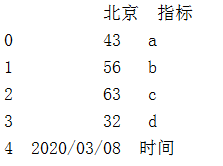
1.pandas从Excel中读取数据并且在第一行插入数据
import pandas as pd
import numpy as np
test = pd.DataFrame({'C1':['a','b','c','d'],'C2':[43,56,63,32]})
print(test)
#修改一下列名将列名修改为'指标','北京'
test.columns = ['指标','北京']
#test = test.rename({'C1':'指标','C2':'北京'})
#在数据的第一行插入数据,['时间','2020/03/08']
datetimes = pd.DataFrame({'指标':'时间','北京':'2020/03/08'},index=[0])
print(datetimes)
#将该行数据加入到test数据集中
test = test.append(datetimes,ignore_index=True)
print(test)
#将最后一行的数据移动到第一行
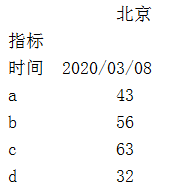
test = test.iloc[np.arange(-1,len(test)-1)]
#将指标设置成索引
test = test.set_index(['指标'])
print(test)


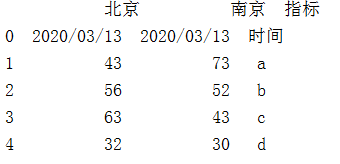
2.pandas 中实现Excel粘贴中的转置功能
test1 = pd.DataFrame({'指标':['时间','a','b','c','d'],'北京':['2020/03/13',43,56,63,32],'南京':['2020/03/13',73,52,43,30]})
print(test1)
#对其进行转置
test1 = test1.T
#test1 = test1.transpose()
print(test1)
#但是当将此结果保存为Excel时会丢失索引名称
test1 = test1.reset_index()
test1 = test1.rename(columns = {'index':'城市'})
test1.to_excel(r'C:tt.xlsx',index=False)

![]()

3.pandas中环比计算 解决分母为0的情况:
从Excel中读取两列数据就算环比时出现分母为0的情况,当分母为0计算报错,当分母为0时,分子为0或不为0两种情况,当计算时当分母为0分子为0或者不为0但是输出结果都为0,计算过程相当于Excel中的iferror函数
data = pd.read_excel(r'c:test.xlsx')
print(data)
#在最后一列加入环比值
data['环比']=(data.iloc[1:,-1]-data.iloc[1:,-2])/(data.iloc[1:,-2].apply(lambda x:math.pow(10,10) if x==0 else x))
data.to_excel(r'c:data.xlsx')计算天津市环比值
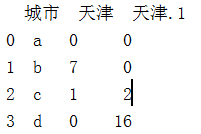

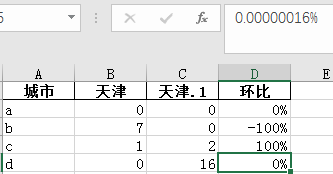
当分母为0,分子不为0时将分母无限扩大,计算结果百分比显示保留整数(也可以保留2-3为小数不影响显示结果),计算出来的结果虽然不是100%精确,但显示结果为目标值(代表个人观点和解决方法如有其它更加准确的方法欢迎补充)
最后
以上就是时尚西装最近收集整理的关于pandas 和Excel交互中 相关总结的全部内容,更多相关pandas内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复