一、存储器山的数据测量以及绘制
1.存储器山的数据测量(包含我所测试的数据)
这一部分很简单,因为代码已经由CMU提供给大家了,大家只需要简单地修改代码,将结果输出到txt文件即可,然后再用MATLAB或者Python写一个脚本读取该txt文件,然后将结果绘制出来即可。
首先,将结果输出到文件,很简单,这个大家都会。不过这里还是有一个要注意的点,将修改的代码编译时,(由于我是在Linux系统上完成这个实验的),mountain.c这个文件中包含对另外两个自定义的头文件(“clock.h”以及“fcyc2.h)的引用,因此编译时需要执行:
gcc -Og -o my_memory_mountain moutain.c clock.c fcyc2.c
然后会得到一个可执行文件 my_memory_mountain,然后直接执行./my_memory_moutain等待一段时间之后就会得到存储器山的测量结果了。以我自己所测量的结果为例:
首先是原始输出的数据:
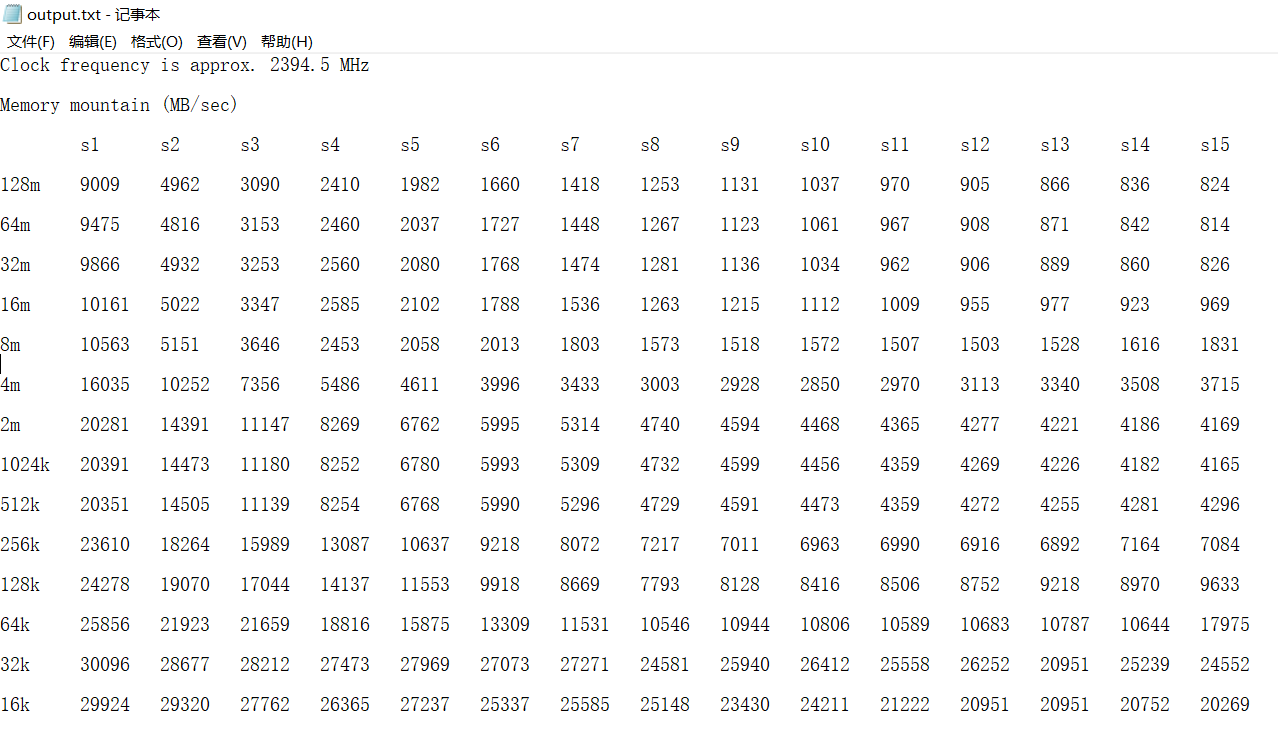
其中s1-s15为步长,128m是数据大小,表格结果为读吞吐量。为了便于后期脚本的数据读取与处理,将原始结果人工进行处理,结果如下:
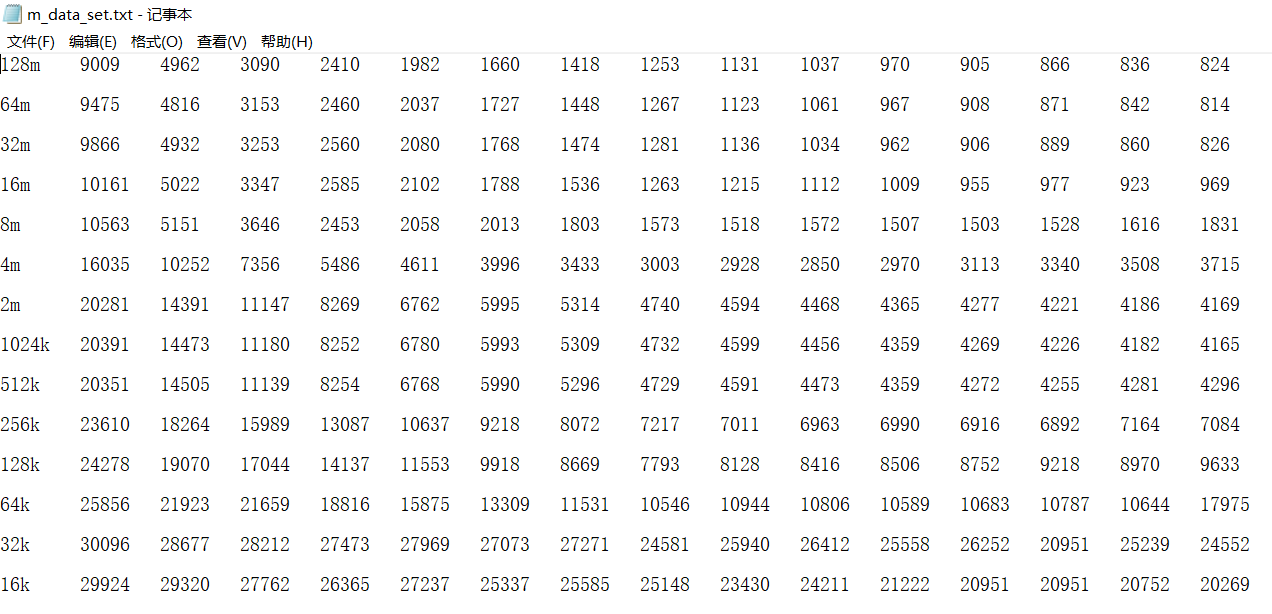
2.存储器山的绘制(包含代码以及结果)
因为我Matlab用得不熟,所以这里是用python的第三方库pyecharts的Surface3D来绘制的存储器山,但是绘制出来的结果不是很理想,因为我看了很久文档都没有弄太明白如何设置颜色的渐变,或者是说将存储器上的不同区域着上不同的色。
其实从pyecharts的官方文档中,我只找到了一个设置颜色渐变的系列配置项,ItemStyleOpts,但是,我设置的时候老出问题,而且好像没有什么效果
先上python的代码(全局配置项当中的VisualMapOpts其实可以忽略,我当时是想设置颜色渐变的,但是没弄出来,所以把这一部分的代码去掉也是没有问题的):
# author Morty
# 2019-8-25
# python 3.6
from pyecharts.charts import Surface3D
from pyecharts import options as opts
class CreateMountain:
def __init__(self):
self.data_set = []
self.gragh = Surface3D()
def data_process(self):
with open(r"C:Users54235Desktopm_data_set.txt", "r") as f:
data_set_origin = f.readlines()
for line in data_set_origin:
for index, item in enumerate(line.split("t")[:-1], start=0):
# index即为步长
if index == 0:
read_throughput = int(item[0:-1])
flag = item[-1]
if flag == "m":
read_throughput *= 1000000
elif flag == "k":
read_throughput *= 1000
else:
size = int(item)
self.data_set.append([index, read_throughput, size])
def plot(self):
self.data_process()
self.gragh.add(
# series name
"",
# 通过k*k循环展开测出来的数据集
data=self.data_set,
# 三维图形的着色效果配置,realistic即为真实感渲染
shading="realistic",
# 图元配置项
itemstyle_opts=opts.ItemStyleOpts(),
# 3D X坐标轴配置项
xaxis3d_opts=opts.Axis3DOpts(
name="步长",
name_gap=40),
# 3D Y坐标轴配置项
yaxis3d_opts=opts.Axis3DOpts(
name="大小/B",
name_gap=40),
# 3D Z坐标轴配置项
zaxis3d_opts=opts.Axis3DOpts(
name="存储器读取速度MB/s",
name_gap=40),
# 三维笛卡尔坐标系配置项
grid3d_opts=opts.Grid3DOpts(
width=100,
height=100,
depth=100
),
).set_global_opts(
title_opts=opts.TitleOpts(
title="Memory Mountain K*K Loop unrolling",
pos_left="center",
pos_top=90,
),
visualmap_opts=opts.VisualMapOpts(
dimension=3,
max_=1,
min_=-1,
range_color=[
"#313695",
"#4575b4",
"#74add1",
"#abd9e9",
"#e0f3f8",
"#ffffbf",
"#fee090",
"#fdae61",
"#f46d43",
"#d73027",
"#a50026",
],
)).render()
if __name__ == "__main__":
c = CreateMountain()
c.plot()
关于pyecharts,官方文档很友好,很容易阅读,中文文档的传送门:
pyecharts中文文档
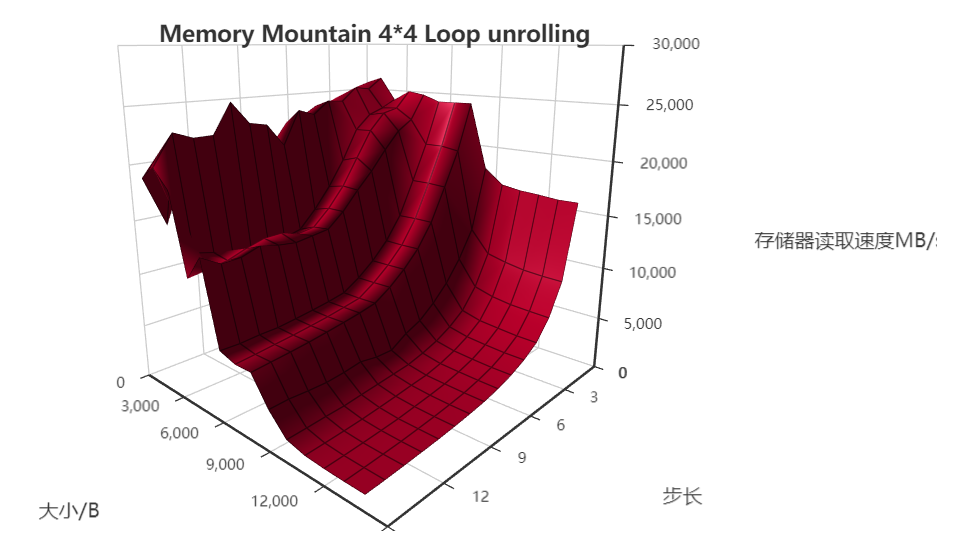
绘制结果如下:
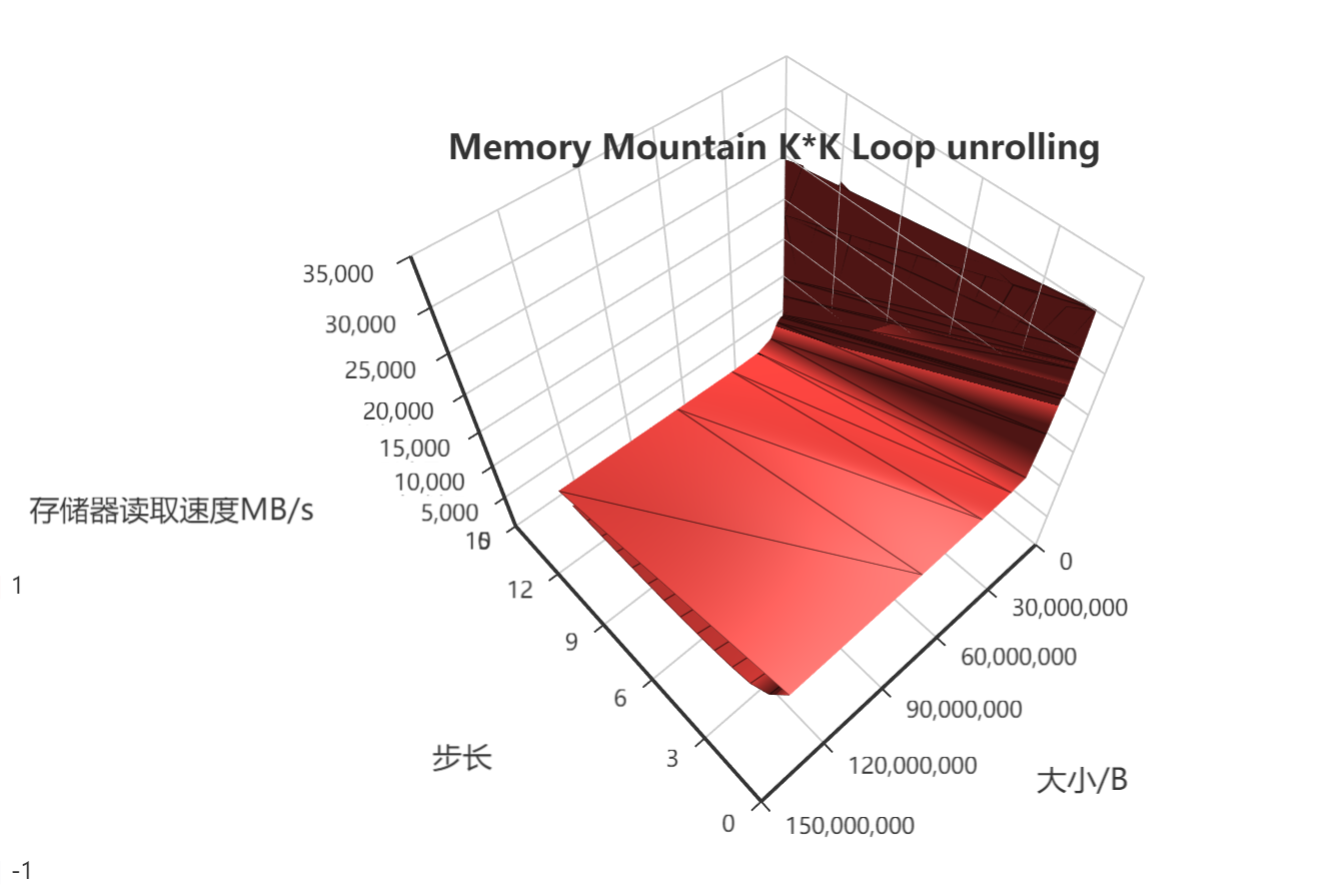
Tips:其实我对于这个绘制出来的结果非常的不自信,不知道是我设置的比例问题,还是因为我不会按照不同的区域来着色导致的视觉差的问题,同我理想当中的存储器山差距有点大,所以如果有热心的小伙伴知道我这是什么问题,或者说知道pyecharts怎么按照不同的区域来对曲面着色的话,请一定留言告诉我!我万分感激!
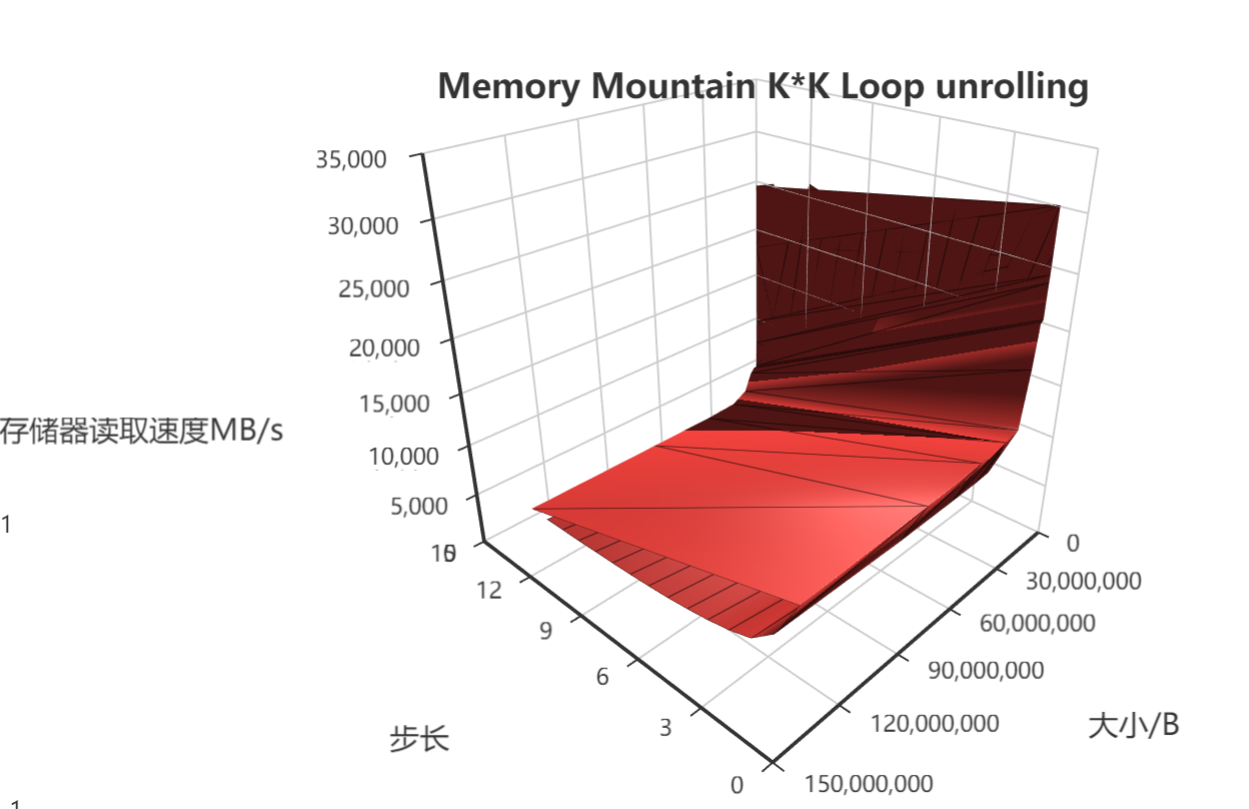
【更新】2019/11/17 上面的问题解决了!
其实这个问题早就解决了,只是一直忘了修改博客了。出现问题的原因在于大小/B的坐标轴,因为按照实际的大小(即测出来的真实值)作为坐标轴就会导致整个高速缓存紧缩在一起了,导致实际绘制渲染出来的图片与书本上的有所差异,其实想一想确实是自己蠢了,整个高速缓存的大小与内存相比无论如何都是没法比的,所以导致了上图那个90度直角的感觉,但是实际上仔细看还是能够看到存储器的分级的。
如何解决?很简单,如果用真实的大小会导致缓存分级的部分紧缩在一堆,那么其实可以就用等间距的“假数据”把大小这个坐标轴给换掉,然后就能够突出缓存分级的区域了,最终效果图如下:
二、Cache Lab Part A:Cache Simulator
1.题目说明以及测试用例、得分点
self-study student可以在CMU相关官网上下载到相应的lab resource以及对lab的英文文档说明,下载传送门:
Self-Study handout
根据说明文档,我做的时候抽取出来的几个关键点,包括格式,注意事项,得分点,以及测试用例:
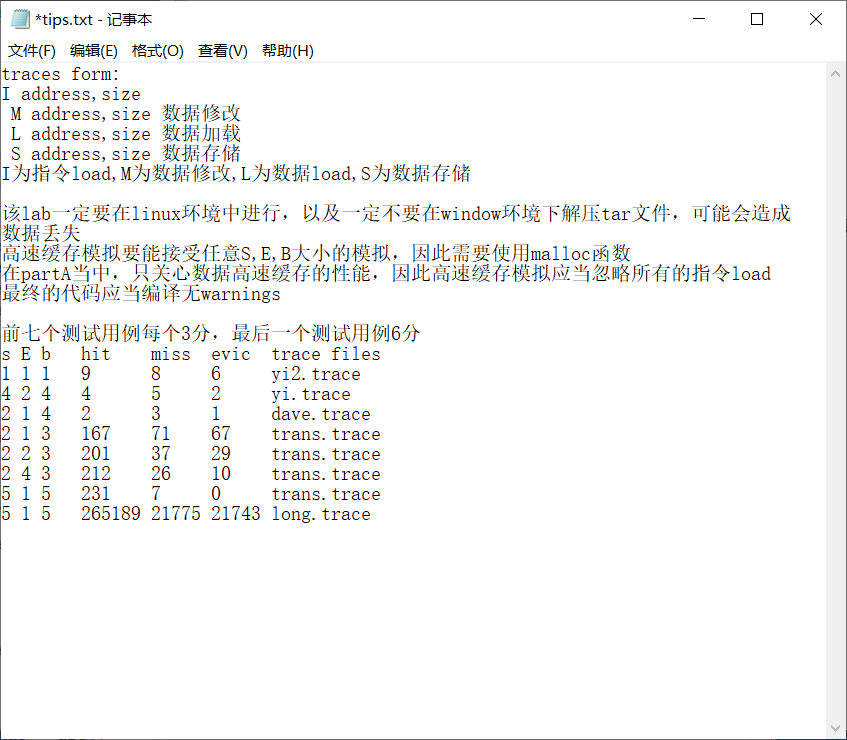
说明文档中,没有给出测试用例的结果,我这里全部测出来了,如下表所示:
| s | E | b | hit_counts | miss_counts | eviction_counts | test trace files | 分值 |
| 1 | 1 | 1 | 9 | 8 | 6 | yi2.trace | 3 |
| 4 | 2 | 4 | 4 | 5 | 2 | yi.trace | 3 |
| 2 | 1 | 4 | 2 | 3 | 1 | dave.trace | 3 |
| 2 | 1 | 3 | 167 | 71 | 67 | trans.trace | 3 |
| 2 | 2 | 3 | 201 | 37 | 29 | trans.trace | 3 |
| 2 | 4 | 3 | 212 | 26 | 10 | trans.trace | 3 |
| 5 | 1 | 5 | 231 | 7 | 0 | trans.trace | 3 |
| 5 | 1 | 5 | 265189 | 21775 | 21743 | long.trace | 6 |
3.代码
话不多说,直接上代码,关于函数接口的设计以及算法和一些细节上的问题已经注释了:
编译时的指令为:gcc -Og -o my_csim_ref csim.c cachelab.c
得到一个可执行文件my_csim_ref
如果代码有问题,可以用gdb调试
#include "cachelab.h"
#include<stdio.h>
#include<stdlib.h>
#include<getopt.h>
#define BUFSIZE 30
void get_opt(); // 获取参数
void init_cache(); // 初始化cache,分配内存
void del_cache(); // 程序结束时释放申请的内存
void load_block(int address,int size); // load指令
void modify_block(long address,int size); // modify指令
void store_block(long address,int size); // store指令
int tag(long address); // 根据地址返回标记值
int set_index(long address); // 根据地址返回组索引
// 行
typedef struct{
int flag;
long tag;
long latest_access_time;
}cache_line;
// 组,为了更加地形象所以这么写,组中有一个指向组内缓冲行的指针
typedef struct{
cache_line *data_lines;
}set;
set *cache=NULL; // cache指针
int S=0,E=0,B=0;
int hit_counts=0,miss_counts=0,eviction_counts=0;
long my_clock=0; // 简单使用一个长整型来抽象表达时间,不科学,但是有效
char *file=NULL; // 保存要用的traces测试文件的文件名,文件名在get_opt()中获取
int main(int argc,char **argv)
{
get_opt(argc,argv);
init_cache();
FILE *test_file_ptr=fopen(file,"r"); // 打开测试文件
char instruction[BUFSIZE];
long addr;
int size;
char buffer[BUFSIZE];
while(fgets(buffer,BUFSIZE,test_file_ptr)!=NULL)
{
// 这里有两个细节问题,首先不能用%c来读取instruction(即说明文档中提到的L,M,S)
// 因为一开始我是用的%c,但是我打印出来后发现和期望值不同
// 其次就是,CMU给的说明文档中说了测试用例中的地址实际上是16进制,我一开始就是
// 当十进制了,结果调试很久很久
sscanf(buffer,"%s %lx,%d",instruction,&addr,&size);
long address=(long)addr;
if(*instruction=='L')load_block(address,size);
else if(*instruction=='M')modify_block(address,size);
else if(*instruction=='S')store_block(address,size);
}
printSummary(hit_counts,miss_counts,eviction_counts); // 打印结果
del_cache(); // 释放内存
return 0;
}
void get_opt(int argc,char **argv)
{
int c;
while((c=getopt(argc,argv,"s:E:b:t:"))!= -1)
{
switch(c)
{
// atoi将字符串转换为数字
case 's':S=atoi(optarg);break;
case 'E':E=atoi(optarg);break;
case 'b':B=atoi(optarg);break;
case 't':file=optarg;break; // 测试文件traces的文件名
}
}
}
void init_cache()
{
int i,j,set_num=1<<S,temp=sizeof(cache_line)*E;
cache=(set*)malloc(sizeof(set)*set_num); // 分配组
for(i=0;i<set_num;i++)
{
cache[i].data_lines=(cache_line*)malloc(temp); // 分配行
for(j=0;j<E;j++)
{
cache[i].data_lines[j].flag=0;
cache[i].data_lines[j].tag=0;
cache[i].data_lines[j].latest_access_time=0;
}
}
}
void del_cache()
{
int i,j,set_num=1<<S; // set_num为2^S==1<<S
for(i=0;i<set_num;i++)
{
free(cache[i].data_lines);
}
free(cache);
}
void load_block(int address,int size)
{
// 这里block_replace必须赋初值,否则结果不会正确
int i,full=1,block_replace=0,set_index_=set_index(address),tag_=tag(address);
int compare_time=cache[set_index_].data_lines[0].latest_access_time;
// 按照CSAPP第六章给出三个步骤:1.组选择 2.行匹配 3.字节偏移
cache_line *line=cache[set_index_].data_lines; // 组选择
for(i=0;i<E;i++) // 行匹配
{
if(line[i].flag==1) // 行有效
{
if(tag_==line[i].tag) // 命中
{
hit_counts++;
line[i].latest_access_time=++my_clock;
break;
}else if(full&&compare_time>line[i].latest_access_time){
// 行有效,但标记不匹配
// 说明文档中要求我们采用LRU算法来进行块的替换
// 这里有一个细节问题,只有在full仍然是真时才需要不断按照LRU思想更新
// block_replace的值,若full已经为假了,就存在空闲块了,不需要使用LRU
// 算法选择块来替换了
compare_time=line[i].latest_access_time;
block_replace=i;
}
}else{ // 行无效,即存在空闲行
full=0;
block_replace=i;
}
}
if(i==E) // 未命中
{
miss_counts++;
line[block_replace].flag=1;
line[block_replace].tag=tag_;
line[block_replace].latest_access_time=++my_clock;
if(full)eviction_counts++; // 产生替换
}
}
void store_block(long address,int size)
{
int i,set_index_=set_index(address),tag_=tag(address);
cache_line *line=cache[set_index_].data_lines;
for(i=0;i<E;i++) // 写命中
{
if(line[i].flag==1&&line[i].tag==tag_)
{
hit_counts++;
line[i].latest_access_time=my_clock;
break;
}
}
if(i==E) // 写不命中,使用写分配法
{
load_block(address,size);
}
}
void modify_block(long address,int size)
{
load_block(address,size);
store_block(address,size);
}
int set_index(long address)
{
return (address>>B)&((1<<S)-1); // 去掉B位,并且只保留S位即为索引位
}
int tag(long address)
{
return (long)address>>(B+S); // 去掉块偏移以及组索引位,剩下的即为标记位
}
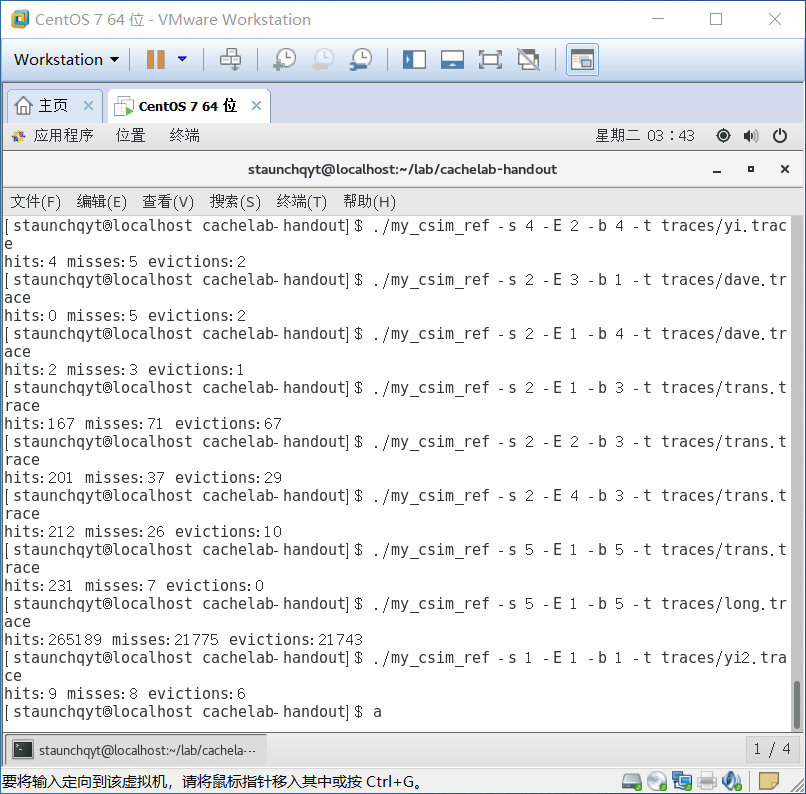
4.结果测试
所有测试用例均通过:
@坚定qinyantang 2019-8-26 by Morty
最后
以上就是洁净水壶最近收集整理的关于CSAPP 存储器山数据的测量以及绘制,Cache lab part A:Cache simulator一、存储器山的数据测量以及绘制的全部内容,更多相关CSAPP内容请搜索靠谱客的其他文章。

![[转][专题学习] [计算几何]](https://www.shuijiaxian.com/files_image/reation/bcimg27.png)

![【转】[专题学习][计算几何]](https://www.shuijiaxian.com/files_image/reation/bcimg2.png)




发表评论 取消回复