《python自然语言处理》读书笔记
参考书目:《python自然语言处理》
使用的工具:python, NLTK
Ch1
- 安装nltk
python3 -m pip install nltk - 错误:运行时错误、语法错误
- bigram
Ch2 语料
- 各种语料库
- 词汇列表
- wordnet是基于语义的库。比如用树状结构表现同义词
Ch3 加工原文本
- 爬虫:访问网络资源
from urllib import urlopen
raw = urlopen(url = 'http://www.gutenberg.org/files/2554/2554.txt', proxies = {'http': 'http://www.someproxy.com:3128'}).read()
- BeautifulSoup处理html
- feedparser 处理RSS
- 字符串的处理
- 编码,处理unicode,用四位十六进制数
uXXXX表示 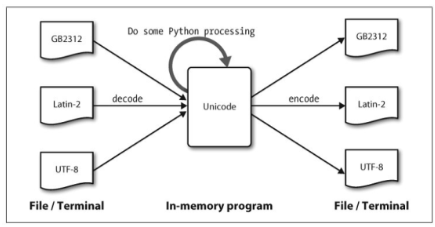
Ch4 编程
- [] 产生器表达式
- 变量范围:LGB 规则:本地 (l ocal),全局(gl obal),然后内置(bui lt-in)。
- docstring
- lambda表达式
- for … yield
- 调试
import pdb - 算法:迭代、动态规划、。例子,梵文音节组成:
-
- virahanka2()所采取的办法是解决较大问题前先解决较小的问题。因此,这 被称为自下而上的方法进行动态规划。
-
- 第三个方法中:
-
- 采用自上而下的方法进行动态规划可 避免计算的浪费。
-
- m 在整个递归过程中,是同一个静态字典,所以不用作为参数传递(?)。
# 迭代
def virahanka1(n):
if n == 0:
return ['']
elif n == 1:
return ['S']
s = ['S' + prosody for prosody in virahanka1(n-1)]
l = ['L' + prosody for prosody in virahanka1(n-2)]
return s + l
# 自底向上的动态规划
def virahanka2(n):
m = [[''], ['S']]
for i in range(2, n+1):
s = ['S' + prosody for prosody in m[i-1]]
l = ['L' + prosody for prosody in m[i-2]]
m.append(s+l)
return m[n]
# 自上向下的动态规划
def virahanka3(n, m = {0: [''], 1: ['S']}):
if n not in m:
s = ['S' + prosody for prosody in virahanka3(n-1)]
l = ['L' + prosody for prosody in virahanka3(n-2)]
m[n] = s + l
print(n,m)
return m[n]
# 内置默记法
# use nltk.momorize
-
- 输出结果
print(virahanka1(4))
print(virahanka2(4))
print(virahanka3(4))
# all of these print: ['SSSS', 'SSL', 'SLS', 'LSS', 'LL']
- python 库:matplotlib (draw plot and graph), networkx (draw network with nodes and edges), csv, numpy
Ch5 分类和标注词汇
- 词性分类:part-of-speech (POS)
- 字典也叫映射(map)、哈希表(hashmap)、哈希(hash)、关联数组(associative array)。
- 标注器:默认标注、正则表达式标注、查询标注、n-gram(有上下文)、组合、
- 存储:
from cPickle import load - 如何确定一个词的分类:形态学、句法、新词、
Ch6 分类文本
- 有监督分类:
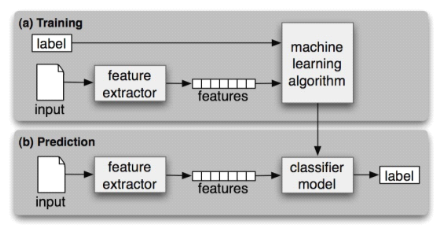
- 用错误分析来完善特征集:
- 评价:precision, recall, f-measure, 混淆矩阵,交叉验证
- 分类模型:决策树、naive bayesian、
Ch7 从文本中提取信息
- 关系识别
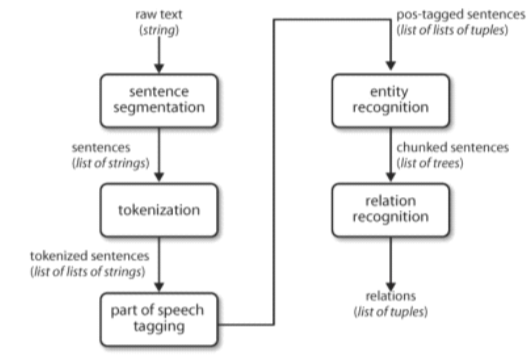
- chunk, chink
- IOB标记:begin, inside, outside
Ch8 分析句子结构
Ch9
Ch10
Ch11
最后
以上就是奋斗帽子最近收集整理的关于【python自然语言处理】读书笔记《python自然语言处理》读书笔记的全部内容,更多相关【python自然语言处理】读书笔记《python自然语言处理》读书笔记内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复