最近在做文本分类方面的内容,之前接触数据挖掘的算法比较多一点,对自然语言处理领域基本上没有接触过。在做这一部分的内容的时候也是花了一些精力。用了一周的时间,将整个过程实现了一遍。我还是属于这个领域的菜鸟,这篇博文主要是想把我这周的成果整理记录一下,废话不多说,切入正题。
我用的是网络上搜狗新闻分类的数据集,一共九个类,每个类有2000条语料,数据量还是比较大的。首先我们需要将文档中的语料一一读入到程序中 。因为数据量很大,所以我们每个类别取100条语料进行验证,对读入的每篇语料进行切词处理,这里我使用的是jieba分词,对切词后的结果去除停留词以及文中的数字,同时按照8:2的比例切分训练集与测试集。代码如下:
import os
import jieba
import sklearn
import sys
import numpy as np
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
reload(sys)
sys.setdefaultencoding('utf8')
stopwords_file=open('D:stopwords.txt','r')#读入停词表
stopwords=[]
for line in stopwords_file.readlines():
stopwords.append(line.rstrip())#形成停用词列表
folder_path = 'D:SogouC.reducedReduced'
folder_list = os.listdir(folder_path)
class_list = [] #我们用[0,1,...]代表分类
nClass = 0
N = 100 # 每类文件 最多取 100 个样本
train_set = []#训练集
test_set = []#测试集
train_lable=[]#训练集类别标签
test_lable=[]#测试集类别标签
for i in range(len(folder_list)):
new_folder_path = folder_path + '\' + folder_list[i]
files = os.listdir(new_folder_path)
class_list.append(nClass)
nClass += 1
j = 0
nFile =min(len(files),N)
for file in files:
if j > N:
break
fobj = open(new_folder_path + '\' + file, 'r')
raw = fobj.read()
word_cut = jieba.cut(raw, cut_all=False)
word_list = list(word_cut)
word_txt_features = []
for word in word_list:
if word not in stopwords and not word.isdigit():
word_txt_features.append(word)
if j < 0.8 * nFile:
train_set.append(" ".join(word_txt_features))
#这里将每个词用空格链接,为了之后使用TFIDF处理数据方便
train_lable.append(class_list[i])
else:
test_set.append(" ".join(word_txt_features ))
test_lable.append(class_list[i])
fobj.close()
j += 1
OK,上面已经把数据处理好,现在我们有了训练集和测试集以及相应的类标签。通过代码也能看出,数据集的格式基本上是:每行代表某个类目录下的一个txt文本切词等处理后的数据。下面我们的任务就是提取特征词。特征词的提取方法有很多,这里我选用了TFIDF的方法。计算出词向量权重矩阵。这一步我们会碰到测试集与训练集的词向量矩阵维度不同的问题,所以这里我参考了一篇博文,里面有解决这个问题的多种方法。代码如下:
count_v1= CountVectorizer(stop_words = None, max_df = 0.5)
counts_train = count_v1.fit_transform(train_set)
count_v2 = CountVectorizer(vocabulary=count_v1.vocabulary_)
counts_test = count_v2.fit_transform(test_set);
tfidftransformer = sklearn.feature_extraction.text.TfidfTransformer()
tfidf_train = tfidftransformer.fit(counts_train).transform(counts_train);
tfidf_test = tfidftransformer.fit(counts_test).transform(counts_test);
train_data=tfidf_train.toarray()
test_data=tfidf_test.toarray()
train_lab=np.array(train_lable)
test_lab=np.array(test_lable)
这样我们就形成了测试集和测试集词向量矩阵。接下来分类算法要登场了,我选择了比较大众化的多项式贝叶斯分类器,它的输入都是矩阵形式的数据。实现代码比较简单,我用的是sklearn库中的MultinomialNB,sklearn库很强大,还需要继续学习。在自然语言处理中还可以用nltk库,里面也有分类算法的函数,不过我对这个库接触不多,函数中的参数我还没怎么研究过,有时间再补充。
clf=MultinomialNB().fit(train_data,train_lab)
doc_class_predicted=clf.predict(test_data)
print (np.mean((doc_class_predicted==test_lable)))#计算准确率
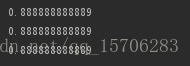
最后结果如下:

准确率在88.9%左右,列表里存放的是预测的类别标签。可以看得出大部分类别预测准确率在90%左右。
做完之后我总结了一下存在的问题:
1.维度太大。900条语料在经过切词,去停留词处理后,经过TFIDF得到的矩阵维度比较大。测试集[189L,41758L],训练集为[720L,41758L].因此程序运行时时间消耗非常大,第一次运行用了1小时。所以后面要找到有效降维的方法。我看到网络上有人用CHI,基本原理能了解,如果有实现过的博友希望能交流一下。
2.准确率有待进一步提高。影响准确率的方面很多,可能是分类模型的选择,特征词的选择等等,希望能再多次修改过程,能够得到比较乐观的准确率。
3.程序最后我也计算了召回率与精确率,很疑惑的是他们的值都是跟之前计算的准确率一样的,这个很不应该,但实在不知道哪里出现了错误。希望博友友情指导一下。
accuracy=accuracy_score(test_lab,doc_class_predicted)
print accuracy
print recall_score(test_lab,doc_class_predicted,average='macro')
最后
以上就是平淡砖头最近收集整理的关于文本分类全过程实现的全部内容,更多相关文本分类全过程实现内容请搜索靠谱客的其他文章。








发表评论 取消回复