爬取豆瓣几乎成了每个学爬虫的都想要尝试的习惯。不过不要频繁访问,以免给人家的服务器带来太大负担
一、分析页面
打开豆瓣电影的网站,找到正在上映的电影,我这里选择的是太原地区的。按一下F12审查元素,发现电影信息在一个class=lists的ul标签下,然后每一个li表示一部电影,大部分电影信息都能在此li标签的属性中获取到,海报以及详情链接还需要在往下的ul/li/a标签下
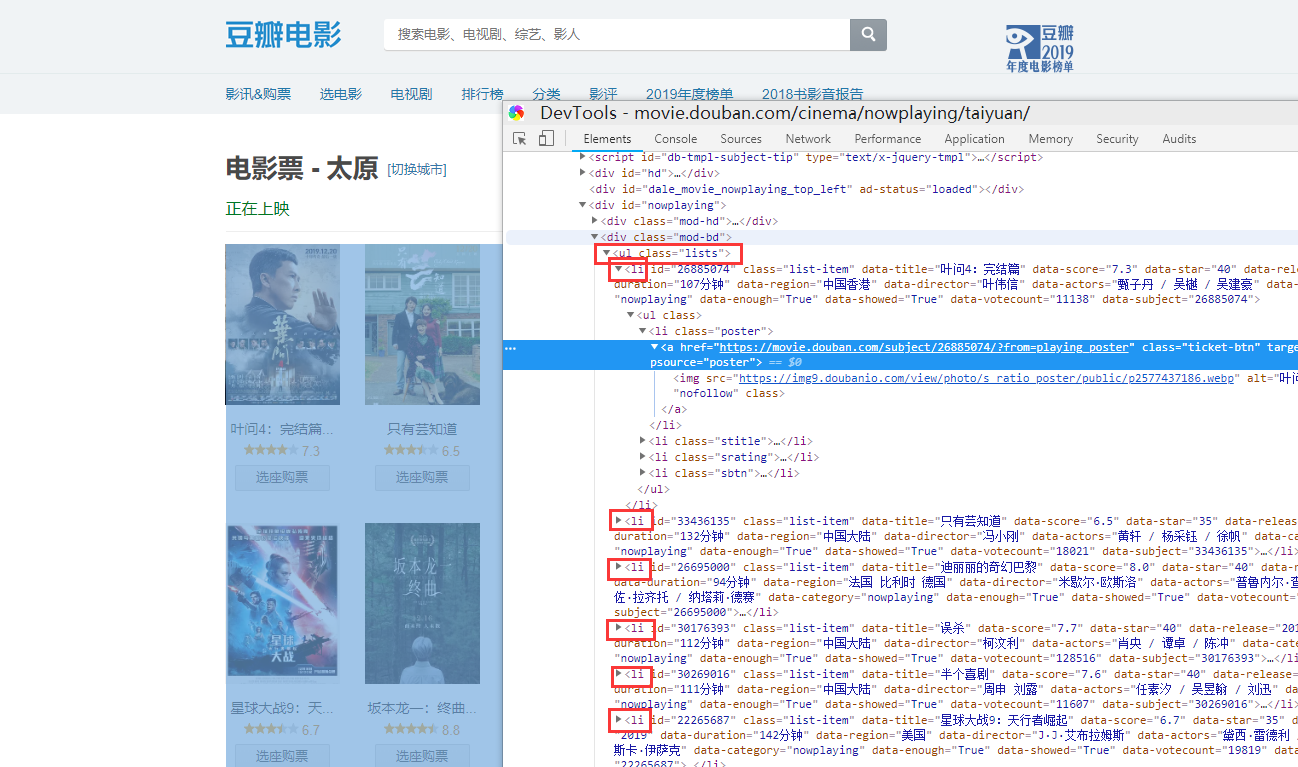
二、代码
代码很简单,先使用requests.get()方法获取页面,再用etree和xpath筛选到每一部电影的信息
import requests
from lxml import etree
import json
url = "https://movie.douban.com/cinema/nowplaying/taiyuan/" # 正在上映的电影,这里是太原地区
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"}
res = requests.get(url=url, headers=headers) # 用requestS发起get请求
html = etree.HTML(res.text) # 把请求结果转换成etree元素
ul = html.xpath("//ul[@class='lists']") # xpath选择电影所在的ul标签
# print(etree.tostring(ul[0])) # 查看获取到的内容
movies = []
lis = ul[0].xpath("./li") # 每一部电影都在一个li标签下
for li in lis:
title = li.xpath("@data-title")
score = li.xpath("@data-score")
release = li.xpath("@data-release")
duration = li.xpath("@data-duration")
region = li.xpath("@data-region")
director = li.xpath("@data-director")
actors = li.xpath("@data-actors")
img = li.xpath("./ul/li/a/img/@src")
detail = li.xpath("./ul/li/a/@href")[0]
# 新建一个存放电影信息的字典
movie = {
"标题": title[0],
"评分": score[0],
"上映时间": release[0],
"时长": duration[0],
"国家/地区": region[0],
"导演": director[0],
"主演": actors[0],
"图片": img[0],
"详情": detail[0]
}
movies.append(movie) # 把每一部movie电影存放到movies列表中
# print(movies)
with open("movies.json", "w", encoding="utf-8") as fp:
json.dump(movies, fp, ensure_ascii=False) # 保存为json格式到电脑上
最后
以上就是优秀服饰最近收集整理的关于【python】爬取正在上映的豆瓣电影信息(etree、xpath)的全部内容,更多相关【python】爬取正在上映内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复