一.实验目的
(1)加深对Cache的基本概念、基本组织结构以及基本工作原理的理解。
(2)掌握Cache容量、相联度、块大小对Cache性能的影响。
(3)掌握降低Cache不命中率的各种方法以及这些方法对提高Cache性能的好处。
(4)理解LRU与随机法的基本思想以及它们对Cache性能的影响。
二、实验内容和步骤
1、启动CacheSim。
2、根据课本上的相关知识,进一步熟悉Cache的概念和工作机制。
3、依次输入以下参数:Cache容量、块容量、映射方式、替换策略和写策略。
| Cache容量 | 块容量 | 映射方式 | 替换策略 | 写策略 |
| 256KB | 8 Byte | 直接映射 | ------ | ------- |
| 64KB | 32 Byte | 4路组相联 | LRU | ------- |
| 64KB | 32 Byte | 4路组相联 | 随机 | -------- |
| 8KB | 64 Byte | 全相联 | LRU | --------- |
4、读取cache-traces.zip中的trace文件。
5、运行程序,观察cache的访问次数、读/写次数、平均命中率、读/写命中率。
三.实验结果分析
1、Cache的命中率与其容量大小有何关系?
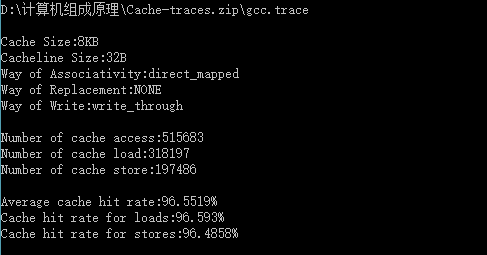
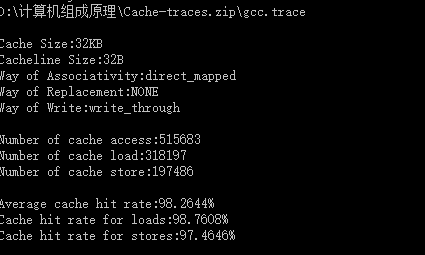
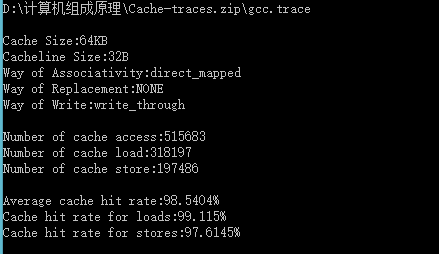
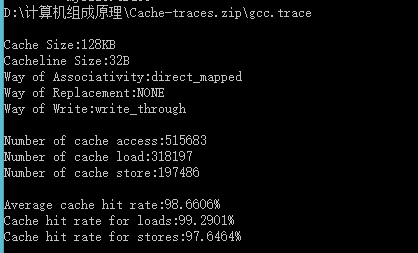





| Cache容量 | 块容量 | 映射方式 | 替换策略 | 写策略 | 命中率 |
| 8KB | 32 Byte | 直接映射 | ------ | Write through | 96.5519% |
| 32KB | 32 Byte | 直接映射 | ------ | Write through | 98.2644% |
| 64KB | 32 Byte | 直接映射 | ------ | Write through | 98.5404% |
| 128KB | 32 Byte | 直接映射 | ------ | Write through | 98.6606% |
| 256KB | 32 Byte | 直接映射 | ------ | Write through | 98.7066% |
| 512KB | 32 Byte | 直接映射 | ------ | Write through | 98.8148% |
| 1024KB | 32 Byte | 直接映射 | ------ | Write through | 98.8188% |
| 2048KB | 32 Byte | 直接映射 | ------ | Write through | 98.8194% |
由表可得:Cache容量越大,其CPU的命中率就越高。Cache命中率随着cache的容量增大而增大。容量小时cache命中率提高速度快,cache容量变大时,命中率提高速度逐渐下降。所以容量也没必要太大,太大会增加成本,而且当容量达到一定值时,命中率已不因容量的增大而有明显的提高。因此Cache容量是总成本与命中率的折中值。
2、Cache块大小对不命中率有何影响?
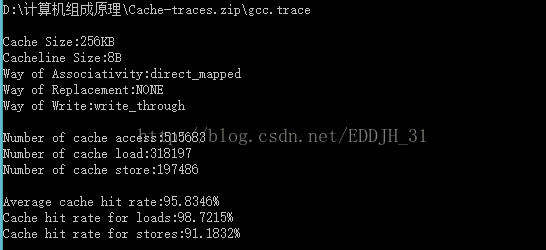

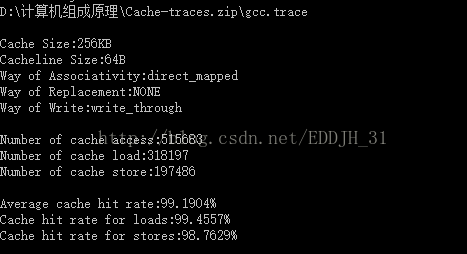

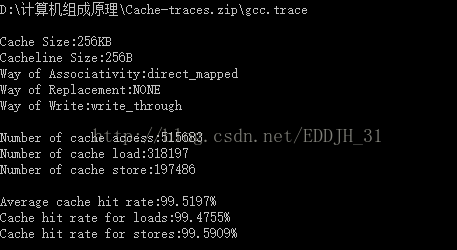
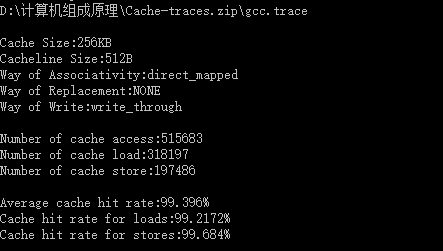
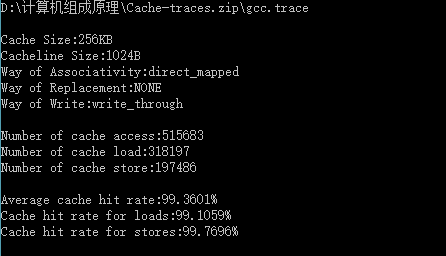
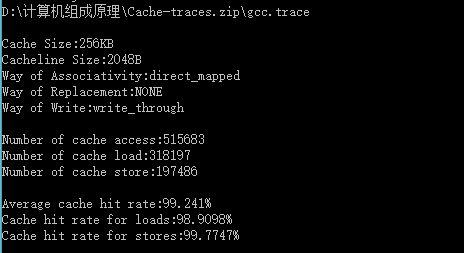
| Cache容量 | 块容量 | 映射方式 | 替换策略 | 写策略 | 命中率 |
| 256KB | 8 Byte | 直接映射 | ------ | Write through | 95.8346% |
| 256KB | 32 Byte | 直接映射 | ------ | Write through | 98.7066% |
| 256KB | 64 Byte | 直接映射 | ------ | Write through | 99.1904% |
| 256KB | 128Byte | 直接映射 | ------ | Write through | 99.3965% |
| 256KB | 256Byte | 直接映射 | ------ | Write through | 99.5197% |
| 256KB | 512Byte | 直接映射 | ------ | Write through | 99.396% |
| 256KB | 1024 Byte | 直接映射 | ------ | Write through | 99.3601% |
| 256KB | 2048 Byte | 直接映射 | ------ | Write through | 99.241% |
经过表中数据分析得出,随着块大小的增大时,cache的命中率增大,当块长增加到一定程度后,再次增大块大小的时候,命中率开始减小。
分析:块长与命中率之间的关系较为复杂,它取决于各程序的局部特性,当块由小到大增长时,起初会因局部性原理使命中率有所提高。由局部性原理指出,在已被访问字的附近,近期也可能被访问,因此,增大块长,可将更多有用字存入缓存,提高其命中率。可是,如果继续增大块长,命中率有可能下降,这是因为所装入缓存的有用数据反而少于被替换掉的有用数据。由于块长的增大,导致缓存中块数的减少,而新装入的块要覆盖就块,很可能出现少数块刚刚装入就被覆盖,因此命中率反而下降。再者,块增大后,追加上的字距离已被访问的字更远,故近期被访问的可能性会更少。
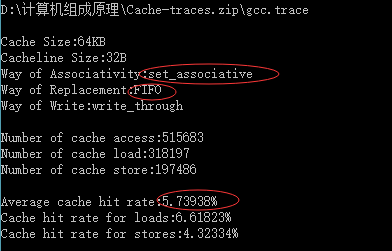
3、替换算法和相联度大小对不命中率有何影响?
替换算法:
FIFO算法:
LFU算法:
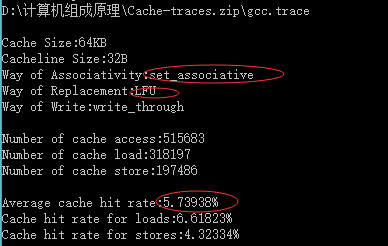
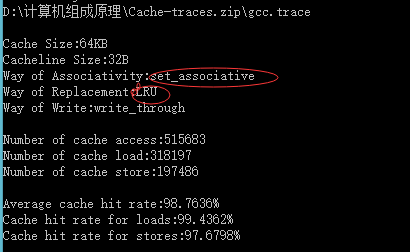
LRU算法:
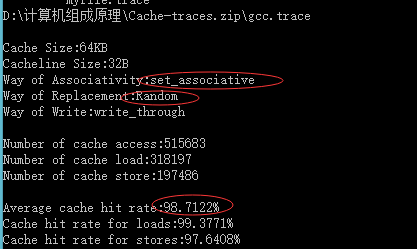
Random法:
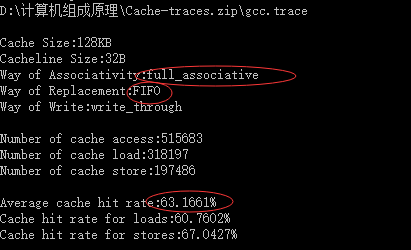
FIFO算法:
LFU算法:
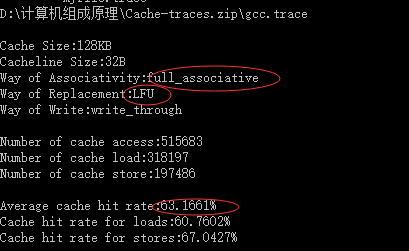
相联度:
相联度为32时:
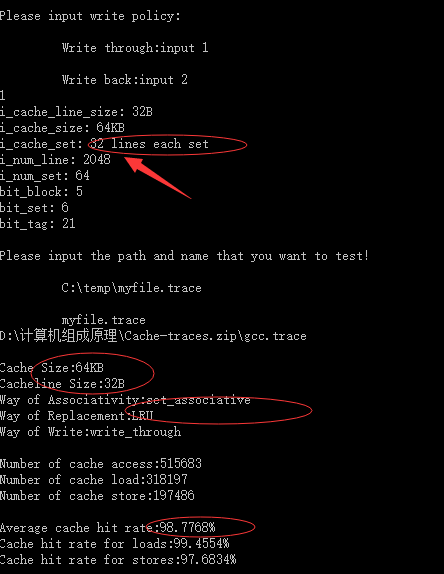
相联度为16时:
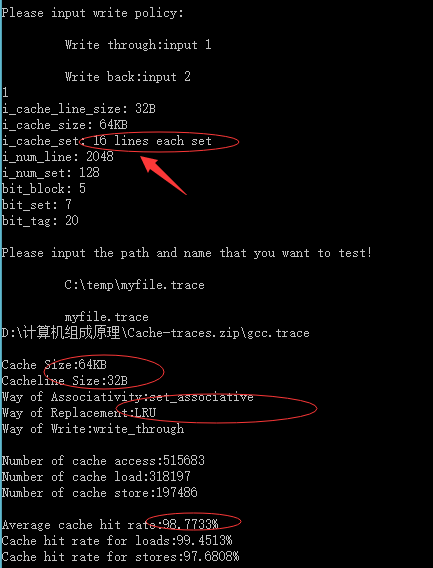
相联度为8时:
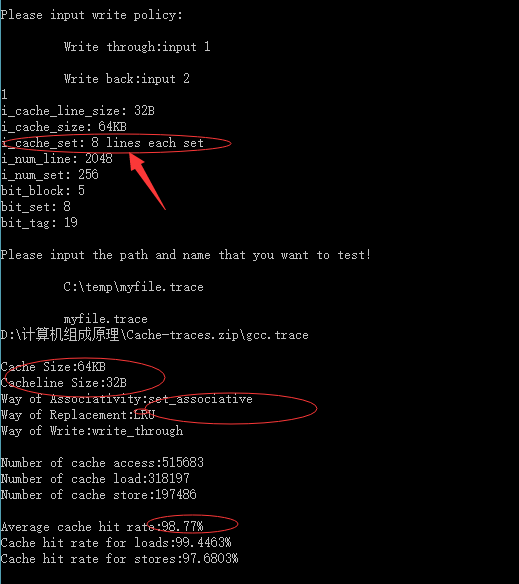
相联度为4:
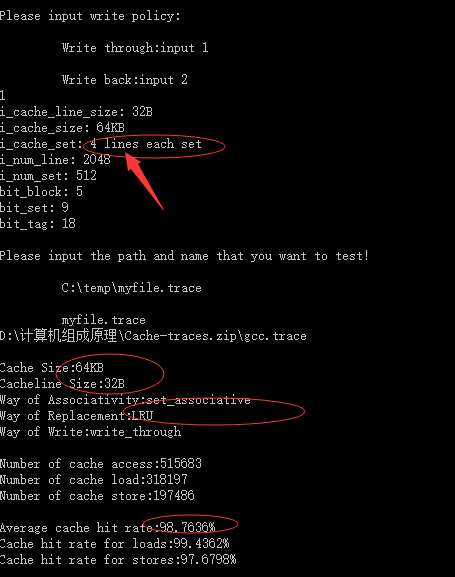
相联度为2:
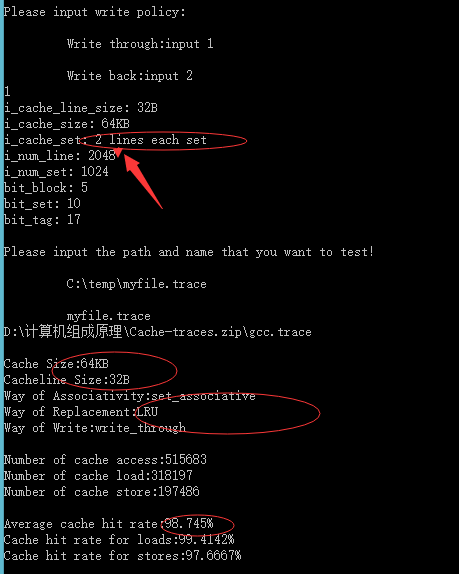
相联度为64:
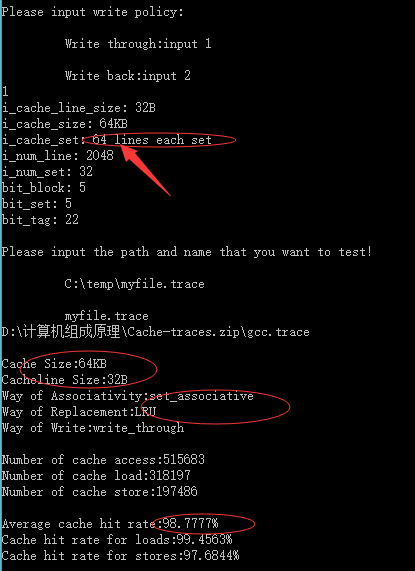
| Cache容量 | 块容量 | 映射方式 | 替换策略 | 命中率 |
| 64KB | 32 Byte | 组相连映射 | FIFO | 5.73938% |
| 64KB | 32Byte | 组相连映射 | LFU | 5.73938% |
| 64KB | 32Byte | 组相连映射 | Random | 98.7122% |
| 128KB | 32 Byte | 全相连映射 | FIFO | 63.1661% |
| 128KB | 32 Byte | 全相连映射 | LFU | 63.1661% |
| Cache容量 | 块容量 | 映射方式 | 替换策略 | 命中率 |
| 64KB | 128 Byte | 组相连映射 | LRU | 98.7777% |
| 64KB | 64Byte | 组相连映射 | LRU | 98.7636% |
| 64KB | 32Byte | 16组相连映射 | LRU | 98.7733% |
| 64KB | 32Byte | 8组相连映射 | LRU | 98.77% |
| 64KB | 32 Byte | 4组相连映射 | LRU | 98.7636% |
| 64KB | 32 Byte | 2组相连映射 | LRU | 98.745% |
替换算法中:LRU算法的平均命中率比FIFO的高
LRU算法比较好地利用访存局部性原理,替换出近期用得最少的字块,它需要随时记录cache 各个字块使用情况。FIFO不需要记录各个字块的使用情况,比较容易实现开销小,但是没有根据访存的局部性原理,最早调入的信息可能以后还要用到,或经常用到例如循环程序;
Cache 容量一定时,随着相联度的不断增加,不命中率渐渐减小。
四.实验心得
通过这次试验让我更熟悉的掌握了第四章高速缓冲存储器的基础内容,然后由书中知道了cache发展历程,基本工作原理;对实验所需要的重点名词,进行了理解;命中率,访问效率,平均访问时间例题进行了理解,从而分析了Cache容量,相关度,块大小,替换算法对命中率的影响;因为LRU 、FIFO 、RANDOM替换算法对命中率也有这一些影响; 看了主存地址映射:有直接映射、组相联映射、全相联映射。组相联映射有点麻烦,不太好理解。
不是太容易理解了,然后百度搜了一些相连度大小对命中率影响,然后运用CacheSim模拟器,仅仅从一个数值中值看出来简单的变化;然后查阅课本;知道了为什么会存在着现象;这种实践让在学习知识点的过程中,印象更加深刻了。
最后
以上就是顺心盼望最近收集整理的关于实验1 Cache模拟器的实现的全部内容,更多相关实验1内容请搜索靠谱客的其他文章。
![【转】[专题学习][计算几何]](https://www.shuijiaxian.com/files_image/reation/bcimg2.png)







发表评论 取消回复