| 实验 目的 要求 |
目的:
要求:
| |||
|
实 验 环 境
|
| |||
练习内容
步骤一:集群的启动
★ 该项的所有操作步骤使用专门用于集群的用户admin进行。
★ 启动HBase集群之前首先确保Zookeeper集群已被开启状态。(实验5台),Zookeeper的启动需要分别在每个计算机的节点上手动启动。如果家目录下执行启动报错,则需要进入zookeeper/bin目录执行启动命令。
★ 启动HBase集群之前首先确保Hadoop集群已被开启状态。 (实验5台)Hadoop只需要在主节点执行启动命令。
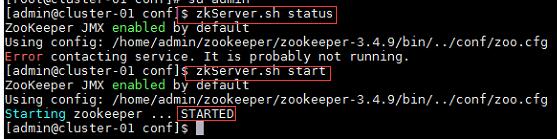
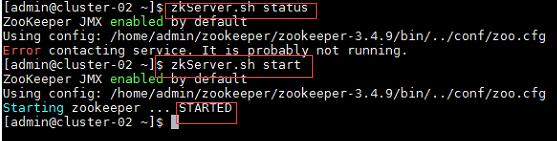
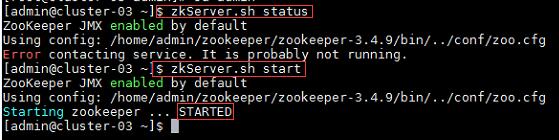
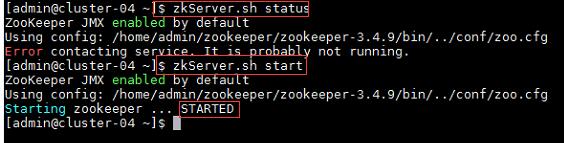
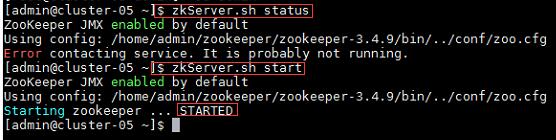
a) 在集群中所有主机上使用命令“zkServer.sh status”查看该节点Zookeeper服务当前的状态,若集群中只有一个“leader”节点,其余的均为“follower”节点,则集群的工作状态正常。如果Zookeeper未启动,则在集群中所有主机上使用命令“zkServer.sh start”启动Zookeeper服务的脚本;
b) 在主节点,查看Java进程信息,若有名为“NameNode”、“ResourceManager”的两个进程,则表示Hadoop集群的主节点启动成功。在每台数据节点,若有名为“DataNode”和“NodeManager”的两个进程,则表示Hadoop集群的数据节点启动成功, 如果不存在以上三个进程,则在主节点使用此命令,启动Hadoop集群。
主节点及备用主节点:


通信节点:



c) 确定Hadoop集群已启动状态,然后在主节点使用此命令,启动HBase集群, 在集群中所有主机上使用命令“jps”;

1、在主节点使用命令“hive”启动Hive,启动成功后能够进入Hive的控制台。
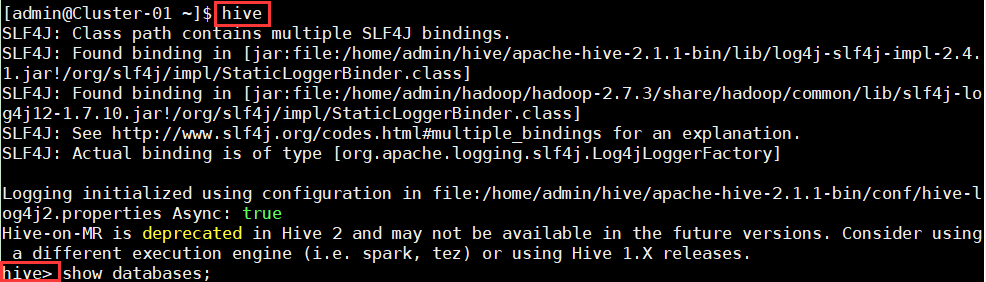
2、在控制台中使用命令“show databases;”查看当前的数据库列表。

3、在主节点使用命令“sqoop2-tool verify”验证配置是否正确;
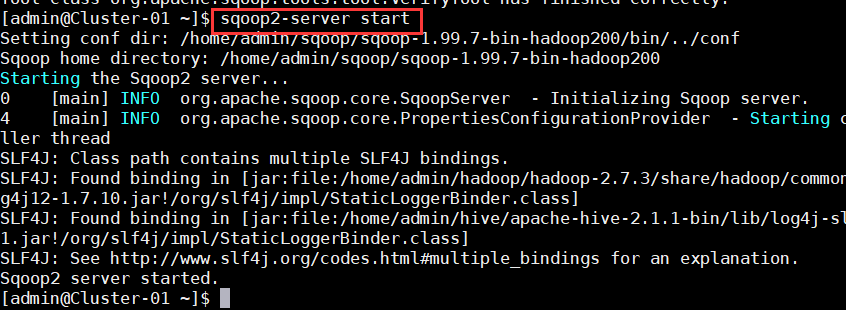
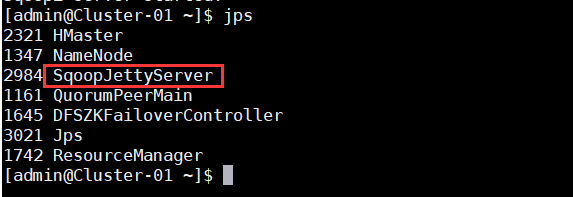
4、使用命令“sqoop2-server start”启动Sqoop服务器,并查看java进程,若有名为“SqoopJettyServer”的进程,则表示Sqoop启动成功;
5、使用命令“sqoop2-shell”进入Sqoop的控制台;

6、MySQL集群使用root用户进行操作;
a)启动管理节点;

b)启动数据服务节点;


c)启动SQL服务节点;


练习一:MySQL->HDFS
注:*MySQL集群使用root用户进行操作;
*Hadoop、Hbase、Hive、Sqoop使用admin用户进行操作;
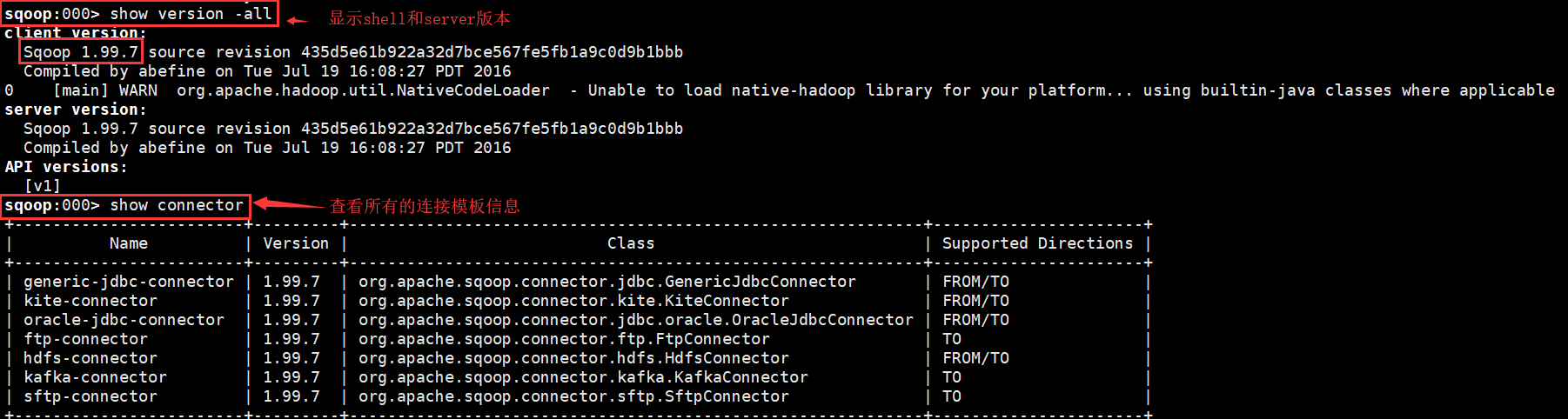
1、初始化Sqoop服务器连接参数;
命令:
$sqoop2-shell
>set server –host Cluster-01 –port 12000 –webapp sqoop
>show version –all
>show connector

2、建立MySQL测试表空间、表和数据;
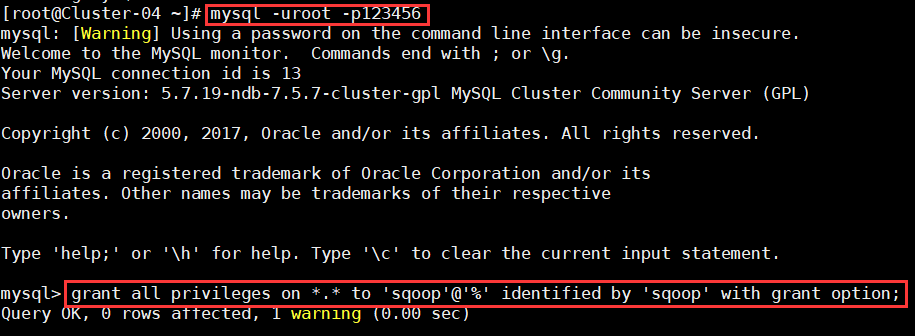
a)创建用户sqoop并授权;
命令:
$mysql -uroot -pmysqlabc
>grant all privileges on *.* to 'sqoop'@'%' identified by 'sqoop' with grant option;
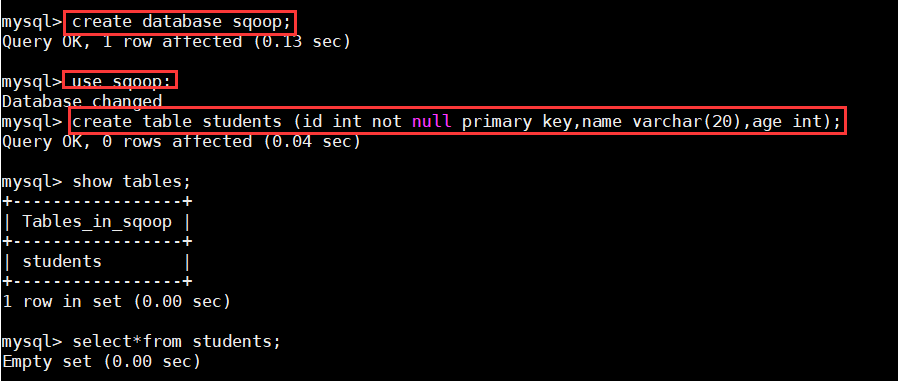
b)创建表空间(schema)sqoop,并创建测试表;
命令:
$create database sqoop;
>use sqoop;
>create table students (id int not null primary key,name varchar(20),age int);
>show tables;
>select * from students;
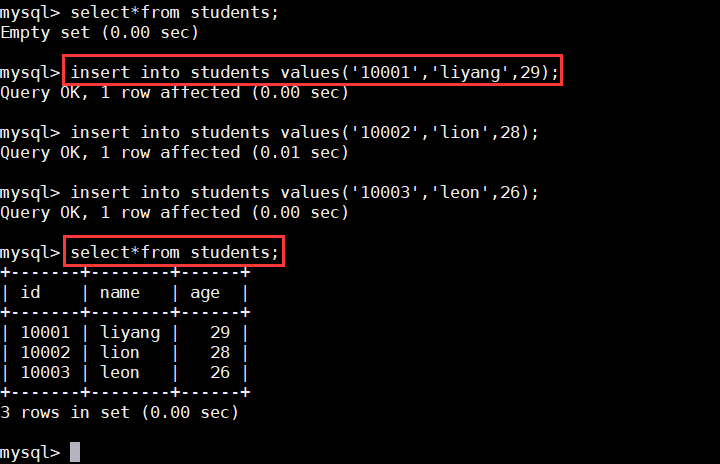
c)插入测试数据;
> insert into students values('10001','liyang',29);
> insert into students values('10002','lion',28);
> insert into students values('10003','leon',26);
> select * from students;
3、建立MySQL数据库连接
a) 把MySQL的数据库连接工具包“mysql-connector-java-5.1.42-bin.jar”上传到用户家目录的“setups”目录下,该目录为事先自行创建用于存放实训相关软件包的目录。

b) 将MySQL的数据库连接工具包添加到Sqoop的“extra”目录下
命令:
$ cp ~/setups/mysql-connector-java-5.1.42-bin.jar ~/sqoop/sqoop-1.99.7-bin-hadoop200/extra
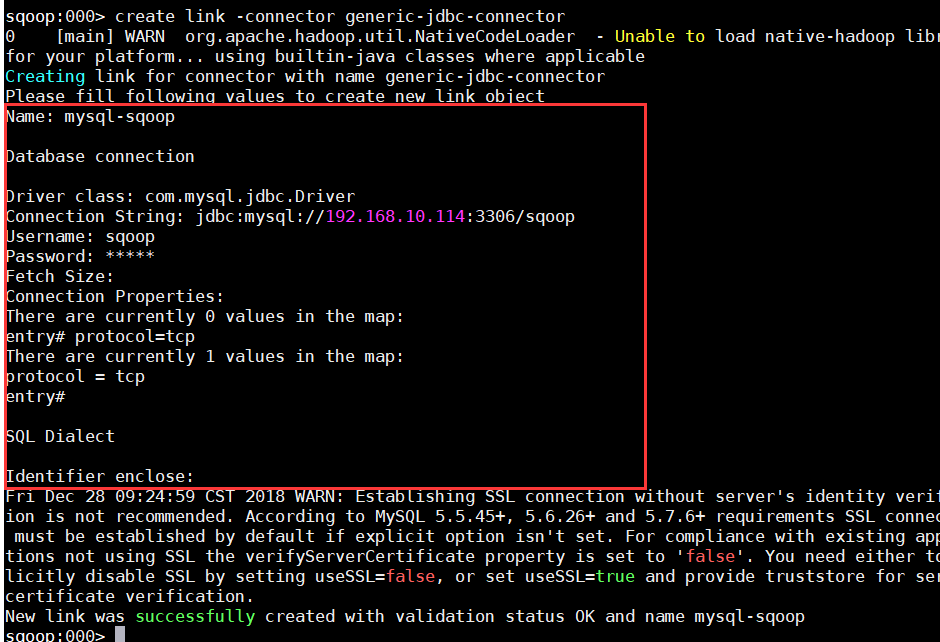
c)创建数据库连接;
命令:
>sqoop2-shell
>create link -connector generic-jdbc-connector
>show link

d)建立HDFS文件系统连接;
命令:
$sqoop2-shell
>create link -connector hdfs-connector
>show link;
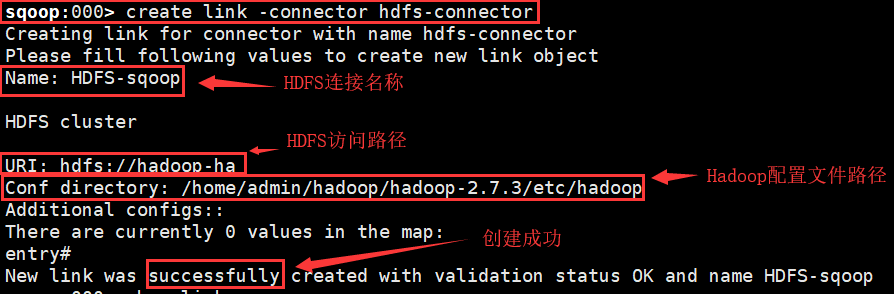
e)在HDFS创建用于存放导出的数据文件的目录;
命令:
#su admin
$hadoop fs -mkdir -p /user/admin/test/sqoop

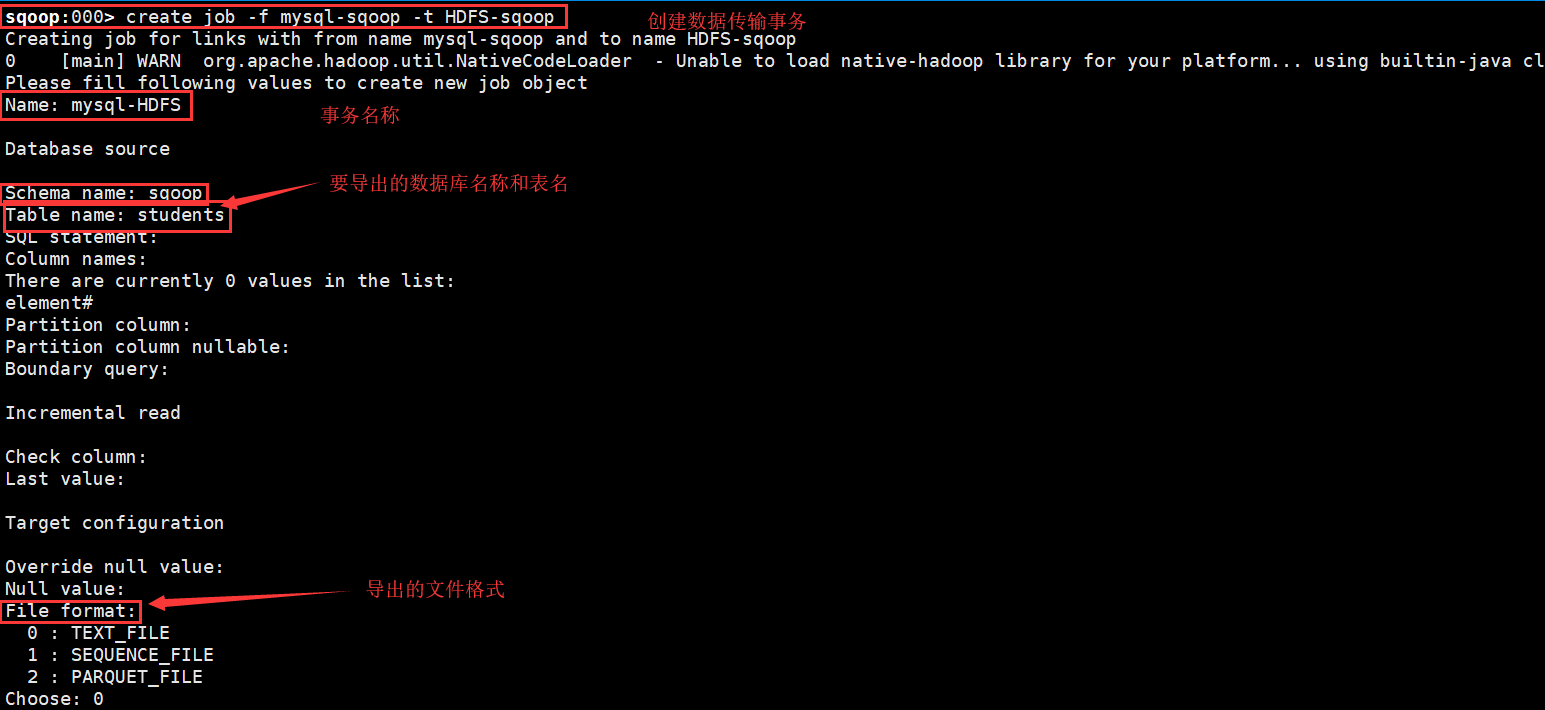
f)创建数据传输事物;
命令:
$sqoop2-shell
>create job -f mysql-sqoop -t HDFS-sqoop
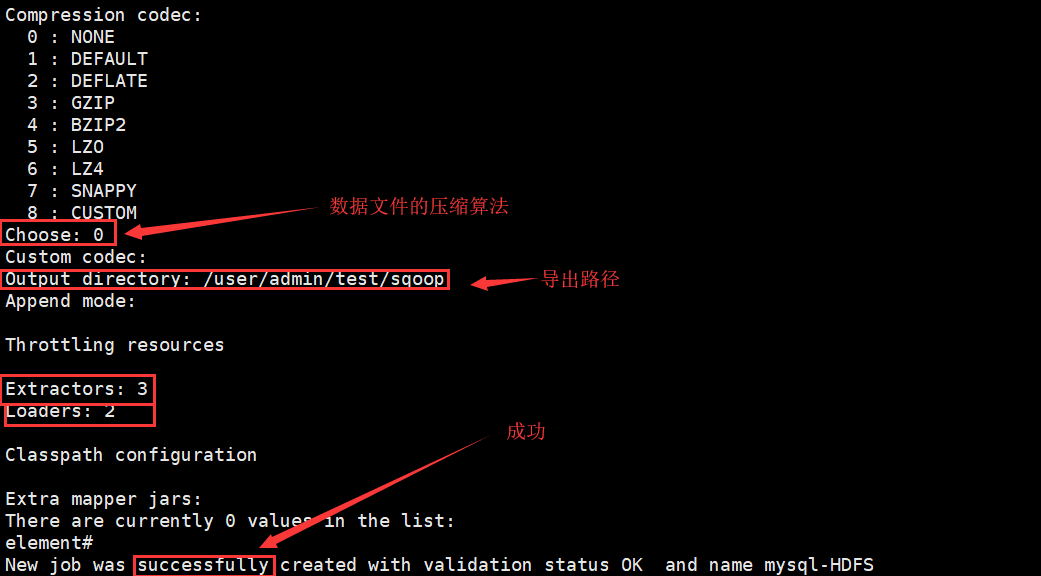
g)web查看
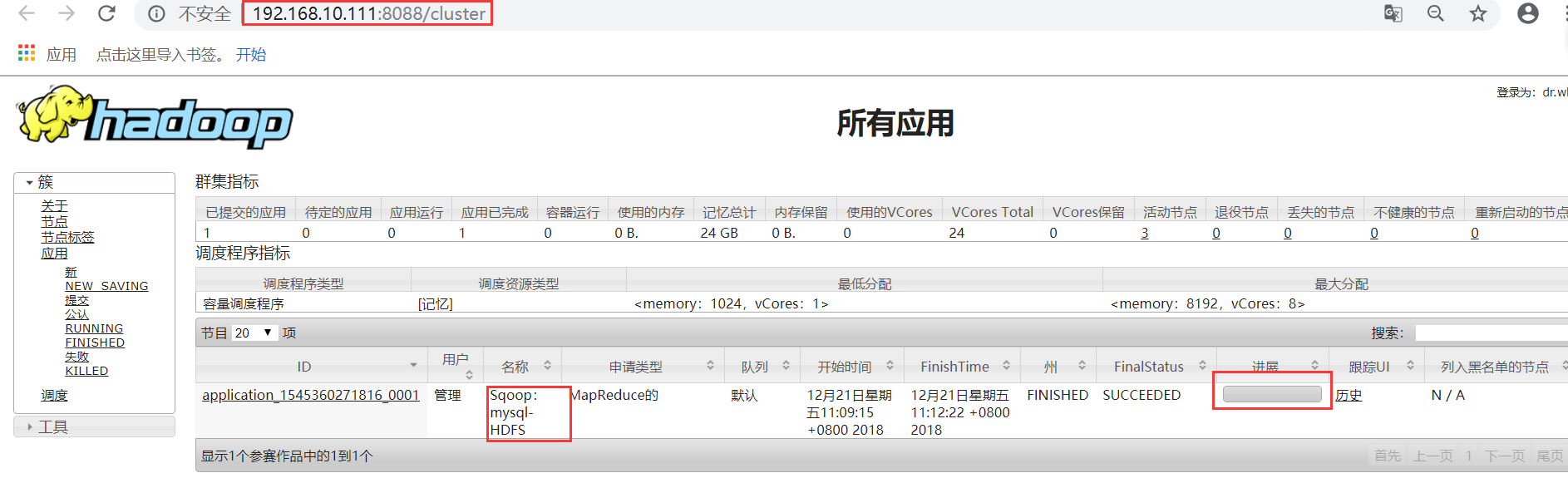
练习二:
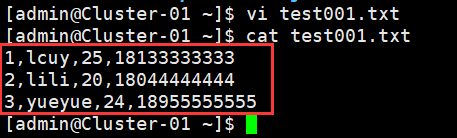
1、在admin用户家目录/home/admin/新建一个文本文件test001.txt,内容如下:
- 1,lcuy,25,18133333333
- 2,lili,20,18044444444
- 3,yueyue,24,18955555555
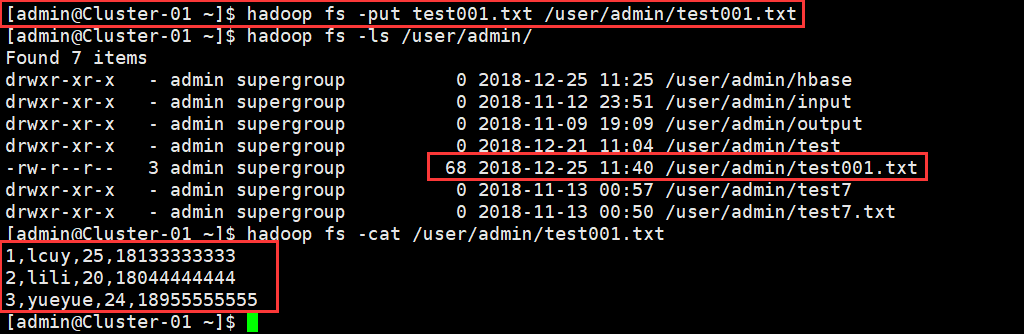
2、从本地文件系统复制文件到HDFS文件系统;
命令:
$ hadoop fs -put test001.txt /user/admin/test001.txt
$ hadoop fs -ls /user/admin/
$ hadoop fs -cat /user/admin/test001.txt
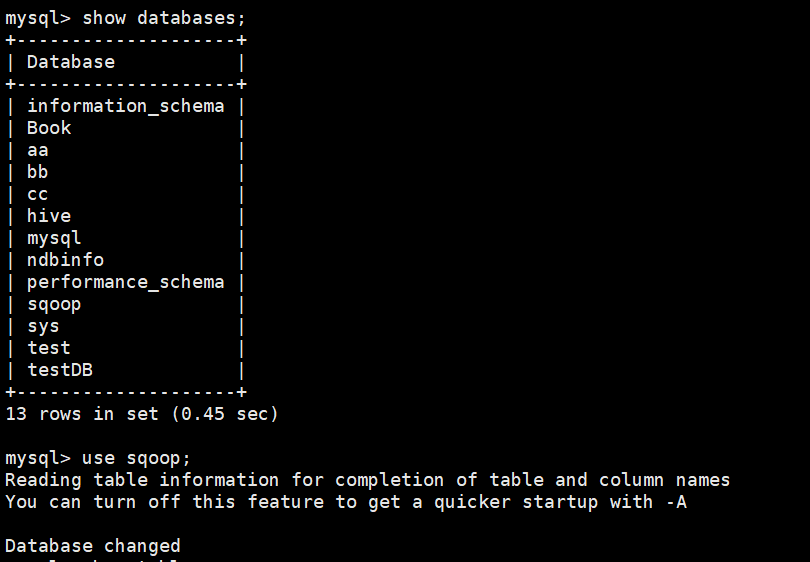
3、在Mysql提前创建好表结构;
命令:
# mysql -uroot -pmysqlabc
> show databases;
> grant all privileges on *.* to 'sqoop'@'%' identified by 'sqoop' with grant option;
> CREATE DATABASE sqoop;
> use sqoop;
> create table test001(id int not null primary key,name varchar(20),age int,tel varchar(20));
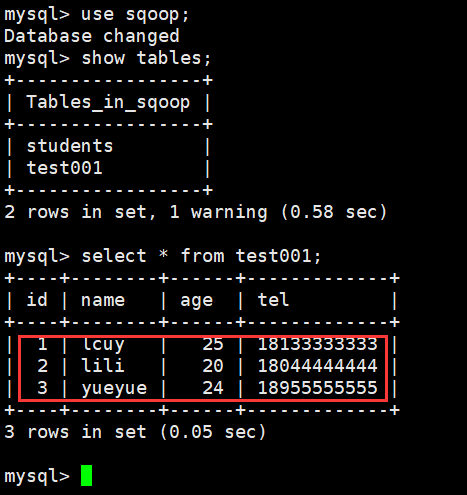
> select*from test001;
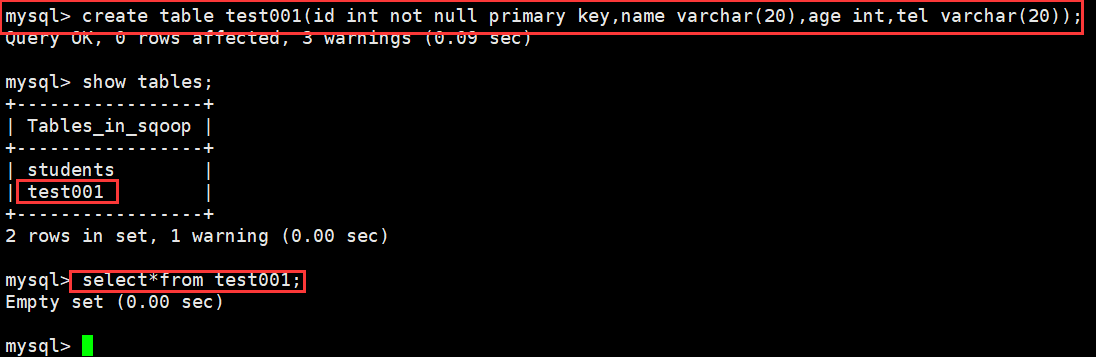
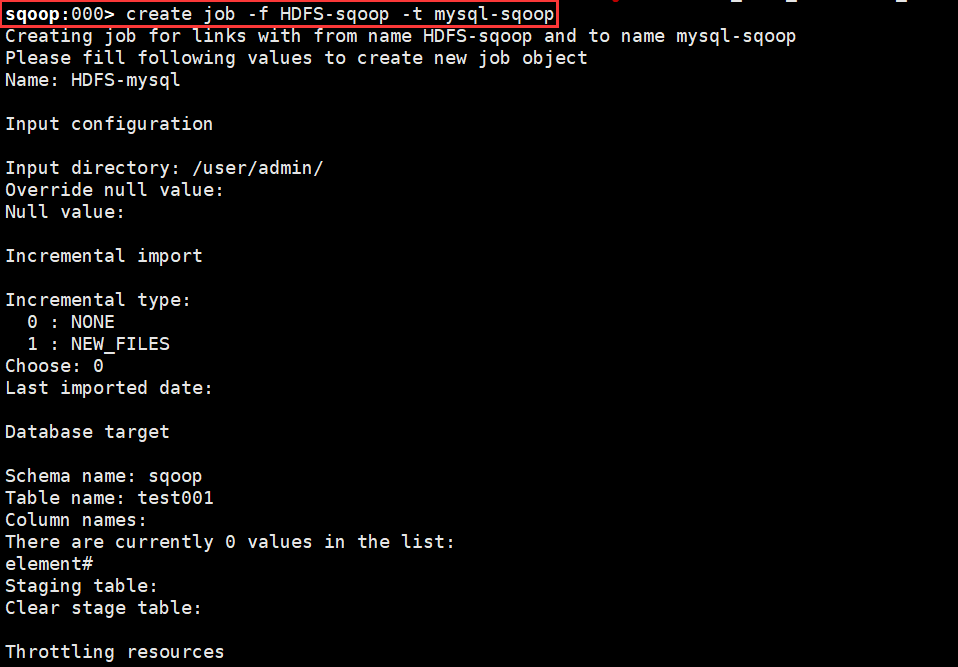
4、创建job并执行导入到MySQL中;
命令:
> show job
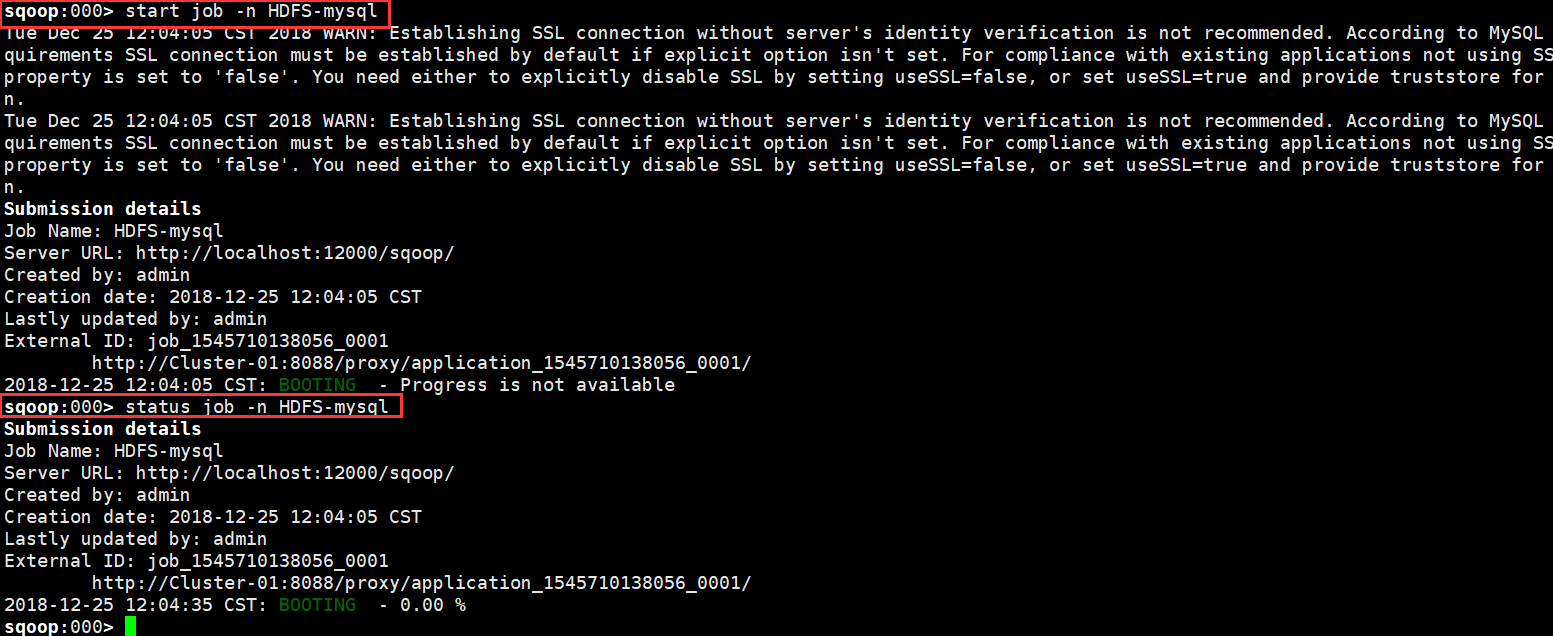
> start job -n HDFS-mysql
> status job -n HDFS-mysql
> exit

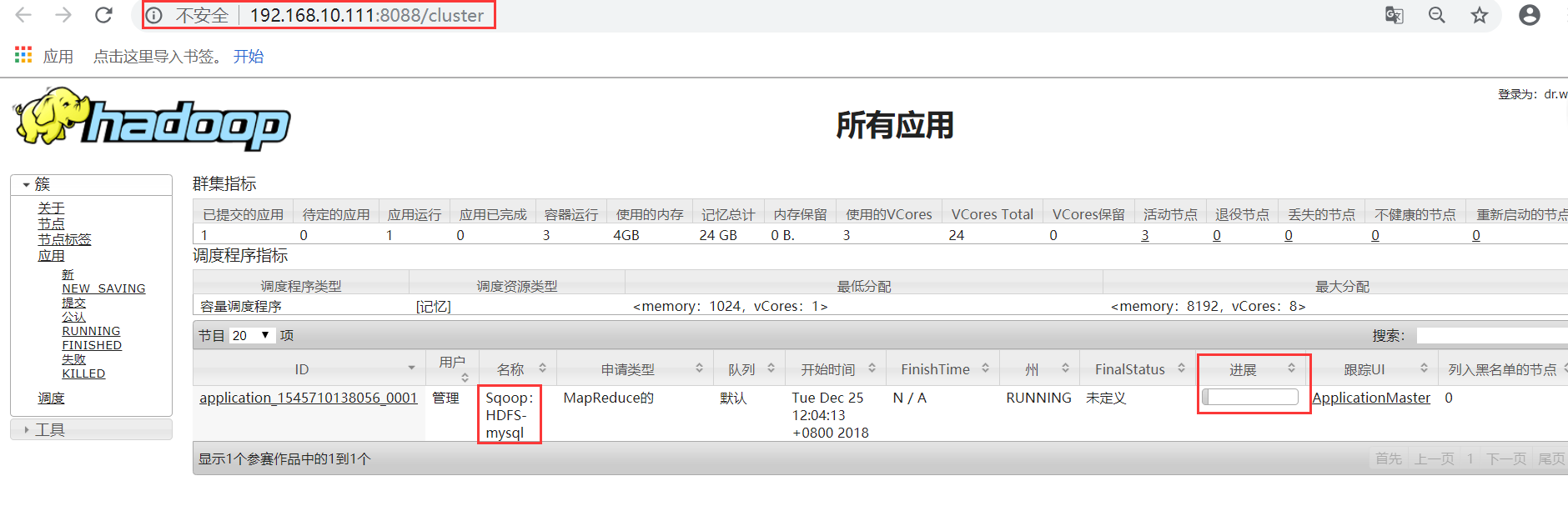
5、在MySQL查询导入的数据;
命令:
# mysql -uroot -pmysqlabc
> show databases;
> use sqoop;
> show tables;
> select*from test001;
最后
以上就是糊涂滑板最近收集整理的关于Hadoop集群的基本操作(五:Sqoop的基本操作)练习内容的全部内容,更多相关Hadoop集群内容请搜索靠谱客的其他文章。








发表评论 取消回复