数据集下载地址
包含2000条文本数据,每条文本对应一个情感分类,共有6种情感 love,sadness,fear, surprise, anger, joy。
%pip install nltk
Collecting nltk
Using cached nltk-3.7-py3-none-any.whl (1.5 MB)
Collecting regex>=2021.8.3
Using cached regex-2022.7.9-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (763 kB)
Requirement already satisfied: click in /opt/conda/lib/python3.9/site-packages (from nltk) (8.1.2)
Requirement already satisfied: joblib in /opt/conda/lib/python3.9/site-packages (from nltk) (1.1.0)
Requirement already satisfied: tqdm in /opt/conda/lib/python3.9/site-packages (from nltk) (4.63.1)
Installing collected packages: regex, nltk
Successfully installed nltk-3.7 regex-2022.7.9
[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv[0m[33m
[0mNote: you may need to restart the kernel to use updated packages.
import requests
from tqdm import tqdm
import numpy as np
import nltk
样本总数目: 20000
加载数据集
加载数据方式看个人需求,最后构建成句子列表和标签列表即可,且注意句子和标签顺序相呼应
all_sentences, all_label = [], []
for i in tqdm(range(0, NumberOfSamples, 100)):
res = requests.get('***************',headers=HEADERS)
for data in res.json()["content"]:
all_sentences.append(data["data"]["text"])
all_label.append(data["annotations"][0]["dataAnnos"]["label"])
100%|██████████| 200/200 [04:46<00:00, 1.43s/it]
构造DataFrame 方便统计
import pandas as pd
df = pd.DataFrame(list(zip(all_sentences, all_label)), columns = ['sentence', 'label'])
df.head(10)
| sentence | label | |
|---|---|---|
| 0 | i didnt feel humiliated | sadness |
| 1 | i can go from feeling so hopeless to so damned... | sadness |
| 2 | im grabbing a minute to post i feel greedy wrong | anger |
| 3 | i am ever feeling nostalgic about the fireplac... | love |
| 4 | i am feeling grouchy | anger |
| 5 | ive been feeling a little burdened lately wasn... | sadness |
| 6 | ive been taking or milligrams or times recomme... | surprise |
| 7 | i feel as confused about life as a teenager or... | fear |
| 8 | i have been with petronas for years i feel tha... | joy |
| 9 | i feel romantic too | love |
print(df.shape)
print(df.isnull().sum()) # 检查空值
(20000, 2)
sentence 0
label 0
dtype: int64
文本处理, 去除一些无用字符
import re
import string
"""
移除网址,$数字$, 数字, 标点符号
"""
def remove_hyperlinks(text):
sentence = re.sub(r'www?://.*[rn]*', '', text)
sentence = re.sub(r'http?://.*[rn]*', '', sentence)
return re.sub(r'https?://.*[rn]*', '', sentence)
def remove_currencies(text):
return re.sub(r'[$d+d+$]', '', text)
def remove_number(text):
return re.sub(r'd+', '', text)
def remove_punctuation(text):
return ''.join([word for word in text if word not in string.punctuation])
df['sentence'] = df['sentence'].apply(lambda x: remove_hyperlinks(x.lower()))
df['sentence'] = df['sentence'].apply(lambda x: remove_currencies(x))
df['sentence'] = df['sentence'].apply(lambda x: remove_number(x))
df.head(10)
| sentence | label | |
|---|---|---|
| 0 | i didnt feel humiliated | sadness |
| 1 | i can go from feeling so hopeless to so damned... | sadness |
| 2 | im grabbing a minute to post i feel greedy wrong | anger |
| 3 | i am ever feeling nostalgic about the fireplac... | love |
| 4 | i am feeling grouchy | anger |
| 5 | ive been feeling a little burdened lately wasn... | sadness |
| 6 | ive been taking or milligrams or times recomme... | surprise |
| 7 | i feel as confused about life as a teenager or... | fear |
| 8 | i have been with petronas for years i feel tha... | joy |
| 9 | i feel romantic too | love |
# 根据空格获取单词
def tokenize(text):
return re.split(r'W+', text) # 大写W 除数字字母下划线之外的字符, 在这里主要是空格
df['sentence'] = df['sentence'].apply(lambda x: remove_punctuation(x))
df['sentence'] = df['sentence'].apply(lambda x: tokenize(x))
df.head(10)
| sentence | label | |
|---|---|---|
| 0 | [i, didnt, feel, humiliated] | sadness |
| 1 | [i, can, go, from, feeling, so, hopeless, to, ... | sadness |
| 2 | [im, grabbing, a, minute, to, post, i, feel, g... | anger |
| 3 | [i, am, ever, feeling, nostalgic, about, the, ... | love |
| 4 | [i, am, feeling, grouchy] | anger |
| 5 | [ive, been, feeling, a, little, burdened, late... | sadness |
| 6 | [ive, been, taking, or, milligrams, or, times,... | surprise |
| 7 | [i, feel, as, confused, about, life, as, a, te... | fear |
| 8 | [i, have, been, with, petronas, for, years, i,... | joy |
| 9 | [i, feel, romantic, too] | love |
去除停用词
from nltk.corpus import stopwords
nltk.download('stopwords')
stopword = stopwords.words('english')
def remove_stopword(text):
return [word for word in text if word not in stopword]
df['sentence'] = df['sentence'].apply(lambda x: remove_stopword(x))
df.head(10)
[nltk_data] Downloading package stopwords to /home/jovyan/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
| sentence | label | |
|---|---|---|
| 0 | [didnt, feel, humiliated] | sadness |
| 1 | [go, feeling, hopeless, damned, hopeful, aroun... | sadness |
| 2 | [im, grabbing, minute, post, feel, greedy, wrong] | anger |
| 3 | [ever, feeling, nostalgic, fireplace, know, st... | love |
| 4 | [feeling, grouchy] | anger |
| 5 | [ive, feeling, little, burdened, lately, wasnt... | sadness |
| 6 | [ive, taking, milligrams, times, recommended, ... | surprise |
| 7 | [feel, confused, life, teenager, jaded, year, ... | fear |
| 8 | [petronas, years, feel, petronas, performed, w... | joy |
| 9 | [feel, romantic] | love |
from nltk.stem import WordNetLemmatizer
nltk.download('wordnet')
nltk.download('omw-1.4')
# 把一些名词的词性还原 如 cars-->car
lemmatizer = WordNetLemmatizer()
def lemmatize(text):
return ' '.join([lemmatizer.lemmatize(word) for word in text])
df['sentence'] = df['sentence'].apply(lambda x: lemmatize(x))
df.head(10)
[nltk_data] Downloading package wordnet to /home/jovyan/nltk_data...
[nltk_data] Package wordnet is already up-to-date!
[nltk_data] Downloading package omw-1.4 to /home/jovyan/nltk_data...
[nltk_data] Package omw-1.4 is already up-to-date!
| sentence | label | |
|---|---|---|
| 0 | didnt feel humiliated | sadness |
| 1 | go feeling hopeless damned hopeful around some... | sadness |
| 2 | im grabbing minute post feel greedy wrong | anger |
| 3 | ever feeling nostalgic fireplace know still pr... | love |
| 4 | feeling grouchy | anger |
| 5 | ive feeling little burdened lately wasnt sure | sadness |
| 6 | ive taking milligram time recommended amount i... | surprise |
| 7 | feel confused life teenager jaded year old man | fear |
| 8 | petronas year feel petronas performed well mad... | joy |
| 9 | feel romantic | love |
# 获取类别
category = df["label"].unique().tolist()
建立单词字典
sentence = df['sentence'].values
label = df["label"].apply(lambda x: category.index(x)).values
# 获取所有不重复的单词
words = [word.lower() for s in sentence for word in s.split(" ")]
various_words = list(set(words))
int2word = dict(enumerate(various_words)) # 索引到单词
word2int = {w:int(i) for i,w in int2word.items()} # 单词到索引
from collections import Counter
Counter(label)
Counter({0: 5797, 1: 2709, 2: 1641, 3: 719, 4: 2373, 5: 6761})
清理文本过长或过短的句子
sentence_length = [len(s.split()) for s in sentence] # 每个句子单词的个数
counts = dict(Counter(sentence_length))
import matplotlib.pyplot as plt
plt.figure(figsize=(16,5))
plt.bar(counts.keys(),counts.values())
plt.xlabel("sentence_length")
plt.ylabel("num")
plt.show()
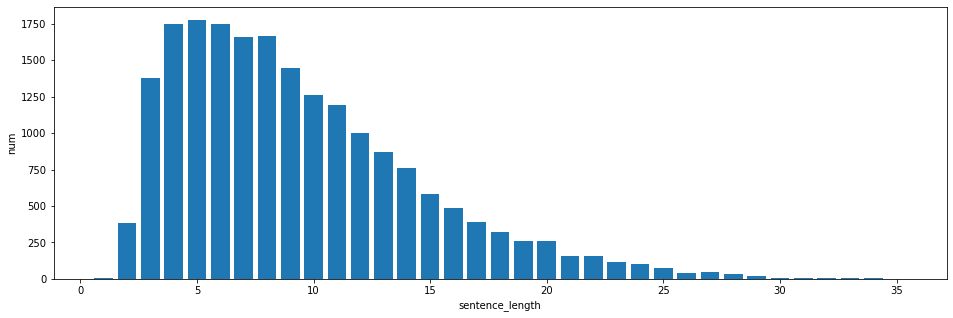
min_sen = min(counts.items())
max_sen = max(counts.items())
print("min:{}, max:{}".format(min_sen,max_sen))
min:(1, 8), max:(35, 2)
"""
获取最小和最大长度的句子的索引
"""
min_index = [i for i,length in enumerate(sentence_length) if length==min_sen[0]]
max_index = [i for i,length in enumerate(sentence_length) if length==max_sen[0]]
new_text = np.delete(sentence, min_index)
new_text2 = np.delete(new_text, max_index)
print("原始文本数量:",len(new_text))
print("新文本数量: ", len(new_text2))
原始文本数量: 19992
新文本数量: 19990
new_labels = np.delete(label, min_index)
new_labels = np.delete(new_labels, max_index)
print("原始标签数量:",len(new_text))
print("新标签数量: ", len(new_text2))
原始标签数量: 19992
新标签数量: 19990
将句子根据单词字典映射成数字
text2ints = []
for sentence in new_text2:
sample = list()
for word in sentence.split():
int_value = word2int[word]
sample.append(int_value)
text2ints.append(sample)
text2ints[:5]
[[776, 2470, 276],
[2272, 11006, 8438, 4651, 3985, 4269, 8191, 7923, 2237],
[10985, 14024, 775, 12813, 2470, 11920, 11414],
[1906, 11006, 12544, 9257, 7443, 5937, 11229],
[11006, 11453]]
数据的填充或者截断
def reset_text(text, seq_len):
dataset = np.zeros((len(text),seq_len))
for index,sentence in enumerate(text):
if len(sentence) < seq_len:
dataset[index, :len(sentence)] = sentence # 后面填充0
else:
dataset[index, :] = sentence[:seq_len] # 截断
return dataset
dataset = reset_text(text2ints, seq_len=22)
dataset
array([[ 776., 2470., 276., ..., 0., 0., 0.],
[ 2272., 11006., 8438., ..., 0., 0., 0.],
[10985., 14024., 775., ..., 0., 0., 0.],
...,
[ 2470., 782., 14928., ..., 0., 0., 0.],
[10985., 11006., 3284., ..., 0., 0., 0.],
[ 2470., 13911., 7535., ..., 0., 0., 0.]])
import torch
import torch.nn as nn
## 转化为张量
dataset_tensor = torch.from_numpy(dataset)
label_tensor = torch.from_numpy(new_labels)
print(type(dataset_tensor), type(label_tensor))
<class 'torch.Tensor'> <class 'torch.Tensor'>
划分数据集
all_samples = len(dataset_tensor)
train_ratio = 0.8
val_ratio = 0.2
train = dataset_tensor[:int(train_ratio*all_samples)]
train_labels = label_tensor[:int(train_ratio*all_samples)]
val = dataset_tensor[int(train_ratio*all_samples):]
val_labels = label_tensor[int(train_ratio*all_samples):]
print("训练集:{}----{}".format(train.shape, train_labels.shape))
print("验证集:{}----{}".format(val.shape,val_labels.shape))
训练集:torch.Size([15992, 22])----torch.Size([15992])
验证集:torch.Size([3998, 22])----torch.Size([3998])
封装dataloader
from torch.utils.data import TensorDataset, DataLoader
train_dataset = TensorDataset(train, train_labels)
val_dataset = TensorDataset(val, val_labels)
batch_size = 128
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=8, pin_memory=True, drop_last=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=8, pin_memory=True, drop_last=True)
device = "cuda" if torch.cuda.is_available() else "cpu"
print(device)
cpu
定义网络模型
class SentimentNet(nn.Module):
def __init__(self, input_size, embedding_dim, hidden_dim, output_size, num_layers, dropout=0.5):
super(SentimentNet, self).__init__()
self.hidden_dim = hidden_dim
self.output_size = output_size
self.num_layers = num_layers
self.embedding= nn.Embedding(input_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers, dropout=dropout,batch_first=True)
self.linear = nn.Linear(hidden_dim, 128)
self.relu = nn.ReLU()
self.linear2 = nn.Linear(128, output_size)
self.dropout = nn.Dropout(p=0.4)
def forward(self, x, hidden):
"""
x: (128,10)
"""
batch_size = x.size(0)
x = x.long()
embeds = self.embedding(x) # embeds(128,10,200)
# out(128,22,128)--batch_size,seq_len, hidden_size
# hidden是个元组{h_n,c_n}每个都是(2, 128,128) -- num_layer,batch_size, hidden_size
out,hidden = self.lstm(embeds, hidden)
out = self.linear(out[:, -1, :]) # out(128,128)
out = self.dropout(out)
out = self.relu(out)
out = self.linear2(out) # out(128, 6)
return out, hidden # hidden (h_n, c_n)
def init_hidden(self, batch_size):
weight = next(self.parameters())
# h_0, c_0
return (weight.new_zeros(self.num_layers, batch_size, self.hidden_dim),
weight.new_zeros(self.num_layers, batch_size, self.hidden_dim))
input_size = len(word2int)
output_size = len(category)
embedding_dim = 200
hidden_dim= 128
num_layers= 2
model = SentimentNet(input_size, embedding_dim, hidden_dim, output_size, num_layers)
model.to(device)
SentimentNet(
(embedding): Embedding(15104, 200)
(lstm): LSTM(200, 128, num_layers=2, batch_first=True, dropout=0.5)
(linear): Linear(in_features=128, out_features=128, bias=True)
(relu): ReLU()
(linear2): Linear(in_features=128, out_features=6, bias=True)
(dropout): Dropout(p=0.4, inplace=False)
)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.RMSprop(model.parameters(), lr=1e-3)
# Decay LR by a factor of 0.1 every 3 epochs
exp_lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
模型训练
def train(model, data_loader, criterion, optimizer, scheduler, num_epochs):
train_process = dict()
train_loss_epoch10, val_loss_epoch10= [],[]
val_acc_epoch10 = []
for epoch in range(num_epochs):
hs = model.init_hidden(batch_size)
train_loss = []
train_correct = 0
model.train()
for data, target in data_loader:
data = data.to(device)
target = target.to(device)
output,hs = model(data, hs)
preds = torch.argmax(output, dim=1)
train_correct += torch.sum(preds==target)
hs = tuple([h.data for h in hs])
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss.append(loss.item())
print(f"Epoch [{epoch}/{num_epochs-1}]---train loss {np.mean(train_loss):>.5f}")
scheduler.step()
if epoch % 10 == 0:
validation_loss, validation_acc = validation(model, val_loader, criterion)
train_loss_epoch10.append(np.mean(train_loss))
val_loss_epoch10.append(validation_loss)
val_acc_epoch10.append(validation_acc)
train_process["train_loss"] = train_loss_epoch10
train_process["val_loss"] = val_loss_epoch10
train_process["val_acc"] = val_acc_epoch10
return train_process
def validation(model, val_loader, criterion):
model.eval()
hs = model.init_hidden(batch_size)
val_loss = []
val_correct = 0
with torch.no_grad():
for data, target in val_loader:
data = data.to(device)
target = target.to(device)
outs,hs = model(data,hs)
hs = tuple([h.data for h in hs])
loss = criterion(outs, target)
preds = torch.argmax(outs, dim=1)
val_loss.append(loss.item())
val_correct += torch.sum(preds==target)
print(f"--------------------------------validation loss is: {np.mean(val_loss):>.5f}, acc is: {100*val_correct/len(val_loader.dataset):>.2f}%")
return np.mean(val_loss), val_correct/len(val_loader.dataset)
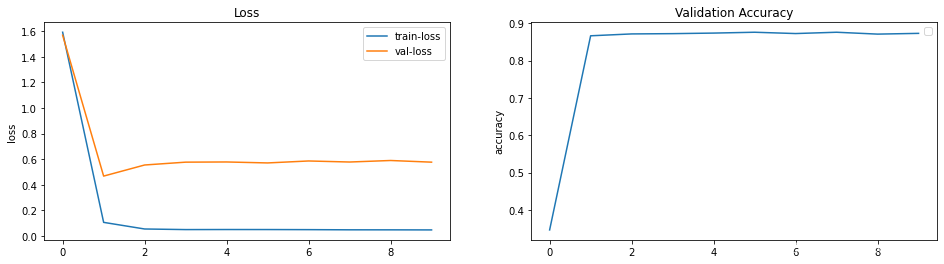
train_process = train(model, train_loader, criterion, optimizer,exp_lr_scheduler, num_epochs=100)
Epoch [0/99]---train loss 1.59277
--------------------------------validation loss is: 1.56931, acc is: 34.67%
Epoch [1/99]---train loss 1.58079
Epoch [2/99]---train loss 1.47616
Epoch [3/99]---train loss 1.16114
Epoch [4/99]---train loss 1.00649
Epoch [5/99]---train loss 0.79341
Epoch [6/99]---train loss 0.61482
Epoch [7/99]---train loss 0.37631
Epoch [8/99]---train loss 0.22457
Epoch [9/99]---train loss 0.15812
Epoch [10/99]---train loss 0.10514
--------------------------------validation loss is: 0.46727, acc is: 86.64%
Epoch [11/99]---train loss 0.09292
Epoch [12/99]---train loss 0.08403
Epoch [13/99]---train loss 0.07773
Epoch [14/99]---train loss 0.07114
Epoch [15/99]---train loss 0.07018
Epoch [16/99]---train loss 0.06568
Epoch [17/99]---train loss 0.06244
Epoch [18/99]---train loss 0.06041
Epoch [19/99]---train loss 0.05722
Epoch [20/99]---train loss 0.05333
--------------------------------validation loss is: 0.55406, acc is: 87.14%
Epoch [21/99]---train loss 0.04836
Epoch [22/99]---train loss 0.04972
Epoch [23/99]---train loss 0.04870
Epoch [24/99]---train loss 0.05047
Epoch [25/99]---train loss 0.04990
Epoch [26/99]---train loss 0.05206
Epoch [27/99]---train loss 0.04928
Epoch [28/99]---train loss 0.04778
Epoch [29/99]---train loss 0.04771
Epoch [30/99]---train loss 0.04868
--------------------------------validation loss is: 0.57627, acc is: 87.22%
Epoch [31/99]---train loss 0.04743
Epoch [32/99]---train loss 0.04727
Epoch [33/99]---train loss 0.04861
Epoch [34/99]---train loss 0.04523
Epoch [35/99]---train loss 0.04876
Epoch [36/99]---train loss 0.04664
Epoch [37/99]---train loss 0.04642
Epoch [38/99]---train loss 0.04934
Epoch [39/99]---train loss 0.04657
Epoch [40/99]---train loss 0.04912
--------------------------------validation loss is: 0.57772, acc is: 87.37%
Epoch [41/99]---train loss 0.05022
Epoch [42/99]---train loss 0.04639
Epoch [43/99]---train loss 0.04854
Epoch [44/99]---train loss 0.04836
Epoch [45/99]---train loss 0.04772
Epoch [46/99]---train loss 0.04839
Epoch [47/99]---train loss 0.04706
Epoch [48/99]---train loss 0.04579
Epoch [49/99]---train loss 0.04788
Epoch [50/99]---train loss 0.04893
--------------------------------validation loss is: 0.57018, acc is: 87.59%
Epoch [51/99]---train loss 0.04846
Epoch [52/99]---train loss 0.04869
Epoch [53/99]---train loss 0.04680
Epoch [54/99]---train loss 0.04806
Epoch [55/99]---train loss 0.04735
Epoch [56/99]---train loss 0.04469
Epoch [57/99]---train loss 0.04781
Epoch [58/99]---train loss 0.04836
Epoch [59/99]---train loss 0.04770
Epoch [60/99]---train loss 0.04822
--------------------------------validation loss is: 0.58553, acc is: 87.24%
Epoch [61/99]---train loss 0.04633
Epoch [62/99]---train loss 0.05106
Epoch [63/99]---train loss 0.04976
Epoch [64/99]---train loss 0.04692
Epoch [65/99]---train loss 0.04643
Epoch [66/99]---train loss 0.05045
Epoch [67/99]---train loss 0.04795
Epoch [68/99]---train loss 0.04573
Epoch [69/99]---train loss 0.05088
Epoch [70/99]---train loss 0.04687
--------------------------------validation loss is: 0.57736, acc is: 87.59%
Epoch [71/99]---train loss 0.04938
Epoch [72/99]---train loss 0.05052
Epoch [73/99]---train loss 0.04557
Epoch [74/99]---train loss 0.04864
Epoch [75/99]---train loss 0.05058
Epoch [76/99]---train loss 0.04869
Epoch [77/99]---train loss 0.04648
Epoch [78/99]---train loss 0.04884
Epoch [79/99]---train loss 0.04855
Epoch [80/99]---train loss 0.04667
--------------------------------validation loss is: 0.58926, acc is: 87.09%
Epoch [81/99]---train loss 0.04856
Epoch [82/99]---train loss 0.04642
Epoch [83/99]---train loss 0.04517
Epoch [84/99]---train loss 0.04651
Epoch [85/99]---train loss 0.04770
Epoch [86/99]---train loss 0.04673
Epoch [87/99]---train loss 0.04621
Epoch [88/99]---train loss 0.04786
Epoch [89/99]---train loss 0.04591
Epoch [90/99]---train loss 0.04608
--------------------------------validation loss is: 0.57623, acc is: 87.29%
Epoch [91/99]---train loss 0.04993
Epoch [92/99]---train loss 0.04699
Epoch [93/99]---train loss 0.04799
Epoch [94/99]---train loss 0.04821
Epoch [95/99]---train loss 0.04724
Epoch [96/99]---train loss 0.04790
Epoch [97/99]---train loss 0.04842
Epoch [98/99]---train loss 0.04961
Epoch [99/99]---train loss 0.04863
训练损失可视化
import matplotlib.pyplot as plt
plt.figure(figsize=(16,4))
plt.subplot(1,2,1)
plt.title("Loss")
plt.ylabel("loss")
plt.plot(train_process["train_loss"],label="train-loss")
plt.plot(train_process["val_loss"],label="val-loss")
plt.legend()
plt.subplot(1,2,2)
plt.legend(labels=[""])
plt.ylabel("accuracy")
plt.title("Validation Accuracy")
plt.plot(train_process["val_acc"])
plt.show()
预测
from string import punctuation
texts = ["i wont let me child cry it out because i feel that loving her and lily when she was little was going to be opportunities that only lasted for those short few months",
"i feel there are dangerous games or activities",
"i feel dirty and ashamed for saying that"
]
def converts(text):
text = remove_hyperlinks(text)
text = remove_currencies(text)
text = remove_number(text)
new_text = remove_punctuation(text)
test_text_ints = [word2int[word.lower()]for word in new_text.split() if word in word2int.keys()]
return test_text_ints
def predict(model):
test_text_ints = [converts(text) for text in texts]
new_test_text_ints = reset_text(test_text_ints, seq_len=22)
text_tensor = torch.from_numpy(new_test_text_ints)
batch_size = text_tensor.size(0)
hs = model.init_hidden(batch_size)
text_tensor = text_tensor.to(device)
outs, hs = model(text_tensor,hs)
preds = torch.argmax(outs, dim=1)
for i in range(len(texts)):
print(texts[i])
print(" 预测结果是: ", category[int(preds[i])])
predict(model)
i wont let me child cry it out because i feel that loving her and lily when she was little was going to be opportunities that only lasted for those short few months
预测结果是: love
i feel there are dangerous games or activities
预测结果是: anger
i feel dirty and ashamed for saying that
预测结果是: sadness
最后
以上就是无辜水壶最近收集整理的关于lstm实战,nlp情感分析(Kaggle)的全部内容,更多相关lstm实战内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。


![[从零开始学习FPGA编程-29]:进阶篇 - 基本时序电路-时序电路的两大基本特征(状态记忆与时钟触发)](https://www.shuijiaxian.com/files_image/reation/bcimg25.png)





发表评论 取消回复