最近总是在复习,想找几本电影看看,于是就去了豆瓣的top100上看看有什么好看的电影,就简单的写了一个程序,想获取一下电影的简介
- 爬取原网页
网页的源地址 http://movie.douban.com/tag/top100?start=0&type=S仔细一看,可以到出有4页,但是每页只有20个,所以应该有5页才对啊
try:
request = urllib2.Request(url)
response = urllib2.urlopen(url)
except urllib2.URLError,e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
content = response.read().decode('utf-8')看到源代码可以看到一些想要的信息比如说电影名和图片,和电影的详细地址
2.正则匹配
将电影连接,电影名提取出来,在进行访问,可以得到电影的详细介绍及时上面文章的http://movie.douban.com/subject/1292063/
在这里我主要获取了它的剧情简介和一张图片
os.mkdir(r'F:/b/%s'%item[1])
url = item[0]
html = urllib.urlopen(url).read().decode('utf-8')
#print html
pattern=re.compile('data-pic="(.*?)".+? <span property="v:summary" class="">(.*?)</span>',re.S|re.M)
#pattern=re.compile(' <a href= "#".+? data-pic="(.*?)".+? <span property="v:summary" class="">([sS]*)</span>',re.S|re.M)
find = re.findall(pattern,html)
for i in find:
print i[0],i[1],type(i[1])
#urllib.urlretrieve(i[0],'f:/python/%s/%s.jpg'%(item[1],item[1]))
f= open('f:/b/%s/%s.txt'%(item[1],item[1]),'w+')
f.write(i[1].encode('utf-8'))
f.close()
#urllib.urlret并将电影名作为文件名,将图片保存到改文件夹下,
说白了其实很简单,就是打开网页,进行匹配,将匹配的文字,图片保存到特定的文件夹下
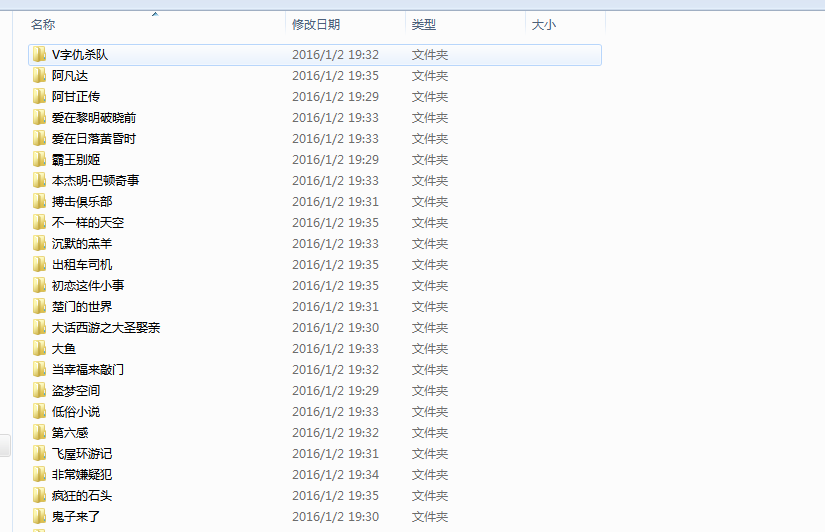
这是实现的效果
3.源代码
#coding:utf-8
import re
import urllib
import urllib2
import os
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
def get(url):
try:
request = urllib2.Request(url)
response = urllib2.urlopen(url)
except urllib2.URLError,e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
content = response.read().decode('utf-8')
pattern = re.compile('<a class="nbg" href="(.*?)" title="(.*?)">',re.S|re.M)
items = re.findall(pattern,content)
return items
def get_con(url):
items = get(url)
i = 1
for item in items:
print item[0],item[1],type(item[1])
os.mkdir(r'F:/b/%s'%item[1])
url = item[0]
html = urllib.urlopen(url).read().decode('utf-8')
pattern=re.compile('data-pic="(.*?)".+? <span property="v:summary" class="">(.*?)</span>',re.S|re.M)
find = re.findall(pattern,html)
for i in find:
print i[0],i[1],type(i[1])
#urllib.urlretrieve(i[0],'f:/python/%s/%s.jpg'%(item[1],item[1]))
f= open('f:/b/%s/%s.txt'%(item[1],item[1]),'w+')
f.write(i[1].encode('utf-8'))
f.close()
else:
print "Over"
list = ['http://movie.douban.com/tag/top100?start=0&type=S',
'http://movie.douban.com/tag/top100?start=20&type=S',
'http://movie.douban.com/tag/top100?start=40&type=S',
'http://movie.douban.com/tag/top100?start=60&type=S']
for url in list:
print url
get_con(url)
4.总结
感觉写的正则不是很好,应该在多匹配出一些信息,比如上映时间,豆瓣评分什么的,应该还有一个排名,感觉分成一个一个文件夹不太好
最好放在一个TXT文档中,这样可能比较看上去方便一点。我会在修改一下代码,2016年第一个代码。
( 写于2016年1月2日23:24,http://blog.csdn.net/bzd_111)
最后
以上就是可爱大船最近收集整理的关于python爬取豆瓣电影信息的全部内容,更多相关python爬取豆瓣电影信息内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复