一、github项目地址:https://github.com/DouglasLee001/wordcountPRO
二、PSP表格
PSP2.1表格
| PSP2.1 | PSP阶段 | 预估耗时 (分钟) | 实际耗时 (分钟) |
| Planning | 计划 | 20 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 5 | 5 |
| Development | 开发 | 30 | 30 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 60 |
| · Design Spec | · 生成设计文档 | 40 | 40 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 20 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 60 | 65 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 5 | 10 |
| · Code Review | · 代码复审 | 10 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 180 | 200 |
| Reporting | 报告 | 40 | 50 |
| · Test Report | · 测试报告 | 40 | 50 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 10 |
| 合计 | 580 | 605 |
三、模块的接口实现说明
1)sort类:
重载comparator()函数,当两个word对象的num值不同的时候,就返回两者的num值比较结果,如果两者的num值相同,就返回两者的中string ::word的比较值
1 class sort implements Comparator { 2 public int compare(Object o1, Object o2) { 3 word s1 = (word) o1; 4 word s2 = (word) o2; 5 if (s1.getNum() > s2.getNum()) 6 return -1; 7 else if(s1.getNum()<s2.getNum()) 8 return 1; 9 else { 10 if(s1.word.compareTo(s2.word)>0) 11 return 1; 12 else 13 return -1; 14 } 15 } 16 }
2)类sortWord:提供将未排序的arrayList<word>数组变成已排序的,返回ArrayList<word>,调用重载了比较算符comparator的sort类
1 public class sortWord { 2 public ArrayList<word> Sortword(ArrayList<word> wordList) { 3 Collections.sort(wordList, new sort()); 4 return wordList; 5 } 6 }
四、测试用例的设计
1)测试方法的考虑:
(1)对于我自身写的两个类,sort与sortWord类,前者是重载了comparator运算符,后者是进行排序,采用白盒测试方法,对不同的路径进行覆盖,需要对当不同的词频时,相同词频不同单词,相同词频不同单词长度的情况进行排序。
(2)对于组员所写的输入方法,进行黑盒测试,根据功能需求,需要考虑当输入正常,输入不为txt文件,输入文件不存在,输入中只有一行空行时的情况进行测试。
(3)对于组员写的单词识别和词频统计方法,采用黑盒测试的方法,根据功能需求,考虑了边界值条件,测试当内容为空,内容为带“-”,常见字符,数字等情况,并进行了等价类划分:
第一,Let’s,这种包含单引号的情况,视为2个单词,即let和s。
第二,night-,带短横线的单词,视为1个单词,即night。
第三,“I,带双引号的单词,视为1个单词,即i。
第四,TABLE1-2,带数字的单词,视为1个单词,即table。
第五,(see Box 3–2).8885d_c01_016,带数字、常用字符和单词的情况,视为4个单词,即see, box, d, c。
2)测试效率的考虑:使用junit框架能够实现快速有效地进行针对性的测试,通过与自己的预期结构进行对比,查漏补缺。
3)测试用例表,具体测试代码详见github中的test文件夹
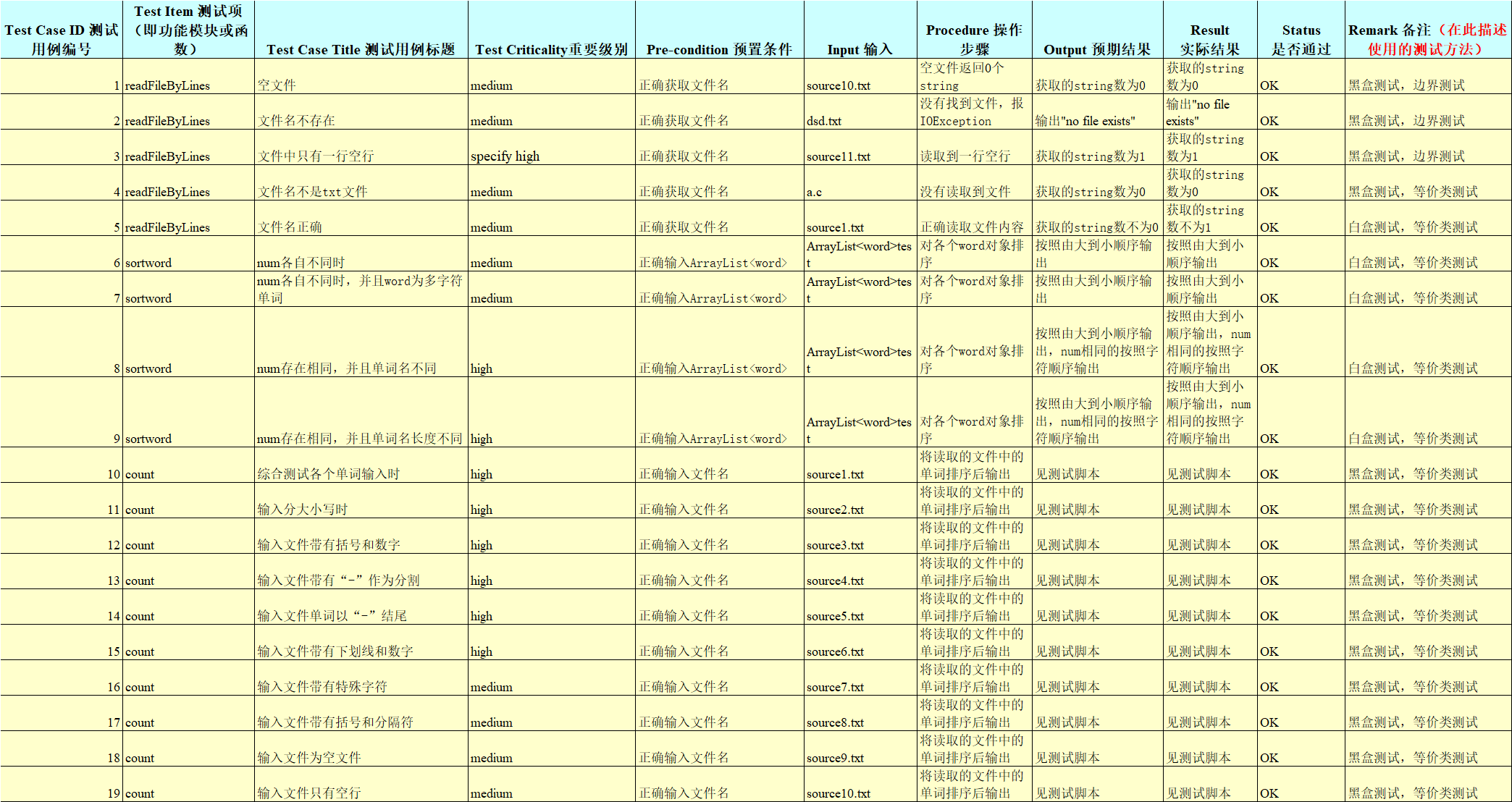
五.Junit测试截图
(1)针对readfileBylines的测试,使用assertEquals进行判断,并判断了抛出异常时的情况。个人认为达到了预期效果。
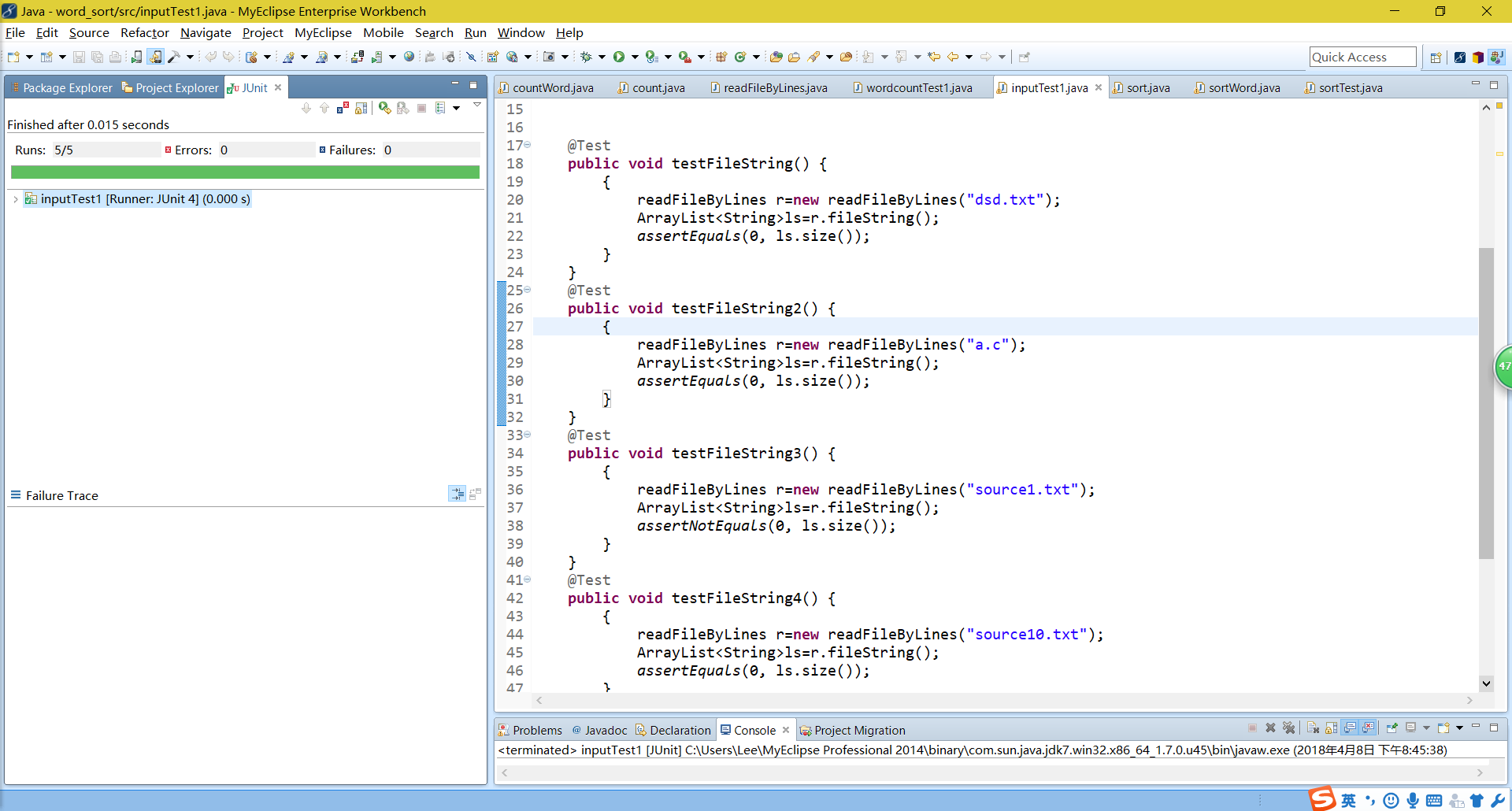
(2)对于sortword函数进行测试,针对num是否重复划分了等价类,进行了白盒测试,由于代码较为简单,测试用例设计了4个,个人认为达到了预期效果
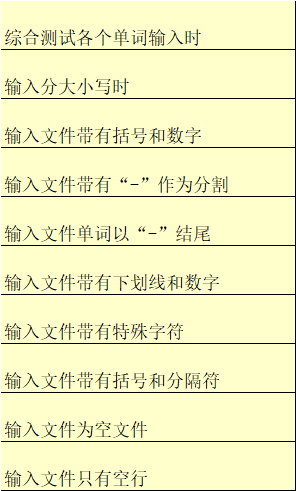
(3)对count函数的测试,由于采用了黑盒测试,因此需要针对不同等价类进行划分,针对需求中的对于单词的定义,设计如下各个等价类,并通过对代码的分析,进行路径覆盖。设计了11个用例,达到了预期目标。
运行结果: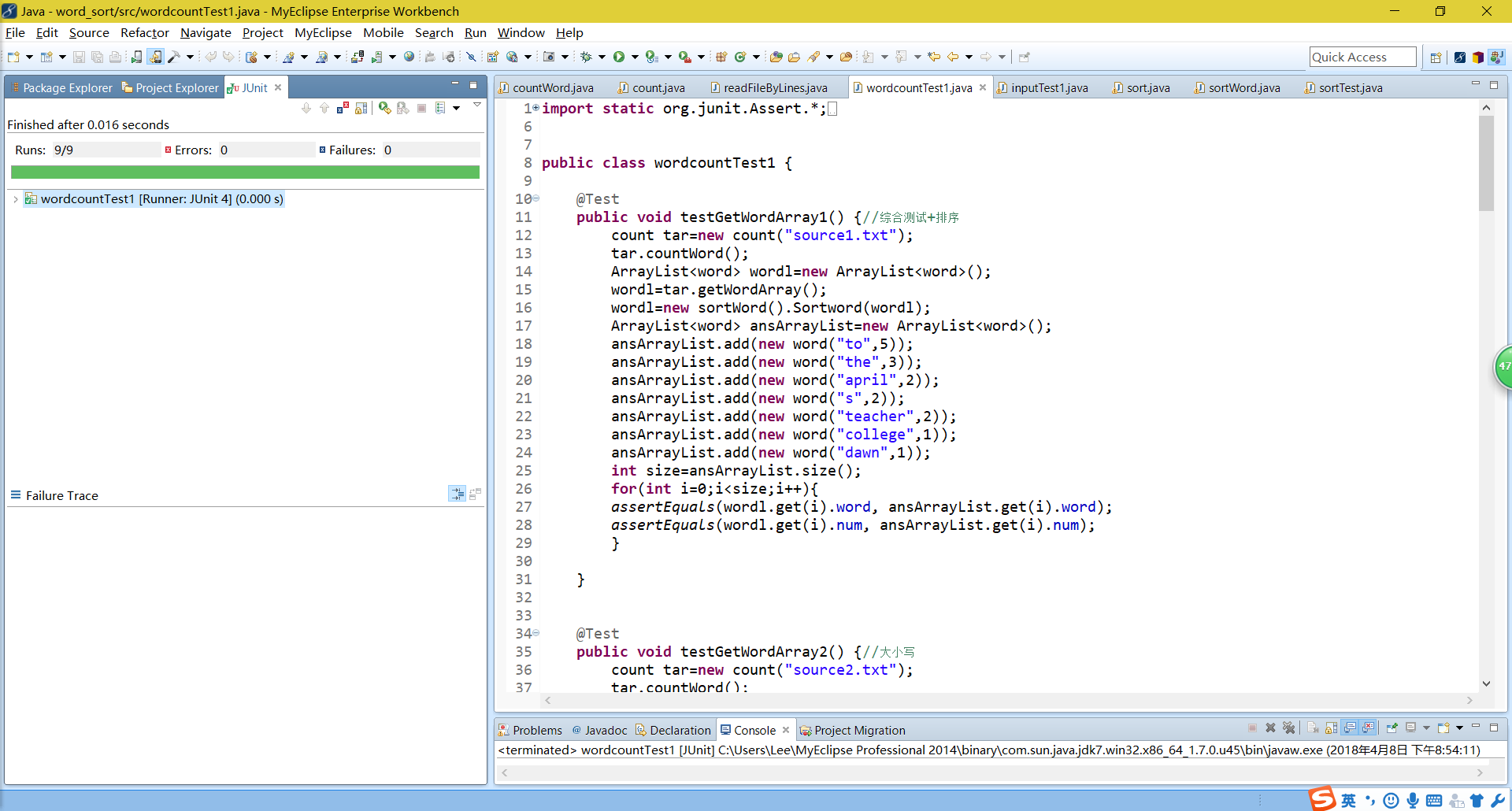
六,小组贡献分:0.25
扩展功能:
一、代码规范参照地址:http://www.cnblogs.com/xinz/archive/2011/11/20/2255971.html(邹欣老师的博客)
1)选择其中的“代码风格规范”,包括了缩进,行宽,括号,断行和空白的{}行,分行,命名,下划线问题,大小写问题,注释。
2)个人认为通过规范代码可以增强代码的可读性和可调试性,方便进行团队成员内部之间进行同行评审,命名规范可以使得各个变量一目了然,清晰地了解各个变量和类的作用,对于类,常用每个单独的单词首字母大写,其余小写,而普通变量则第一个单词首字母小写,其后的单词首字母大写,比如读文件的类ReadFileByLines,统计方法countWord。
二、对组员代码的分析
分析了17034的代码:(部分如下)
import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.IOException; import java.util.ArrayList; public class readFileByLines { public String fileName; public readFileByLines(String theFilename){ this.fileName=theFilename; } public ArrayList<String> fileString(){ File file = new File(fileName); ArrayList<String> lineArray = new ArrayList<String> (); BufferedReader reader =null;{ try { reader = new BufferedReader(new FileReader(file)); String tempString = null; while ((tempString = reader.readLine()) != null) { lineArray.add(tempString); } reader.close(); } catch (IOException e) { //e.printStackTrace(); System.out.println("no file exits"); } finally { if (reader != null) { try { reader.close(); } catch (IOException e1) { } } } } return lineArray; } }
优点:
1)符合命名规范,意义明确。
2)符合大小写问题的规范,清晰明了。
缺点:1)缺少适当注释
2)括号没有对齐
3)大括号没有每个占一行,复杂的条件表达式中,逻辑优先级容易不清晰。
三、静态代码检查工具选择了:阿里巴巴Java开发代码检测IDE插件,参考安装网址:https://www.cnblogs.com/ysgcs/p/7675977.html
四.
静态代码检查过程
1)界面截图:
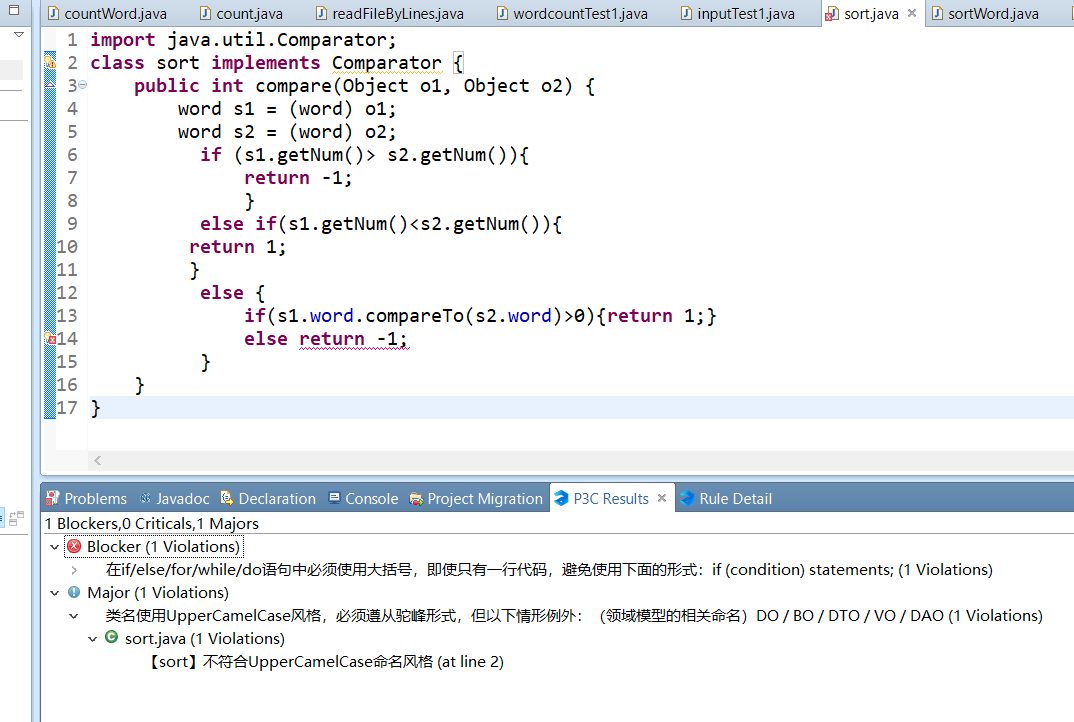
2)代码存在的问题都为一些风格规范问题,对应的具体和解决方法分别是:
对于if/else语句应必须使用大括号,即使只有一行代码
对于命名应该采用驼峰形式,对于sort应写成Sort
五、整个小组代码存在的问题
主要还是代码风格不够规范,注释信息较少导致阅读代码时不方便,因为一开始没有这种习惯,导致后来手动添加比较麻烦;其次是命名规范不够标准,其他常见问题与我自己的代码相似,不在一一列举。
转载于:https://www.cnblogs.com/lee17015/p/8747401.html
最后
以上就是标致日记本最近收集整理的关于第四周小组作业:WordCount优化的全部内容,更多相关第四周小组作业内容请搜索靠谱客的其他文章。








发表评论 取消回复