Ceilometer Alarm是H版新添加的功能,监控报警是云平台不可缺少的部分,Ceilometer已经实现了比较完善的监控体系,报警怎么能缺少呢?用过AWS CloudWatch Alarm的人应该不会对Ceilometer的Alarm感到陌生,Ceilometer实现的Alarm和CloudWatch的Alarm很像,概念基本上都一样,Alarm的逻辑也基本上一样,可以说是一个开源版的CloudWatch Alarm,但是它进行了一些“微创新”,实现了一些比较有意思的小功能,而且代码写的也非常不错,是一个不错的学习素材。
下面我们从功能,实现,以及它目前存在的问题三个方面介绍一下Ceilometer的Alarm。
功能篇
简单来说,Alarm的功能其实很简单,监控某一个或多个指标的值,若高于或者是低于阈值,那么就执行相应的动作,比如发送邮件短信报警,或者是直接调用某个接口进行autoscaling操作,像Heat就是依赖Ceilometer的Alarm实现Auto Scaling的操作。
Ceilometer中,实现了2种alarm:一种是threshold,一种是combination。顾名思义,threshold就是我们熟悉的根据监控指标的阈值去判断alarm的状态,它只是针对某一个监控指标建立alarm,而combination则可以理解为alarm的alarm,它是根据多个alarm的状态来判断自己的状态的,多个alarm之间是or/and的关系,这相当于是对多个监控指标建立了一个alarm。一般情况下,我们只需要threshold类型的alarm就足够了,但是一些特殊情况,比如Heat要执行auto scaling操作,可能就要对多个监控指标进行衡量,然后再采取操作。
下面,我们来分析一下Alarm的API,看它到底提供了哪些不一样的功能:
- POST /v2/alarms
创建一个alarm,详细的参数见下表:
| 参数 | 类型 | 解释 |
|---|---|---|
| name | str | name是project唯一的 |
| description | str | 描述 |
| enabled | bool | alarm的一个开关,可以停止/启动该alarm,默认是True |
| ok_actions | list | 当alarm状态变为ok状态时,采取的动作,默认是[] |
| alarm_actions | list | 当alarm状态变为alarm状态时,采取的动作,默认是[] |
| insufficient_data_actions | list | 当alarm状态变为insufficient data状态时,采取的动作,默认是[] |
| repeat_actions | bool | 当alarm被触发时,是否重复执行对应的动作,默认是False |
| type | str | alarm类型,目前有threshold和combination两种,必填 |
| threshold_rule | AlarmThresholdRule | 当alarm类型为threshold时,制定的threshold规则 |
| combination_rule | AlarmCombinationRule | 当alarm类型为combination时,制定的combination规则 |
| time_constraints | list(AlarmTimeConstraint) | 约束该alarm在哪些时间段执行,默认是[] |
| state | str | alarm的状态,默认是insufficient data |
| user_id | str | user id,默认是context user id |
| project_id | str | project id, 默认是context project id |
| timestamp | datetime | alarm的定义最后一次被更新的时间 |
| state_timestamp | datetime | alarm的状态最后一次更改的时间 |
这里主要说下面几个参数:
- name: name是project唯一的,在创建alarm的时候会检查
- enabled: 这个功能比较人性化,可以暂停该alarm,是微创新之一
- xxx_actions: 定义了在该alarm状态由其他的状态变为xxx状态时,执行的动作
- repeat_actions: 这个参数指定了是否要重复执行action,比如第一次检查alarm已经超过阈值,执行了相应的action了,当下一次检查时如果该alarm还是超过阈值,那么这个参数决定了是否要重复执行相应的action,这也是微创新之一
- threshold_rule: 当type为threshold时,定义的alarm被触发的规则,详细参数见下面AlarmThresholdRule对象属性
- combination_rule: 当type为combination时,定义的alarm被触发的规则,详细参数见下面AlarmCombinationRule对象属性
- time_constraints: 这也是一个很人性化的参数,可以指定该alarm被检查的时间的一个列表,比如说我只想让这个alarm在每天晚上的21点到23点被检查,以及每天中午的11点到13点被检查,其它时间不检查该alarm,这个参数就可以做这个限制,不过该参数设置稍微复杂一点,详细参数见下面AlarmTimeConstraint对象属性,默认是[],即不设限制,随着alarm进程的interval time进行检查。
- state: alarm总共有3个状态:OK, INSUFICIENT DATA, ALARM,这三个状态分别对应到上面的xxx_actions
AlarmThresholdRule:
- meter_name: 监控指标
- query: 该参数一般用于找到监控指标下的某个资源,默认是[]
- period: 这个参数其实有两个作用,一个是确定了获取该监控指标的监控数据的时间范围,和下面的evaluation_periods配合使用,另外一个作用就是它确定了两个点之间的时间间隔,默认是60s
- threshold: 阈值
- comparison_operator: 这个参数确定了怎么和阈值进行比较,有6个可选:lt, le, eq, ne, ge, gt,默认是eq
- statistic: 这个参数确定了使用什么数据去和threshold比较,有5种可选:max, min, avg, sum, count,默认是avg
- evaluation_periods: 和period参数相乘,可以确定获取监控数据的时间范围,默认是1
- exclude_outliners: 这个参数有点意思,我们都知道“标准差”是指一组数据的波动大小,平均值相同,但是标准差小的波动小,这个参数就是指对得到的一组监控数据,是否要根据标准差去除那些波动比较大的数据,以降低误判率,默认是False
AlarmCombinationRule:
- operator: 定义alarms之间的逻辑关系,有两个选项:or 和 and,默认是and,注意这里的逻辑关系ALARM要比OK状态优先级高,比如有2个alarm,一个状态是ALARM,一个状态是OK,他们之间的逻辑关系是or,那么这个combination alarm是啥状态呢?答案是ALARM.
- alarms_id: alarm列表
AlarmTimeConstraint:
- name: name
- description: description
- start: 该参数以cron的格式指定了alarm被检查的开始时间,在程序中,使用croniter这个库来实现cron,格式是:“min hour day month day_of_week”,比如"2 4 mon,fri",意思是在每周一和周五的04:02开始被检查
- duration: 被检查持续的时间,单位是秒
- timezone: 可以为上面的检查时间指定时区,默认使用的是UTC时间
举两个例子:
- threshold
{
"name": "ThresholdAlarm1",
"type": "threshold",
"threshold_rule": {
"comparison_operator": "gt",
"evaluation_periods": 2,
"exclude_outliers": false,
"meter_name": "cpu_util",
"period": 600,
"query": [
{
"field": "resource_id",
"op": "eq",
"type": "string",
"value": "2a4d689b-f0b8-49c1-9eef-87cae58d80db"
}
],
"statistic": "avg",
"threshold": 70.0
},
"alarm_actions": [
"http://site:8000/alarm"
],
"insufficient_data_actions": [
"http://site:8000/nodata"
],
"ok_actions": [
"http://site:8000/ok"
],
"repeat_actions": false,
"time_constraints": [
{
"description": "nightly build every night at 23h for 3 hours",
"duration": 10800,
"name": "SampleConstraint",
"start": "0 23 * * *",
"timezone": "Europe/Ljubljana"
}
]
}
- combination
{
"name": "CombinationAlarm1",
"type": "combination",
"combination_rule": {
"alarm_ids": [
"739e99cb-c2ec-4718-b900-332502355f38",
"153462d0-a9b8-4b5b-8175-9e4b05e9b856"
],
"operator": "or"
},
"alarm_actions": [
"http://site:8000/alarm"
],
"insufficient_data_actions": [
"http://site:8000/nodata"
],
"ok_actions": [
"http://site:8000/ok"
]
}
- GET /v2/alarms/{alarm_id}/history
这个接口用来查询某个alarm发生的历史事件,记录的事件有:alarm被创建,alarm被更新,alarm被删除,alarm的状态被更新。
举个例子,比如我创建了一个alarm,然后又删除了,调用这个接口返回的结果是:
[
{
"on_behalf_of": "2c35166baba84f46b1c5b093f02747fa",
"user_id": "778a4ae5d8904a41b00c4e0f5734bcfd",
"event_id": "dc5583ac-7ac8-4f4e-b8f7-edaa04522945",
"timestamp": "2014-07-26T16:50:59.387923",
"detail": "xxx",
"alarm_id": "697a05df-d704-46a4-a0bd-1591c6588a17",
"project_id": "2c35166baba84f46b1c5b093f02747fa",
"type": "deletion"
},
{
"on_behalf_of": "2c35166baba84f46b1c5b093f02747fa",
"user_id": "778a4ae5d8904a41b00c4e0f5734bcfd",
"event_id": "d09fe2c3-37a8-4b19-9729-ccb2664a1116",
"timestamp": "2014-07-26T16:50:27.315824",
"detail": "xxx",
"alarm_id": "697a05df-d704-46a4-a0bd-1591c6588a17",
"project_id": "2c35166baba84f46b1c5b093f02747fa",
"type": "creation"
}
]
Alarm还有其它一些接口,这里就不说了,更多见alarm-api文档。
实现篇
对于Alarm的实现,值得一说的就是Alarm的分布式实现,也就是文章的标题,Distributed Alarm。Ceilometer提供了两种方式的Alarm服务,一种是单进程的(SingletonAlarmService),一种是分布式的(PartitionedAlarmService),可以通过evaluation_service这个配置项进行配置。
前者没啥可说的,就是在一个进程中去检查所有的alarm,这种方式主要的缺点是处理能力弱,当量稍微大的时候,就会有延时,而且也没法做高可用,当他挂掉之后,alarm整个service就挂掉了,所以不推荐在生产环境中使用这个SingletonAlarmService的方式。
对于PartitionedAlarmService,它通过rpc实现了一套多个evaluator进程之间的协作协议(PartitionCoordinator),使得可以通过水平扩展来不断增大alarm service的处理能力,这样不仅实现了一个简单的负载均衡,还实现了高可用。下面我们就重点来说一下PartitionCoordinator这个协议。
PartitionCoordinator允许启动多个ceilometer-alarm-evaluator进程,这多个进程之间的关系是互相协作的关系,他们中最早启动的进程会被选为master进程,master进程主要做的事情就是给其他进程分配alarm,每个进程都在周期性的执行三个任务:
- 通过rpc,向其它进程广播自己的状态,来告知其他进程,我是活着的,每个进程中都保存有其他进程的最后活跃时间。
- 争抢master,每个进程都会不断的更新自己所维护的其它进程的状态列表,根据这个状态列表,来判断是否应该由自己来当master,判断一个进程是否是master的条件只有一个,那就是看谁启动的早。
- 检查本进程负责的alarm,会去调用ceilometer的api,来获取该alarm的监控指标对应的监控数据,然后进行判断,发送报警等。
进程之间的关系可参看下图:
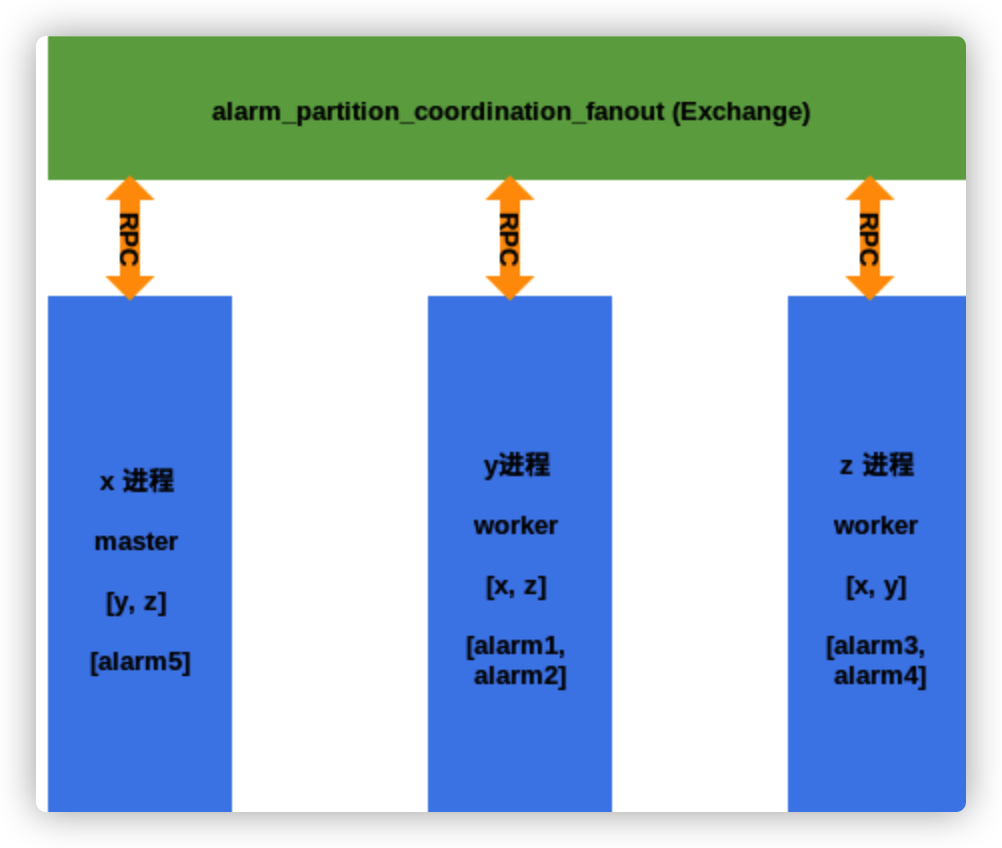
当一个进程被确定为master之后,如果它不挂掉,那么它的master是不会被抢走的,该进程就会一直在履行master的职责:
- 当有新的alarm被创建时,master会将这些新创建的alarm平均的分配给其它worker进程,如果不能平均分配的,剩下的零头就由master自己来负责
- 当有新的evaluator进程添加进来,或者是现有的evaluator进程被kill掉,那么master就会重新洗牌一次,把所有的alarm再平均的分配给现有的evaluator进程
- 当master挂掉咋办呢?那么就会由第二个最早启动的进程接替master的位置,然后重新洗牌
通过这个协议,就实现了一个简单的分布式alarm服务,其中的进程之间的相互协调,master的选举都值得去学习。
问题篇
- 目前有一个比较纠结的问题就是alarm和ceilometer的关系,虽然alarm的代码写在ceilometer的代码树中,其实,他们两个并没有紧密的关系,alarm是ceilometer api的消费者,把他们两个分开也是完全可以的,之前,在邮件列表中对这个问题有过讨论,感兴趣的可以自己搜索一下。
- 目前alarm是ceilometer api的消费者,每个alarm被检查的时间间隔是60s,当alarm数量很多的时候,会给api造成比较大的压力,所以有人提议让alarm直接访问数据库[bp],但是由于上面的问题没有解决,这个问题也不好解决。
- 目前,有的使用ceilometer作为billing服务,但是alarm和billing使用的同一个数据库,这无形中有了一些安全隐患,而且alarm和billing这两个对数据的时效性要求还不一样,alarm可能只需要最近一段时间的数据,而billing则要求数据保持较长的时间,所以这导致db-ttl也比较难做。可以参看这篇博文,相关改进BP。
- 目前,alarm还没有quota限制,比较尴尬诶。
总结篇
本文从三个方面大概描述了一下Ceilometer Alarm功能,功能篇主要从API入手,介绍Alarm都提供了哪些细枝末节的参数,实现篇主要描述了分布式Alarm协议的原理,很值得学习,问题篇其实没什么大问题,现在的alarm功能还是比较稳定的。
相关链接
- https://review.openstack.org/#/c/89756/
- https://review.openstack.org/#/c/95418/
- https://etherpad.openstack.org/p/ceilometer-alarm-and-log-improvments
- https://wiki.openstack.org/w/images/c/ca/Alarm_structure.gif
- https://blueprints.launchpad.net/ceilometer/+spec/dedicated-alarm-database
- https://blueprints.launchpad.net/ceilometer/+spec/alarm-on-notification
- https://blueprints.launchpad.net/ceilometer/+spec/quotas-on-alarms
- https://blueprints.launchpad.net/ceilometer/+spec/alarming-logical-combination
- http://techs.enovance.com/5991/autoscaling-with-heat-and-ceilometer
最后
以上就是善良帆布鞋最近收集整理的关于openstack: Ceilometer Alarm API 参数详解的全部内容,更多相关openstack:内容请搜索靠谱客的其他文章。








发表评论 取消回复