节点的方法更简便,代码如下。 这段代码的意思是: 如果现在匹配的是常数CONST_ID类型,那我们传进去的肯定是常数的值value,我们就可以生成一个节点,这个节点的CaseConst指针指向常数的值;如果我们匹配的是参数T类型,那就生成一个节点,这个节点的CaseParmPtr指针指向Parameter;如果我们匹配的是函数FUNC类型,那我们传进去的肯定是一个函数指针以及一个表达式树节点,那就可以生成一个节点,这个节点的MathFuncPtr指针指向传入的函数,Child孩子指针指向传入的表达式树节点;如果我们匹配的是运算符例如PLUS/MINUS这些类型,那我们传进去的肯定是两个表达式节点,那就可以生成一个节点,这个节点的Left左孩子指针指向传入的第一个节点,Right右孩子指针指向传入的第二个节点。
struct ExprNode* MakeExprNode(Token_Type opcode,...){
struct ExprNode *ExprPtr = new (struct ExprNode);
ExprPtr -> OpCode = opcode;
va_list ArgPtr;
va_start(ArgPtr,opcode);
switch (opcode) {
case CONST_ID:ExprPtr->Content.CaseConst =(double) va_arg(ArgPtr,double );break;
case T:ExprPtr->Content.CaseParmPtr = &Parameter;break;
case FUNC:
ExprPtr->Content.CaseFunc.MathFuncPtr = (FuncPtr) va_arg(ArgPtr,FuncPtr);
ExprPtr->Content.CaseFunc.Child = (struct ExprNode*) va_arg(ArgPtr,struct ExprNode*);break;
default:
ExprPtr->Content.CaseOperator.Left = (struct ExprNode*) va_arg(ArgPtr,struct ExprNode*);
ExprPtr->Content.CaseOperator.Right = (struct ExprNode*) va_arg(ArgPtr,struct ExprNode*);break;
}
va_end(ArgPtr);
return ExprPtr;
}利用递归进行表达式树的打印,注意一下,上面两段代码都是表达式树的节点的设计和生成,下面的代码是打印一整棵表达式树。通过递归先序遍历打印表达式树:传入表达式树的根节点,如果节点类型是CONST_ID那就说明这个节点只有CaseConst指针有值,打印CaseConst指针指向的值;如果节点类型是T那就打印"T";如果节点类型是FUNC那就说明这个节点的MathFuncPtr和Child指针有值,先根据MathFuncPtr指向的函数打印函数的名称,然后用递归打印以孩子节点作为根节点的子树;如果节点类型是运算符,那就先打印运算符,然后递归打印分别以左右孩子节点为根节点的两棵子树。
void OutExprNode(struct ExprNode* Tree){
cout << "tt";
switch (Tree->OpCode) {
case CONST_ID: cout << Tree->Content.CaseConst << endl;break;
case T: cout << "T" << endl;break;
case FUNC:{
if(Tree->Content.CaseFunc.MathFuncPtr = sin){cout << "sin" << endl;}
else if(Tree->Content.CaseFunc.MathFuncPtr = cos){cout << "cos" << endl;}
else if(Tree->Content.CaseFunc.MathFuncPtr = log){cout << "log" << endl;}
else if(Tree->Content.CaseFunc.MathFuncPtr = exp){cout << "exp" << endl;}
else if(Tree->Content.CaseFunc.MathFuncPtr = tan){cout << "tan" << endl;}
else if(Tree->Content.CaseFunc.MathFuncPtr = sqrt){cout << "sqrt" << endl;}
OutExprNode(Tree->Content.CaseFunc.Child);
}break;
case PLUS:{
cout << "+" << endl;
OutExprNode(Tree->Content.CaseOperator.Left);
OutExprNode(Tree->Content.CaseOperator.Right);
}break;
case MINUS:{
cout << "-" << endl;
OutExprNode(Tree->Content.CaseOperator.Left);
OutExprNode(Tree->Content.CaseOperator.Right);
}break;
case MUL:{
cout << "*" << endl;
OutExprNode(Tree->Content.CaseOperator.Left);
OutExprNode(Tree->Content.CaseOperator.Right);
}break;
case DIV:{
cout << "/" << endl;
OutExprNode(Tree->Content.CaseOperator.Left);
OutExprNode(Tree->Content.CaseOperator.Right);
}break;
case POWER:{
cout << "**" << endl;
OutExprNode(Tree->Content.CaseOperator.Left);
OutExprNode(Tree->Content.CaseOperator.Right);
}break;
}
}绘图语言的文法:
Program -> { Statement SEMICO }
Statement -> OriginStatement | ScaleStatement | RotStatement | ForStatement
OriginStatement -> ORIGIN IS L_BRACKET Expression COMMA Expression R_BRACKET
ScaleStatement -> SCALE IS L_BRACKET Expression COMMA Expression R_BRACKET
RotStatement -> ROT IS Expression
ForStatement -> FOR T FROM Expression TO Expression STEP Expression DRAW L_BRACKET Expression COMMA Expression R_BRACKET
表达式树的产生式:
Expression -> Term { ( PLUS | MINUS ) Term }
Term -> Factor { ( MUL | DIV ) Factor }
Factor -> PLUS Factor | MINUS Factor | Component
Component -> Atom POWER Component | Atom
Atom -> CONST_ID | T | FUNC L_BRACKET Expression R_BRACKET | L_BRACKET Expression R_BRACKET
根据绘图语言文法和表达式树的产生式,我们可以设计一个Parsers类,在类里利用迭代实现文法和表达式树的产生。
Parsers类里我们首先定义一个构造函数 Parsers(){LoadFileTokens();} 作用是当我们创建一个Parsers类实例的时候自动调用LoadFileTokens()函数将文本的记号流装到容器里。
先写三个辅助函数
void FetchToken();
void MatchToken(Token_Type t);
void SyntaxError(int x);
void FetchToken(); 这个函数的作用是从记号流里获取一个记号,如果获取的记号是ERRTOKEN类,就词法报错后退出
void FetchToken(){
TempToken = TokenStream[cnt];
cnt ++;
if(TempToken.type == ERRTOKEN) SyntaxError(1);
}void MatchToken(Token_Type t); 这个函数的参数是一个单词类型,作用是将当前从记号流里获取的记号和这个单词类型进行匹配,如果不匹配就语法报错后退出,否则就获取下一个记号
void MatchToken(Token_Type t){
if(TempToken.type != t) SyntaxError(2);
FetchToken();
}void SyntaxError(int x); 这个函数的参数是一个整数,如果整数是1就代表词法错误,如果整数是2就代表语法错误
void SyntaxError(int x){
if(x == 1){
cout << "line No: " << TempToken.TokenLine << " 有一个错误记号: " << TempToken.lexeme << endl;
exit(0);
}
else if(x == 2) {
cout << "line No: " << TempToken.TokenLine << " 有一个不是预期的记号: " << TempToken.lexeme << endl;
exit(0);
}
}根据上面给出的文法和表达式树的产生式,我们利用迭代实现文法和表达式树的生成,我们需要下列函数
void Parser();
void Program();
void Statement();
void OriginStatement();
void ScaleStatement();
void ForStatement();
void RotStatement();
struct ExprNode* Expression();
struct ExprNode* Term();
struct ExprNode* Factor();
struct ExprNode* Component();
struct ExprNode* Atom();
Parser()函数获取第一个记号,然后进入Program()函数
void Parser(){
FetchToken();
Program();
}根据上述文法 Program -> { Statement SEMICO }
我们写一个 Program()函数,如下:
void Program(){
while (TempToken.type != NONTOKEN){
Statement();
MatchToken(SEMICO);
}
}根据上述文法 Statement -> OriginStatement | ScaleStatement | RotStatement | ForStatement
我们写一个Statement()函数,如下:
void Statement(){
if(TempToken.type == ORIGIN) OriginStatement();
else if(TempToken.type == SCALE) ScaleStatement();
else if(TempToken.type == ROT) RotStatement();
else if(TempToken.type == FOR) ForStatement();
else SyntaxError(2);
}根据上述文法 OriginStatement -> ORIGIN IS L_BRACKET Expression COMMA Expression R_BRACKET
我们写一个OriginStatement()函数,如下:// ScaleStatement()、RotStatement()、ForStatement()这三个函数根据上述文法可以类比OriginStatement()函数写一下
void OriginStatement(){
MatchToken(ORIGIN);
MatchToken(IS);
MatchToken(L_BRACKET);
origin_xptr = Expression();
MatchToken(COMMA);
origin_yptr = Expression();
MatchToken(R_BRACKET);
}根据上面表达式树的产生式第一条
Expression -> Term { ( PLUS | MINUS ) Term }
写一个struct ExprNode* Expression()函数,如下:
struct ExprNode* Expression(){
struct ExprNode *left, *right;
Token_Type token_tmp;
left = Term();
while (TempToken.type == PLUS || TempToken.type == MINUS)
{
token_tmp = TempToken.type;
MatchToken(token_tmp);
right = Term();
left = MakeExprNode(token_tmp,left,right);
}
return left;
}其他表达式树生成函数跟Expression()函数类似,根据上面表达式树的产生式可以类比Expression()函数依次写出来,不想分析了,放在底下完整代码里了,第二部分语法分析器结束。
完整代码:
#include <cmath>
#include <cctype>
#include <fstream>
#include <string>
#include <iostream>
#include <algorithm>
#include <vector>
#include <cstdlib>
#include <cstdarg>
#include <graphics.h>
#include <conio.h>
#define pi acos(-1.0)
#define e exp(1.0)
using namespace std;
enum Token_Type{
ORIGIN,SCALE,ROT,IS,TO,STEP,DRAW,FOR,FROM,//保留字
T, //参数
SEMICO,L_BRACKET,R_BRACKET,COMMA, //; ( ) ,分隔符
PLUS,MINUS,MUL,DIV,POWER, //+ - * / **运算符
FUNC, //函数
CONST_ID, //常数
NONTOKEN, //空记号
ERRTOKEN //出错记号
};
typedef struct Tokens{
Token_Type type;
string lexeme;
double value;
double (*FuncPtr)(double);
int TokenLine;
} Tokens;
static Tokens TokenTab[] = {
{ORIGIN, "ORIGIN", 0.0, NULL,0},
{SCALE, "SCALE", 0.0, NULL,0},
{ROT, "ROT", 0.0, NULL,0},
{IS, "IS", 0.0, NULL,0},
{TO, "TO", 0.0, NULL,0},
{STEP, "STEP", 0.0, NULL,0},
{DRAW, "DRAW", 0.0, NULL,0},
{FOR, "FOR", 0.0, NULL,0},
{FROM, "FROM", 0.0, NULL,0},
{T, "T", 0.0, NULL,0},
{FUNC, "SIN", 0.0, sin,0},
{FUNC, "COS", 0.0, cos,0},
{FUNC, "TAN", 0.0, tan,0},
{FUNC, "LN", 0.0, log,0},
{FUNC, "EXP", 0.0, exp,0},
{FUNC, "SQRT", 0.0, sqrt,0},
{CONST_ID, "PI", pi, NULL,0},
{CONST_ID, "E", e, NULL,0}
};
class Scanner{
public:
void OpenFile(){ //打开文件
cin >> FileName;
F.open(FileName,ios::in|ios::out);
}
void CloseFile(){ //关闭文件
F.close();
}
void EmptyBuffer(){ //清空缓冲区
TokenBuffer = "";
}
void AddCharToBuffer(char TempC){ //将字符添加到缓冲区
TokenBuffer += TempC;
}
Tokens SearchCharInDict(string TempS){ //查字典
Tokens T = {ERRTOKEN, TempS, 0.0, NULL,0};
transform(TempS.begin(),TempS.end(),TempS.begin(),::toupper);
for(int i = 0; i < 18; i ++) {
if (TempS == TokenTab[i].lexeme){
T.type = TokenTab[i].type;
T.value = TokenTab[i].value;
T.FuncPtr = TokenTab[i].FuncPtr;
}
}
return T;
}
Tokens CreateToken(Token_Type type, string lexeme, double value, double (*FuncPtr)(double), int Line){
Tokens TempToken;
TempToken.type = type;
TempToken.lexeme = lexeme;
TempToken.value = value;
TempToken.FuncPtr = FuncPtr;
TempToken.TokenLine = Line;
return TempToken;
}
Tokens GetToken(){
char c;
static int line = 1; //行数
Tokens TempT;
EmptyBuffer(); //清空缓冲区
while(1){
c = F.get();
if(c == EOF){
TempT = CreateToken(NONTOKEN,"EOF",0.0,NULL,line);
return TempT;
}
else if(c == ' ' || c == 't') continue;
else if(c == 'n'){ line++; continue;}
else if(isalpha(c)){
AddCharToBuffer(c);
while(1){
c = F.get();
if(isalnum(c)) AddCharToBuffer(c);
else break;
}
F.putback(c);
TempT = SearchCharInDict(TokenBuffer);
TempT.TokenLine = line;
return TempT;
}
else if(isdigit(c)){
AddCharToBuffer(c);
while(1){
c = F.get();
if(isdigit(c)) AddCharToBuffer(c);
else break;
}
if(c == '.') {
AddCharToBuffer(c);
while (1){
c = F.get();
if(isdigit(c)) AddCharToBuffer(c);
else break;
}
}
F.putback(c);
TempT = CreateToken(CONST_ID,TokenBuffer, stod(TokenBuffer),NULL,line);
return TempT;
}
else if(c == ';'){
TempT = CreateToken(SEMICO,";",0.0,NULL,line);
return TempT;
}
else if(c == '('){
TempT = CreateToken(L_BRACKET,"(",0.0,NULL,line);
return TempT;
}
else if(c == ')'){
TempT = CreateToken(R_BRACKET,")",0.0,NULL,line);
return TempT;
}
else if(c == ','){
TempT = CreateToken(COMMA,",",0.0,NULL,line);
return TempT;
}
else if(c == '+'){
TempT = CreateToken(PLUS,"+",0.0,NULL,line);
return TempT;
}
else if(c == '-') {
c = F.get();
if(c == '-'){
while(c!='n' && c!=EOF) c = F.get();
if(c == EOF){
TempT = CreateToken(NONTOKEN,"EOF",0.0,NULL,line);
return TempT;
}
else {
line++;
continue;
}
}
else {
F.putback(c);
TempT = CreateToken(MINUS,"-",0.0,NULL,line);
return TempT;
}
}
else if(c == '/'){
c = F.get();
if(c == '/'){
while(c!='n'&&c!=EOF) c = F.get();
if(c == EOF){
TempT = CreateToken(NONTOKEN,"EOF",0.0,NULL,line);
return TempT;
}
else {
line++;
continue;
}
}
else {
F.putback(c);
TempT = CreateToken(DIV,"/",0.0,NULL,line);
return TempT;
}
}
else if(c == '*'){
c = F.get();
if(c == '*'){
TempT = CreateToken(POWER,"**",0.0,NULL,line);
return TempT;
}
else{
F.putback(c);
TempT = CreateToken(MUL,"*",0.0,NULL,line);
return TempT;
}
}
else{
TempT = CreateToken(ERRTOKEN,"EOF",0.0,NULL,line);
return TempT;
}
}
}
private:
string FileName, TokenBuffer = ""; //文件名和缓冲区
fstream F;
};
vector<Tokens> TokenStream;
void LoadFileTokens(){
Scanner s;
Tokens t;
cout << "Please Enter A File With Path:" << endl;
s.OpenFile();
t = s.GetToken();
TokenStream.push_back(t);
while (t.type != NONTOKEN){
t = s.GetToken();
TokenStream.push_back(t);
}
s.CloseFile();
}
typedef double (*FuncPtr)(double);
struct ExprNode{
Token_Type OpCode;
union{
struct{
ExprNode *Left, *Right;
} CaseOperator;
struct{
ExprNode *Child;
FuncPtr MathFuncPtr;
}CaseFunc;
double CaseConst;
double *CaseParmPtr;
}Content;
};
class Parsers{
public:
Parsers(){LoadFileTokens();}
double Parameter = 0;
struct ExprNode *origin_xptr, *origin_yptr, *scale_xptr, *scale_yptr, *rot_ptr, *start_ptr, *end_ptr, *step_ptr, *for_xptr, *for_yptr;
static int cnt;
Tokens TempToken;
struct ExprNode* MakeExprNode(Token_Type opcode,...){
struct ExprNode *ExprPtr = new (struct ExprNode);
ExprPtr -> OpCode = opcode;
va_list ArgPtr;
va_start(ArgPtr,opcode);
switch (opcode) {
case CONST_ID:ExprPtr->Content.CaseConst =(double) va_arg(ArgPtr,double );break;
case T:ExprPtr->Content.CaseParmPtr = &Parameter;break;
case FUNC:
ExprPtr->Content.CaseFunc.MathFuncPtr = (FuncPtr) va_arg(ArgPtr,FuncPtr);
ExprPtr->Content.CaseFunc.Child = (struct ExprNode*) va_arg(ArgPtr,struct ExprNode*);break;
default:
ExprPtr->Content.CaseOperator.Left = (struct ExprNode*) va_arg(ArgPtr,struct ExprNode*);
ExprPtr->Content.CaseOperator.Right = (struct ExprNode*) va_arg(ArgPtr,struct ExprNode*);break;
}
va_end(ArgPtr);
return ExprPtr;
}
void OutExprNode(struct ExprNode* Tree){
cout << "tt";
switch (Tree->OpCode) {
case CONST_ID: cout << Tree->Content.CaseConst << endl;break;
case T: cout << "T" << endl;break;
case FUNC:{
if(Tree->Content.CaseFunc.MathFuncPtr = sin){cout << "sin" << endl;}
else if(Tree->Content.CaseFunc.MathFuncPtr = cos){cout << "cos" << endl;}
else if(Tree->Content.CaseFunc.MathFuncPtr = log){cout << "log" << endl;}
else if(Tree->Content.CaseFunc.MathFuncPtr = exp){cout << "exp" << endl;}
else if(Tree->Content.CaseFunc.MathFuncPtr = tan){cout << "tan" << endl;}
else if(Tree->Content.CaseFunc.MathFuncPtr = sqrt){cout << "sqrt" << endl;}
OutExprNode(Tree->Content.CaseFunc.Child);
}break;
case PLUS:{
cout << "+" << endl;
OutExprNode(Tree->Content.CaseOperator.Left);
OutExprNode(Tree->Content.CaseOperator.Right);
}break;
case MINUS:{
cout << "-" << endl;
OutExprNode(Tree->Content.CaseOperator.Left);
OutExprNode(Tree->Content.CaseOperator.Right);
}break;
case MUL:{
cout << "*" << endl;
OutExprNode(Tree->Content.CaseOperator.Left);
OutExprNode(Tree->Content.CaseOperator.Right);
}break;
case DIV:{
cout << "/" << endl;
OutExprNode(Tree->Content.CaseOperator.Left);
OutExprNode(Tree->Content.CaseOperator.Right);
}break;
case POWER:{
cout << "**" << endl;
OutExprNode(Tree->Content.CaseOperator.Left);
OutExprNode(Tree->Content.CaseOperator.Right);
}break;
}
}
void FetchToken(){
TempToken = TokenStream[cnt];
cnt ++;
if(TempToken.type == ERRTOKEN) SyntaxError(1);
}
void MatchToken(Token_Type t){
if(TempToken.type != t) SyntaxError(2);
FetchToken();
}
void SyntaxError(int x){
if(x == 1){
cout << "line No:" << TempToken.TokenLine << " Has An Error Token: " << TempToken.lexeme << endl;
exit(0);
}
else if(x == 2) {
cout << "line No:" << TempToken.TokenLine << " Has An Unexpected Token: " << TempToken.lexeme << endl;
exit(0);
}
}
void Parser(){
cout << "enter in Parser" << endl;
FetchToken();
Program();
cout << "exit from Parser" << endl;
}
void Program(){
cout << "enter in Program" << endl;
while (TempToken.type != NONTOKEN){
Statement();
MatchToken(SEMICO);
cout << "tmatchtoken ;" << endl;
}
cout << "exit from Program" << endl;
}
void Statement(){
cout << "enter in Statement" << endl;
if(TempToken.type == ORIGIN) OriginStatement();
else if(TempToken.type == SCALE) ScaleStatement();
else if(TempToken.type == ROT) RotStatement();
else if(TempToken.type == FOR) ForStatement();
else SyntaxError(2);
cout << "exit from Statement" << endl;
}
void OriginStatement(){
cout << "enter in OriginStatement" << endl;
MatchToken(ORIGIN);
cout << "tmatchtoken ORIGIN" << endl;
MatchToken(IS);
cout << "tmatchtoken IS" << endl;
MatchToken(L_BRACKET);
cout << "tmatchtoken (" << endl;
cout << "enter in Expression" << endl;
origin_xptr = Expression();
OutExprNode(origin_xptr);
cout << "exit from Expression" << endl;
MatchToken(COMMA);
cout << "tmatchtoken ," << endl;
cout << "enter in Expression" << endl;
origin_yptr = Expression();
OutExprNode(origin_yptr);
cout << "exit from Expression" << endl;
MatchToken(R_BRACKET);
cout << "tmatchtoken )" << endl;
cout << "exit from OriginStatement" << endl;
}
void RotStatement(){
cout << "enter in RotStatement" << endl;
MatchToken(ROT);
cout << "tmatchtoken ROT" << endl;
MatchToken(IS);
cout << "tmatchtoken IS" << endl;
cout << "enter in Expression" << endl;
rot_ptr = Expression();
OutExprNode(rot_ptr);
cout << "exit from Expression" << endl;
cout << "exit from RotStatement" << endl;
}
void ScaleStatement(){
cout << "enter in ScaleStatement" << endl;
MatchToken(SCALE);
cout << "tmatchtoken SCALE" << endl;
MatchToken(IS);
cout << "tmatchtoken IS" << endl;
MatchToken(L_BRACKET);
cout << "tmatchtoken (" << endl;
cout << "enter in Expression" << endl;
scale_xptr = Expression();
OutExprNode(scale_xptr);
cout << "exit from Expression" << endl;
MatchToken(COMMA);
cout << "tmatchtoken ," << endl;
cout << "enter in Expression" << endl;
scale_yptr = Expression();
OutExprNode(scale_yptr);
cout << "exit from Expression" << endl;
MatchToken(R_BRACKET);
cout << "tmatchtoken )" << endl;
cout << "exit from ScaleStatement" << endl;
}
void ForStatement(){
cout << "enter in ForStatement" << endl;
MatchToken(FOR);
cout << "tmatchtoken FOR" << endl;
MatchToken(T);
cout << "tmatchtoken T" << endl;
MatchToken(FROM);
cout << "tmatchtoken FROM" << endl;
cout << "enter in Expression" << endl;
start_ptr = Expression();
OutExprNode(start_ptr);
cout << "exit from Expression" << endl;
MatchToken(TO);
cout << "tmatchtoken TO" << endl;
cout << "enter in Expression" << endl;
end_ptr = Expression();
OutExprNode(end_ptr);
cout << "exit from Expression" << endl;
MatchToken(STEP);
cout << "tmatchtoken STEP" << endl;
cout << "enter in Expression" << endl;
step_ptr = Expression();
OutExprNode(step_ptr);
cout << "exit from Expression" << endl;
MatchToken(DRAW);
cout << "tmatchtoken DRAW" << endl;
MatchToken(L_BRACKET);
cout << "tmatchtoken (" << endl;
cout << "enter in Expression" << endl;
for_xptr = Expression();
OutExprNode(for_xptr);
cout << "exit from Expression" << endl;
MatchToken(COMMA);
cout << "tmatchtoken ," << endl;
cout << "enter in Expression" << endl;
for_yptr = Expression();
OutExprNode(for_yptr);
cout << "exit from Expression" << endl;
MatchToken(R_BRACKET);
cout << "tmatchtoken )" << endl;
cout << "exit from ForStatement" << endl;
}
struct ExprNode* Expression(){
struct ExprNode *left, *right;
Token_Type token_tmp;
left = Term();
while (TempToken.type == PLUS || TempToken.type == MINUS)
{
token_tmp = TempToken.type;
MatchToken(token_tmp);
right = Term();
left = MakeExprNode(token_tmp,left,right);
}
return left;
}
struct ExprNode* Term(){
struct ExprNode *left, *right;
Token_Type token_tmp;
left = Factor();
while (TempToken.type == MUL || TempToken.type == DIV)
{
token_tmp = TempToken.type;
MatchToken(token_tmp);
right = Factor();
left = MakeExprNode(token_tmp,left,right);
}
return left;
}
struct ExprNode* Factor(){
struct ExprNode *left, *right;
if(TempToken.type == PLUS){
MatchToken(PLUS);
right = Factor();
left = NULL;
right = MakeExprNode(PLUS,left,right);
}
else if(TempToken.type == MINUS){
MatchToken(MINUS);
right = Factor();
left = MakeExprNode(CONST_ID,0.0);
right = MakeExprNode(MINUS,left,right);
}
else right = Component();
return right;
}
struct ExprNode* Component(){
struct ExprNode *left, *right;
left = Atom();
if(TempToken.type == POWER){
MatchToken(POWER);
right = Component();
left = MakeExprNode(POWER,left,right);
}
return left;
}
struct ExprNode* Atom(){
struct ExprNode *address, *tmp;
double const_value;
FuncPtr funcPtr_value;
if(TempToken.type == CONST_ID){
const_value = TempToken.value;
MatchToken(CONST_ID);
address = MakeExprNode(CONST_ID,const_value);
}
else if(TempToken.type == T){
MatchToken(T);
address = MakeExprNode(T);
}
else if(TempToken.type == FUNC){
funcPtr_value = TempToken.FuncPtr;
MatchToken(FUNC);
MatchToken(L_BRACKET);
tmp = Expression();
address = MakeExprNode(FUNC,funcPtr_value,tmp);
MatchToken(R_BRACKET);
}
else if(TempToken.type == L_BRACKET){
MatchToken(L_BRACKET);
address = Expression();
MatchToken(R_BRACKET);
}
else SyntaxError(2);
return address;
}
};
int Parsers::cnt = 0;
int main() {
Parsers P;
P.Parser();
return 0;
}最后
以上就是贪玩电源最近收集整理的关于编译原理上机 - 函数绘图语言(2) - 语法分析器 - C++代码(完整代码在结尾)的全部内容,更多相关编译原理上机内容请搜索靠谱客的其他文章。








发表评论 取消回复