应该是笔记的终篇了。前三篇分别介绍了文本分类的基本处理流程(补了张图在下面)、中文文本分类的代码实现以及关于模型训练的一些经验总结。这篇来记录关于TextCnn算法实现的原理和运算流程。
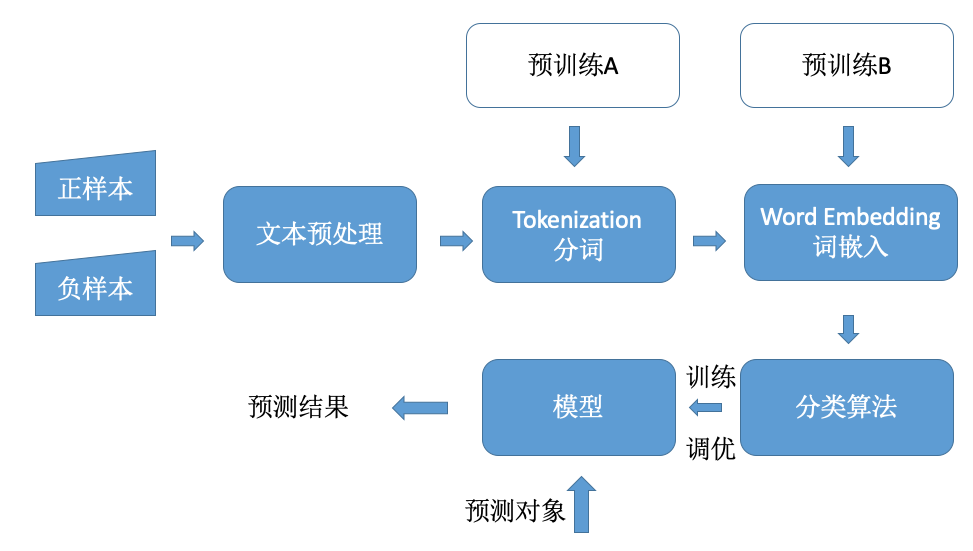
一、基本概念
卷积:矩阵卷积运算,比较典型的应用场景是图片处理。被卷积的对象是待提取特征的文本或图片的数据表示,也就是矩阵。
卷积核filter:是卷积的另外一个操作参数,一般是一个n*m的矩阵,在TextCnn中因为词向量维度上不需要横向卷积,因此m等于词向量长度,例如m=300,n则类似n-gram中的窗口,在句子的维度上滑动进行卷积操作。一个卷积核提取一种特征。
卷积运算过程参考:https://www.cnblogs.com/shine-lee/p/9932226.html
大多数讲解卷积操作的都是从二维矩阵上示例,便于理解卷积的过程。而实际上在算法的运算过程中还有提升卷积层输入数据/卷积核/卷积层输出数据的矩阵维度的三个参数:
Batch:批量输入时一次输入的数据条数。影响卷积层输入数据的矩阵维数。
例如一个最大句子长度(包含的分词个数)为N的样本,词向量为300维,批量一次输入64条样本,那么当前卷积层输入数据的维度就是[64,N,300]
输入通道数channel:单个样本输入算法时由多个矩阵值表示,分别输入算法,其中矩阵值个数就是channel数,影响卷积层输入数据的矩阵维数。
例如图片处理中,一张图片会根据三色原理分为红R、绿G、蓝B三个矩阵表示,各自走一个通道输入给算法,分别由卷积核在三个矩阵上单独提取特征,所以channel=3;而在TextCnn中静态static和non-static模式都是channel=1,即样本只用单个word embedding后的矩阵表示,只有在multichannel模式中做fine-tune和不做fine-tune的word embedding矩阵分别从两个channel输入给算法,此时channel=2。所以上面的例子中在static和non-static模式中输入矩阵维度变为为[64,N,300,1],multichannel模式中矩阵维度变为[64,N,300,2]。
输出通道数num_filters:单个卷积核会重复操作多少遍,即尝试提取多少遍特征,影响的是卷积核和卷积层输出数据的矩阵维度。
同样在上面的例子中,如果num_filters=128时,即一批样本每种卷积核会重复128遍,每个样本给出128个结果。如果卷积核的窗口filter_size是3,channel=1,则卷积核矩阵维度为[3,300,1,128],卷积层输出矩阵的维度[64,n-3+1,1,128],即64个样本,每个样本得到128个[n-3+1,1]个feature_map。
二、TextCnn模型结构
下面两张图是被各大TextCnn讲解blog中引用率最高的两张模型图,其中channel=2(因为实践中的channel=1,这两张图让我对channel和num_filters混淆了好久)。
TextCnn的模型结构很简单,一层卷积,一层池化,一层全连接输出,卷积层中会做非线性激活,全连接层中会做dropout和softmax。卷积层后,不同的channel会得到单独的feature_map(因为不同的输入channel输入矩阵不一样,卷积也是单独做的,卷积核会有细微差别),每个feature_map会单独进行max-pooling最大池化,选一个最大的特征值作为池化层的输出。注意图中展示的是每个卷积核进行一次卷积操作的流程,对于num_filters=128的情况,需要自动脑补128次这样的过程(代码实现中是一次的数据输入和运算),池化层后每个卷积核就会有channel*num_filters个结果,如果有3个卷积核就会有3*channel*num_filters个结果。然后全连接层中把这3*channel*num_filters个结果做dropout和softmax得到预测输出。
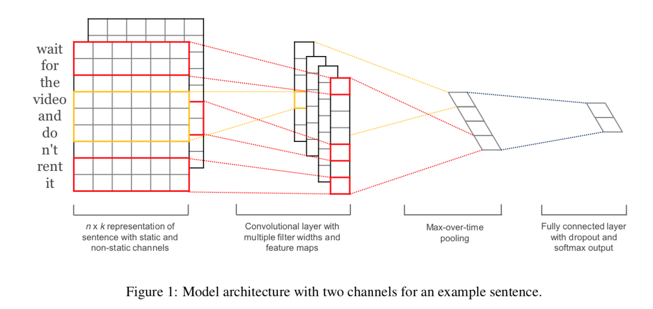
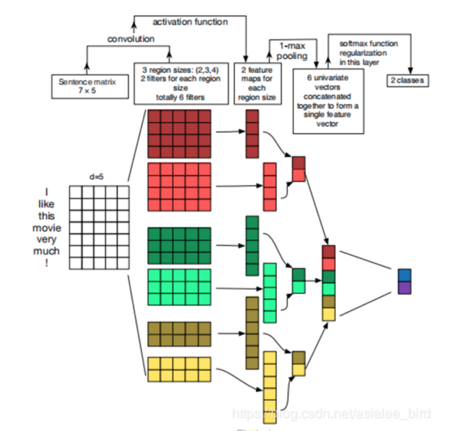
三、算法实现
例如有这样的一个TextCnn应用场景,Batch=64,最大句子长度sequence_length=N,词向量维度embedding_size=300,num_filters=128,channel=1,Dropout_keep_prob=0.5,卷积核有3个,filter_size分别为3,4,5。
其TextCnn从卷积层到输出层的代码实现如下(word embedding输入层的介绍参见笔记二),代码中使用tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)方法实现的卷积操作,其输入input和filter卷积核都是4维矩阵。input的shape是[batch, in_height, in_width, in_channels],分别对应前文提到的batch、最大句子长度sequence_length、词向量维度embedding_size、channel输入通道数(图片处理中对应的就是图片张数,图片数学表示的矩阵高度,图片数学表示的矩阵宽度和输入通道数);filter的shape是[filter_height, filter_width, in_channels, out_channels],分别对应前文提到的filter_size,词向量维度embedding_size(如前文所述,横向不参与卷积平移)、channel和num_filters。函数讲解可参考:https://blog.csdn.net/mao_xiao_feng/article/details/53444333
# Create a convolution + maxpool layer for each filter size
pooled_outputs = []
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope("conv-maxpool-%s" % filter_size):
# Convolution Layer
filter_shape = [filter_size, embedding_size, 1, num_filters]
W = tf.Variable(tf.random.truncated_normal(filter_shape, stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name="b")
conv = tf.nn.conv2d(
self.embedded_chars_expanded,
W,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")
# Apply nonlinearity
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
# Maxpooling over the outputs
pooled = tf.nn.max_pool2d(
h,
ksize=[1, sequence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
pooled_outputs.append(pooled)
# Combine all the pooled features
num_filters_total = num_filters * len(filter_sizes)
self.h_pool = tf.concat(pooled_outputs, 3)
self.h_pool_flat = tf.reshape(self.h_pool, [-1, num_filters_total])
# Add dropout
with tf.name_scope("dropout"):
self.h_drop = tf.nn.dropout(self.h_pool_flat, self.dropout_keep_prob)
# Final (unnormalized) scores and predictions
with tf.name_scope("output"):
W = tf.get_variable(
"W",
shape=[num_filters_total, num_classes],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.Variable(tf.constant(0.1, shape=[num_classes]), name="b")
l2_loss += tf.nn.l2_loss(W)
l2_loss += tf.nn.l2_loss(b)
self.scores = tf.nn.xw_plus_b(self.h_drop, W, b, name="scores")
self.predictions = tf.argmax(self.scores, 1, name="predictions")
# Calculate mean cross-entropy loss
with tf.name_scope("loss"):
losses = tf.nn.softmax_cross_entropy_with_logits(logits=self.scores, labels=self.input_y)
self.loss = tf.reduce_mean(losses) + l2_reg_lambda * l2_loss
# Accuracy
with tf.name_scope("accuracy"):
correct_predictions = tf.equal(self.predictions, tf.argmax(self.input_y, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy")代码实现的流程就是卷积层(加一层非线性)-> 池化层 -> 全连接层(特征组合、数据降维、dropout、softmax和归一化输出), 其完整的数据运算过程如下图,里边详细梳理了各个处理环节的tensor shape。
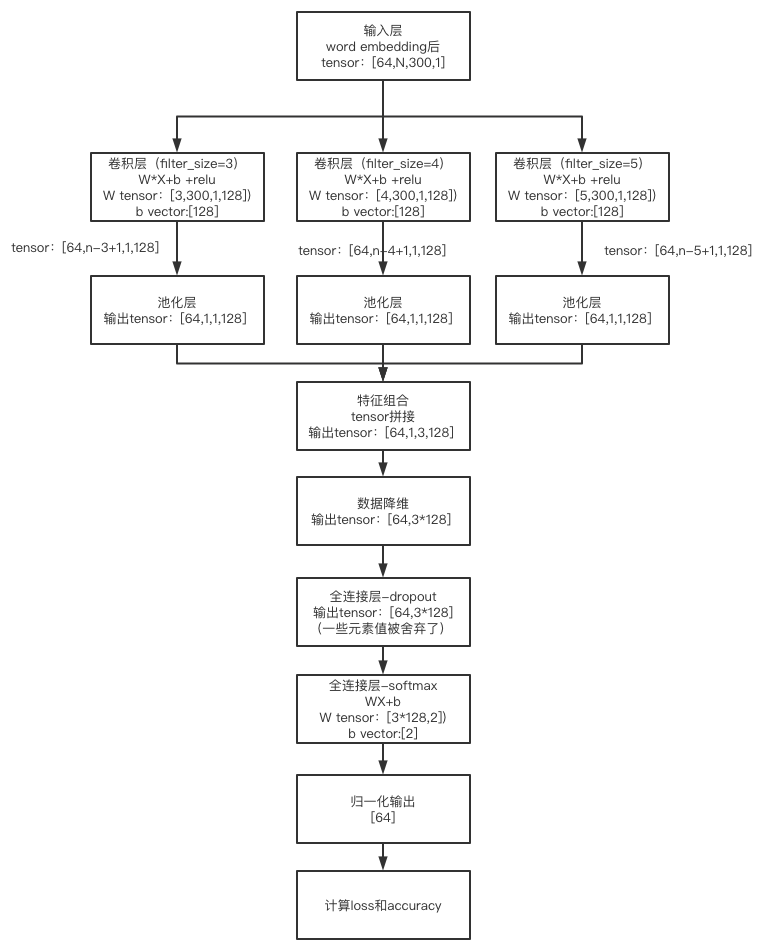
卷积层用卷积核W进行卷积运算后用b做偏移调整,然后引入非线性relu解决线性不可分问题(relu介绍参考https://www.jianshu.com/p/338afb1389c9),其输出可以理解为就是64个样本、每个样本输出128个feature_map。
池化层选取保留最强特征,输出可以理解为64个样本、每个样本128次选取的最强特征128个。
因为有3个卷积核,需要把每个卷积核提取到的特征整合到一起,于是在第三维上进行矩阵拼接tf.concat(pooled_outputs, 3),得到[64,1,3,128],可以理解为64个样本,每个样本128个输出,每个输出为一个长度为3的向量(这里channel=1,否则就是3*channel的向量)。
再通过tf.reshape(self.h_pool, [-1, num_filters_total])进行数据降维,因为每个样本有1个channel,3个卷积核,每个卷积核提取128遍,得到的1*3*128个结果值,因此降到2维矩阵就是[64,1*3*128]。
dropout是在一定的数据概率内舍弃一些结果值,避免过拟合,并不影响shape,因此其输出shape仍是[64,1*3*128]。
输出层做的就是全连接,把每个样本的这1*3*128个结果值线性加权,得到每个分类上的概率(例子中的是二分类)。注意,这里的WX是矩阵乘积,区别于上面的W*X卷积操作。
归一化tf.argmax(self.scores, 1, name="predictions")实际就是看两个分类概率哪个概率大,取其索引,就得到要么0要么1的结果了。
在训练的过程中计算self.loss = tf.reduce_mean(losses) + l2_reg_lambda * l2_loss 模型损失和精确率。通过梯度下降方法求得loss最小的最优解。
grads_and_vars = optimizer.compute_gradients(cnn.loss)
train_op = optimizer.apply_gradients(grads_and_vars, global_step=global_step)
通过图中的算法运算过程可知,模型的参数即两组W和b(卷积层和输出层),在non-static中词向量也会在训练中进行fine-tune。模型训练及调优后得到的最优解,即确定了模型参数和变更后的词向量。在预测阶段仍然是图中展示的运算过程,只不过W、b等就是固定的了,最后直接给出预测结果。
最后
以上就是贪玩红酒最近收集整理的关于NLP文本分类入门学习及TextCnn实践笔记——算法实现(四)的全部内容,更多相关NLP文本分类入门学习及TextCnn实践笔记——算法实现(四)内容请搜索靠谱客的其他文章。








发表评论 取消回复