TensorFlow 调试程序
tfdbg 是 TensorFlow 的专用调试程序。借助该调试程序,您可以在训练和推理期间查看运行中 TensorFlow 图的内部结构和状态,由于 TensorFlow 的计算图模式,使用通用调试程序(如 Python 的 pdb)很难完成调试。
本指南重点介绍 tfdbg 的命令行界面 (CLI)。有关如何使用 tfdbg 的图形用户界面 (GUI)(即 TensorBoard 调试程序插件)的指导,请访问相关 README 文件。
注意:TensorFlow 调试程序使用基于 curses 的文本界面。在 Mac OS X 上,ncurses 库是必需的,而且可以使用 brew install homebrew/dupes/ncurses 进行安装。在 Windows 上,curses 并没有得到同样的支持,因此基于 readline 的界面可以与 tfdbg 配合使用(具体方法是使用 pip 安装 pyreadline)。如果您使用的是 Anaconda3,则可以使用 "C:Program FilesAnaconda3Scriptspip.exe" install pyreadline 等命令进行安装。您可以在此处下载非官方 Windows curses 软件包,然后使用 pip install <your_version>.whl 进行安装;不过,Windows 上的 curses 可能无法像 Linux 或 Mac 上的 curses 一样稳定地运行。
本教程展示了如何使用 tfdbg CLI 调试出现 nan 和 inf 的问题,这是 TensorFlow 模型开发期间经常出现的一种错误类型。下面的示例适用于使用低阶 TensorFlow Session API 的用户。本文档的后面部分介绍了如何将 tfdbg 与更高阶的 API(即 tf-learn Estimator 和 Experiment)相结合。要观察此类问题,请在不使用调试程序的情况下运行以下命令(可在此处找到源代码):
python -m tensorflow.python.debug.examples.debug_mnist
此代码训练了一个简单的神经网络来识别 MNIST 数字图像。请注意,在完成第一个训练步之后,准确率略有提高,但之后停滞在较低(近机会)水平:
Accuracy at step 0: 0.1113
Accuracy at step 1: 0.3183
Accuracy at step 2: 0.098
Accuracy at step 3: 0.098
Accuracy at step 4: 0.098
您想知道哪里出了问题,怀疑训练图中的某些节点生成了错误数值(例如 inf 和 nan),因为这是导致此类训练失败的常见原因。我们可以使用 tfdbg 来调试此问题,并确定第一次出现此数字问题的确切图节点。
使用 tfdbg 封装 TensorFlow 会话
要向示例中的 tfdbg 添加支持,我们只需添加下列代码行,并使用调试程序封装容器封装会话对象。此代码已添加到 debug_mnist.py 中,因此您可以在命令行中使用 --debug 标记激活 tfdbg CLI。
# Let your BUILD target depend on "//tensorflow/python/debug:debug_py"
# (You don't need to worry about the BUILD dependency if you are using a pip
# install of open-source TensorFlow.)
from tensorflow.python import debug as tf_debug
sess = tf_debug.LocalCLIDebugWrapperSession(sess)
此封装容器与会话具有相同的界面,因此启用调试时不需要对代码进行其他更改。该封装容器还提供其他功能,包括:
- 在每次
Session.run()调用前后调出 CLI,以便您控制执行情况和检查图的内部状态。 - 允许您为张量值注册特殊
filters,以便诊断问题。
在本示例中,我们已经注册了一个名为 tfdbg.has_inf_or_nan 的张量过滤器,它仅仅确定任何中间张量(不是 Session.run() 调用的输入或输出,而是位于从输入到输出的路径中的张量)中是否存在任何 nan 或 inf 值。此过滤器可以确定是否存在 nan 和 inf,这是一种常见的用例,我们在 debug_data 模块中包含了此过滤器。
注意:您还可以自行编写自定义过滤器。要了解详情,请参阅 DebugDumpDir.find() 的 API 文档。
使用 tfdbg 调试模型训练
我们尝试再次训练模型,但这次添加 --debug 标记:
python -m tensorflow.python.debug.examples.debug_mnist --debug
调试封装容器会话会在将要执行第一次 Session.run() 调用时提示您,而屏幕上会显示关于获取的张量和 feed 字典的信息。
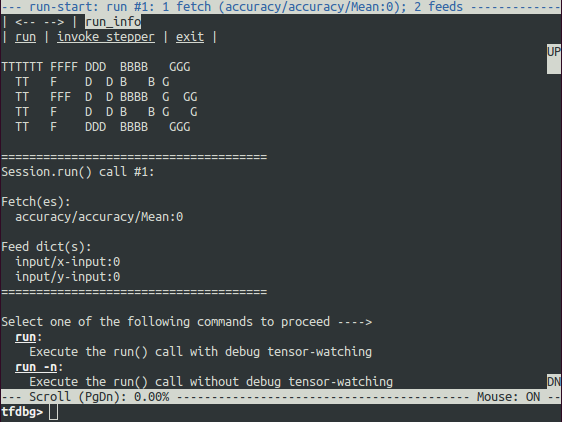
这就是我们所说的 run-start CLI。它先列出对当前 Session.run 调用的 feed 和 fetch,然后再执行任何操作。
如果因屏幕尺寸太小而无法显示完整的消息内容,您可以调整屏幕大小。
使用 PageUp/PageDown/Home/End 键可以浏览屏幕上的输出。在大部分没有这些键的键盘上,使用 Fn + Up/Fn + Down/Fn + Right/Fn + Left 也可以。
在命令提示符处输入 run 命令(或只输入 r):
tfdbg> run
run 命令会让 tfdbg 一直执行,直到下一次 Session.run() 调用结束,而此调用会使用测试数据集计算模型的准确率。tfdbg 会扩展运行时图来转储所有中间张量。运行结束后,tfdbg 会在 run-end CLI 中显示所有转储的张量值。例如:
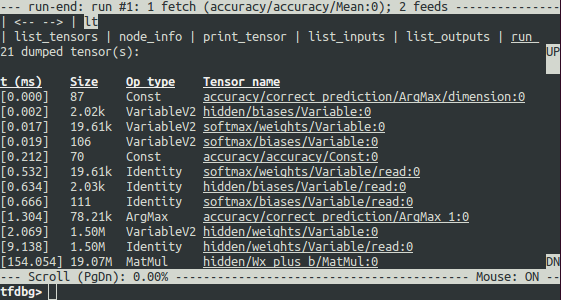
在执行 run 之后运行命令 lt 也可以获得此张量列表。
tfdbg CLI 常用命令
在 tfdbg> 提示符处尝试下列命令(参考 tensorflow/python/debug/examples/debug_mnist.py 中的代码):
| 命令 | 语法或选项 | 说明 | 示例 |
|---|---|---|---|
lt | 列出转储张量。 | lt | |
-n <name_pattern> | 列出名称符合指定正则表达式格式的转储张量。 | lt -n Softmax.* | |
-t <op_pattern> | 列出指令类型符合指定正则表达式格式的转储张量。 | lt -t MatMul | |
-f <filter_name> | 列出仅通过已注册张量过滤器的张量。 | lt -f has_inf_or_nan | |
-f <filter_name> -fenn <regex> | 列出仅通过已注册张量过滤器的张量,不包括名称符合正则表达式的节点。 | lt -f has_inf_or_nan-fenn .*Sqrt.* | |
-s <sort_key> | 按指定的 sort_key 对输出进行排序,该键可能的值为 timestamp(默认)、dump_size、op_type 和 tensor_name。 | lt -s dump_size | |
-r | 按相反的顺序排序。 | lt -r -s dump_size | |
pt | 输出转储张量的值。 | ||
pt <tensor> | 输出张量值。 | pt hidden/Relu:0 | |
pt <tensor>[slicing] | 使用 Numpy 样式的数组切片输出张量的子数组。 | pt hidden/Relu:0[0:50,:] | |
-a | 输出整个大张量,而不使用省略号(对于大张量来说可能需要很长时间)。 | pt -a hidden/Relu:0[0:50,:] | |
-r <range> | 突出显示属于指定数值范围的元素。可以结合使用多个范围。 | pt hidden/Relu:0 -a -r [[-inf,-1],[1,inf]] | |
-n <number> | 输出编号对应于指定转储编号(从 0 开始)的转储。具有多个转储的张量必须如此。 | pt -n 0 hidden/Relu:0 | |
-s | 包括张量的数值摘要(仅适用于布尔型和数字型(例如 int* 和 float*)的非空张量)。 | pt -s hidden/Relu:0[0:50,:] | |
-w | 使用 numpy.save() 将张量(可能已切片)的值写入 Numpy 文件 | pt -s hidden/Relu:0 -w /tmp/relu.npy | |
@[coordinates] | 转到 pt 输出中的指定元素。 | @[10,0] 或 @10,0 | |
/regex | 指定正则表达式的 less 样式搜索。 | /inf | |
/ | 滚动到下一行,其中显示所搜索的正则表达式的匹配结果(如果有的话)。 | / | |
pf | 输出 Session.run 的 feed_dict 中的一个值。 | ||
pf <feed_tensor_name> | 输出 feed 的值。另请注意,pf 命令具有 -a、-r 和 -s 标记(未在下面列出),它们与 pt 的同名标记具有相同的语法和语义。 | pf input_xs:0 | |
| eval | 评估任意 Python 和 Numpy 表达式。 | ||
eval <expression> | 评估 Python/Numpy 表达式,其中 np 表示 Numpy,调试张量名称用反引号引起来。 | eval "np.matmul((`output/Identity:0` / `Softmax:0`).T,`Softmax:0`)" | |
-a | 输出很长的完整评估结果,即不使用省略号。 | eval -a 'np.sum(`Softmax:0`, axis=1)' | |
-w | 使用 numpy.save() 将评估结果写入 Numpy 文件中 | eval -a 'np.sum(`Softmax:0`, axis=1)' -w /tmp/softmax_sum.npy | |
ni | 显示节点信息。 | ||
-a | 在输出中包含节点属性。 | ni -a hidden/Relu | |
-d | 列出节点中的调试转储。 | ni -d hidden/Relu | |
-t | 显示节点创建的 Python 堆栈追踪。 | ni -t hidden/Relu | |
li | 列出节点的输入 | ||
-r | 递归地列出节点的输入(输入树)。 | li -r hidden/Relu:0 | |
-d <max_depth> | 在 -r 模式下限制递归深度。 | li -r -d 3 hidden/Relu:0 | |
-c | 包含控制输入。 | li -c -r hidden/Relu:0 | |
-t | 显示输入节点的指令类型。 | li -t -r hidden/Relu:0 | |
lo | 列出节点的输出接收方 | ||
-r | 递归地列出节点的输出接收方(输出树)。 | lo -r hidden/Relu:0 | |
-d <max_depth> | 在 -r 模式下限制递归深度。 | lo -r -d 3 hidden/Relu:0 | |
-c | 包含经由控制边缘的接收方。 | lo -c -r hidden/Relu:0 | |
-t | 显示接收方节点的指令类型。 | lo -t -r hidden/Relu:0 | |
ls | 列出节点创建中所涉及的 Python 源文件。 | ||
-p <path_pattern> | 限制源文件的输出符合指定正则表达式路径格式。 | ls -p .*debug_mnist.* | |
-n | 限制节点名称的输出符合指定正则表达式格式。 | ls -n Softmax.* | |
ps | 输出 Python 源文件。 | ||
ps <file_path> | 输出指定 Python 源文件 source.py,每行用在此行创建的节点进行注解(如果有)。 | ps /path/to/source.py | |
-t | 执行关于张量(而不是默认的节点)的注解。 | ps -t /path/to/source.py | |
-b <line_number> | 从 source.py 的指定行开始注解。 | ps -b 30 /path/to/source.py | |
-m <max_elements> | 限制每行注解中的元素数量。 | ps -m 100 /path/to/source.py | |
run | 继续下一个 Session.run() | run | |
-n | 执行到下一次 Session.run(无需调试),然后在开始下一次运行之前进入 CLI。 | run -n | |
-t <T> | 执行 T - 1 次 Session.run(无需调试),接着执行一次运行(需要调试)。然后,在执行需要调试的运行之后进入 CLI。 | run -t 10 | |
-f <filter_name> | 继续执行 Session.run,直到任何中间张量触发指定的张量过滤器(导致过滤器返回 True)为止。 | run -f has_inf_or_nan | |
-f <filter_name> -fenn <regex> | 继续执行 Session.run,直到其节点名称不符合正则表达式的任何中间张量触发指定的张量过滤器(导致过滤器返回 True)为止。 | run -f has_inf_or_nan -fenn .*Sqrt.* | |
--node_name_filter <pattern> | 执行下一次 Session.run,仅查看名称符合指定正则表达式格式的节点。 | run --node_name_filter Softmax.* | |
--op_type_filter <pattern> | 执行下一次 Session.run,仅查看指令类型符合指定正则表达式格式的节点。 | run --op_type_filter Variable.* | |
--tensor_dtype_filter <pattern> | 执行下一次 Session.run,仅转储数据类型 (dtype) 符合指定正则表达式格式的张量。 | run --tensor_dtype_filter int.* | |
-p | 在分析模式下执行下一次 Session.run 调用。 | run -p | |
ri | 显示有关运行当前运行的信息,包括 fetch 和 feed。 | ri | |
config | 设置或显示永久性 TFDBG 界面配置。 | ||
set | 设置配置项的值:{graph_recursion_depth, mouse_mode}。 | config set graph_recursion_depth 3 | |
show | 显示当前的永久性界面配置。 | config show | |
help | 输出常规帮助信息 | help | |
help <command> | 输出指定命令的帮助信息。 | help lt |
请注意,每次输入命令时,都会显示新的屏幕输出。这有点类似于浏览器中的网页。您可以通过点击 CLI 左上角附近的 <-- 和 --> 文本箭头在这些屏幕之间导航。
tfdbg CLI 的其他功能
除了上面列出的命令外,tfdbg CLI 还提供了下列其他功能:
- 要浏览之前的 tfdbg 命令,请输入几个字符,然后按向上或向下箭头键。tfdbg 会向您显示以这些字符开头的命令的历史记录。
- 要浏览屏幕输出的历史记录,请执行下列任一操作:
- 使用
prev和next命令。 - 点击屏幕左上角附近带下划线的
<--和-->链接。
- 使用
- 命令(和一些命令参数)的 Tab 补齐功能。
- 要将屏幕输出重定向到文件(而不是屏幕),请使用 bash 样式重定向结束命令。例如,以下命令会将 pt 命令的输出重定向到
/tmp/xent_value_slices.txt文件:
tfdbg> pt cross_entropy/Log:0[:, 0:10] > /tmp/xent_value_slices.txt
查找 nan 和 inf
在第一个 Session.run() 调用中,没有出现存在问题的数值。您可以使用命令 run 或其简写形式 r 转到下一次运行。
提示:如果您反复输入
run或r,则将能够依序在Session.run()调用之间移动。您还可以使用
-t标记一次向前移动多个Session.run()调用,例如:tfdbg> run -t 10
在每次 Session.run() 调用之后,您无需重复输入 run 并在 run-end 界面中手动搜索 nan 和 inf(例如,通过使用上表中显示的 pt 命令),而是可以使用以下命令让调试程序反复执行 Session.run() 调用(不在 run-start 或 run-end 提示符处停止),直到第一个 nan 或 inf 值出现在图中。这类似于一些程序式语言调试程序中的条件断点:
tfdbg> run -f has_inf_or_nan
注意:上述命令可正常运行,因为在创建封装会话时已为您注册了一个名为
has_inf_or_nan的张量过滤器。此过滤器会检测nan和inf(如前所述)。如果您已注册任何其他过滤器,则可以使用“run -f”让 tfdbg 一直运行,直到任何张量触发该过滤器(导致过滤器返回 True)为止。def my_filter_callable(datum, tensor):
# A filter that detects zero-valued scalars.
return len(tensor.shape) == 0 and tensor == 0.0
sess.add_tensor_filter('my_filter', my_filter_callable)然后在 tfdbg run-start 提示符处运行,直到您的过滤器被触发:
tfdbg> run -f my_filter
请参阅此 API 文档,详细了解与 add_tensor_filter() 搭配使用的谓词 Callable 的预期签名和返回值。
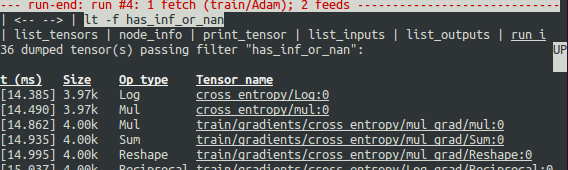
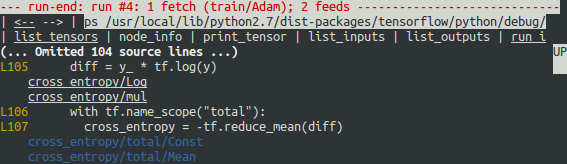
如屏幕所示,在第一行中,has_inf_or_nan 过滤器在第四次 Session.run() 调用期间第一次被触发:Adam 优化器前向-后向训练通过了图。在本次运行中,36 个(共 95 个)中间张量包含 nan或 inf 值。这些张量按时间先后顺序列出,具体时间戳显示在左侧。在列表顶部,您可以看到第一次出现错误数值的第一个张量:cross_entropy/Log:0。
要查看张量的值,请点击带下划线的张量名称 cross_entropy/Log:0 或输入等效命令:
tfdbg> pt cross_entropy/Log:0
向下滚动一点,您会发现一些分散的 inf 值。如果很难用肉眼找到出现 inf 和 nan 的地方,可以使用以下命令执行正则表达式搜索并突出显示输出:
tfdbg> /inf
或者:
tfdbg> /(inf|nan)
您还可以使用 -s 或 --numeric_summary 命令获取张量中的数值类型的快速摘要:
tfdbg> pt -s cross_entropy/Log:0
您可以从摘要中看到 cross_entropy/Log:0 张量的若干个元素(共 1000 个)都是 -inf(负无穷大)。
为什么会出现这些负无穷大的值?为了进一步进行调试,通过点击顶部带下划线的 node_info 菜单项或输入等效的 node_info (ni) 命令,显示有关节点 cross_entropy/Log 的更多信息:
tfdbg> ni cross_entropy/Log
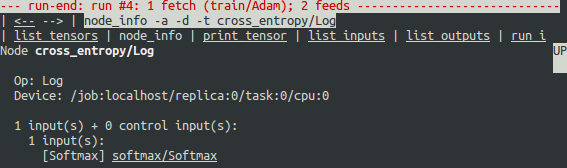
您可以看到,此节点的指令类型为 Log,输入为节点 Softmax。运行以下命令可进一步查看输入张量:
tfdbg> pt Softmax:0
检查输入张量中的值,并搜索其中是否存在零:
tfdbg> /0.000
确实存在零。现在很明显,错误数值的根源是节点 cross_entropy/Log 取零的对数。要在 Python 源代码中找出导致错误的行,请使用 ni 命令的 -t 标记来显示节点构造的回溯:
tfdbg> ni -t cross_entropy/Log
如果您点击屏幕顶部的“node_info”,tfdbg 会自动显示节点构造的回溯。
从回溯中可以看到该操作是在以下行构建的 - debug_mnist.py:
diff = y_ * tf.log(y)
tfdbg 有一个可以轻松将张量和指令追溯到 Python 源文件中的行的功能。它可以用行创建的指令或张量注解 Python 文件的行。要使用此功能,只需点击 ni -t <op_name> 命令的堆栈追踪输出中带下划线的行编号,或者使用 ps(或 print_source)命令,例如:ps /path/to/source.py。例如,以下屏幕截图显示了 ps 命令的输出。
解决问题
要解决此问题,请修改 debug_mnist.py,将原始行:
diff = -(y_ * tf.log(y))
更改为 softmax 交叉熵的在数值上稳定的内置实现:
diff = tf.losses.sparse_softmax_cross_entropy(labels=y_, logits=logits)
用 --debug 标记重新运行,如下所示:
python -m tensorflow.python.debug.examples.debug_mnist --debug
在 tfdbg> 提示符处输入以下命令:
run -f has_inf_or_nan`
确认没有任何张量被标记为包含 nan 或 inf 值,并且准确率现在继续上升(而不是停滞不变)。大功告成!
调试 tf-learn Estimator 和 Experiment
本部分介绍了如何调试使用 Estimator 和 Experiment API 的 TensorFlow 程序。这些 API 提供的部分便利性是它们在内部管理 Session。这样一来,上面的部分介绍的 LocalCLIDebugWrapperSession 就不适用了。幸运的是,您仍然可以使用 tfdbg 提供的特殊 hook 对其进行调试。
调试 tf.contrib.learn Estimator
目前,tfdbg 可以调试 tf-learn Estimator 的 fit() 和 evaluate() 方法。要调试 Estimator.fit(),请创建一个 LocalCLIDebugHook 并将其用作 monitors 参数的一部分。例如:
# First, let your BUILD target depend on "//tensorflow/python/debug:debug_py"
# (You don't need to worry about the BUILD dependency if you are using a pip
# install of open-source TensorFlow.)
from tensorflow.python import debug as tf_debug
# Create a LocalCLIDebugHook and use it as a monitor when calling fit().
hooks = [tf_debug.LocalCLIDebugHook()]
classifier.fit(x=training_set.data,
y=training_set.target,
steps=1000,
monitors=hooks)
要调试 Estimator.evaluate(),请为 hooks 参数分配钩子,如下例所示:
accuracy_score = classifier.evaluate(x=test_set.data,
y=test_set.target,
hooks=hooks)["accuracy"]
debug_tflearn_iris.py(基于 tf-learn 的鸢尾花教程)包含如何搭配使用 tfdbg 和 Estimator 的完整示例。要运行此示例,请执行以下操作:
python -m tensorflow.python.debug.examples.debug_tflearn_iris --debug
调试 tf.contrib.learn Experiment
在 tf.contrib.learn 中,Experiment 是一个比 Estimator 更高级别的构造。它提供了用于训练和评估模型的单个界面。为了调试对 Experiment 对象的 train() 和 evaluate() 调用,在调用该对象的构造函数时,您可以分别使用关键字参数 train_monitors 和 eval_hooks。例如:
# First, let your BUILD target depend on "//tensorflow/python/debug:debug_py"
# (You don't need to worry about the BUILD dependency if you are using a pip
# install of open-source TensorFlow.)
from tensorflow.python import debug as tf_debug
hooks = [tf_debug.LocalCLIDebugHook()]
ex = experiment.Experiment(classifier,
train_input_fn=iris_input_fn,
eval_input_fn=iris_input_fn,
train_steps=FLAGS.train_steps,
eval_delay_secs=0,
eval_steps=1,
train_monitors=hooks,
eval_hooks=hooks)
ex.train()
accuracy_score = ex.evaluate()["accuracy"]
要在 Experiment 模式下构建并运行 debug_tflearn_iris 示例,请执行以下操作:
python -m tensorflow.python.debug.examples.debug_tflearn_iris
--use_experiment --debug
LocalCLIDebugHook 还允许您配置 watch_fn,后者可用于灵活指定在不同的 Session.run() 调用期间要查看哪些 Tensor,这些调用作为 fetches 和 feed_dict 以及其他状态的函数。如需了解详情,请参阅此 API 文档。
使用 TFDBG 调试 Keras 模型
要结合使用 TFDBG 和 Keras,请允许 Keras 后端使用 TFDBG 封装的会话对象。例如,要使用 CLI 封装容器:
import tensorflow as tf
from keras import backend as keras_backend
from tensorflow.python import debug as tf_debug
keras_backend.set_session(tf_debug.LocalCLIDebugWrapperSession(tf.Session()))
# Define your keras model, called "model".
model.fit(...) # This will break into the TFDBG CLI.
使用 TFDBG 调试 tf-slim
TFDBG 支持对 tf-slim 进行训练和评估调试。如下所述,训练和评估需要略微不同的调试工作流程。
在 tf-slim 中调试训练流程
要调试训练流程,需要将 LocalCLIDebugWrapperSession 提供给 slim.learning.train() 的 session_wrapper 参数。例如:
import tensorflow as tf
from tensorflow.python import debug as tf_debug
# ... Code that creates the graph and the train_op ...
tf.contrib.slim.learning.train(
train_op,
logdir,
number_of_steps=10,
session_wrapper=tf_debug.LocalCLIDebugWrapperSession)
在 tf-slim 中调试评估流程
要调试评估流程,需要将 LocalCLIDebugHook 提供给 slim.evaluation.evaluate_once() 的 hooks 参数。例如:
import tensorflow as tf
from tensorflow.python import debug as tf_debug
# ... Code that creates the graph and the eval and final ops ...
tf.contrib.slim.evaluation.evaluate_once(
'',
checkpoint_path,
logdir,
eval_op=my_eval_op,
final_op=my_value_op,
hooks=[tf_debug.LocalCLIDebugHook()])
离线调试远程运行的会话
您的模型往往在您没有终端访问权限的远程机器或进程上运行。要在这种情况下调试模型,您可以使用 tfdbg 的 offline_analyzer 二进制文件(如下所述)。它在转储的数据目录上运行。可以对较低阶的 Session API 以及较高阶的 Estimator 和 Experiment API 执行此操作。
调试远程 tf.Sessions
如果您直接与 python 版 tf.Session API 互动,则可以使用方法 tfdbg.watch_graph 配置 RunOptions 原型(您使用此原型调用 Session.run() 方法)。这样一来,在发生 Session.run() 调用时,中间张量和运行时图会被转储到您选择的共享存储位置(以降低性能为代价)。例如:
from tensorflow.python import debug as tf_debug
# ... Code where your session and graph are set up...
run_options = tf.RunOptions()
tf_debug.watch_graph(
run_options,
session.graph,
debug_urls=["file:///shared/storage/location/tfdbg_dumps_1"])
# Be sure to specify different directories for different run() calls.
session.run(fetches, feed_dict=feeds, options=run_options)
之后,在您拥有终端访问权限的环境(例如,一台可以访问上述代码指定的共享存储位置的本地计算机)中,您可以使用 tfdbg 的 offline_analyzer 二进制文件加载和检查共享存储上的转储目录中的数据。例如:
python -m tensorflow.python.debug.cli.offline_analyzer
--dump_dir=/shared/storage/location/tfdbg_dumps_1
Session 封装容器 DumpingDebugWrapperSession 提供了一种更简单、更灵活的方法来生成可离线分析的文件系统转储。要使用该方法,只需将您的会话封装到 tf_debug.DumpingDebugWrapperSession 中即可。例如:
# Let your BUILD target depend on "//tensorflow/python/debug:debug_py
# (You don't need to worry about the BUILD dependency if you are using a pip
# install of open-source TensorFlow.)
from tensorflow.python import debug as tf_debug
sess = tf_debug.DumpingDebugWrapperSession(
sess, "/shared/storage/location/tfdbg_dumps_1/", watch_fn=my_watch_fn)
watch_fn 参数接受 Callable,而后者允许您配置在不同的 Session.run() 调用期间要查看哪些 tensor,这些调用作为 run() 调用的 fetches 和 feed_dict 及其他状态的函数。
C++ 和其他语言
如果您的模型代码是采用 C++ 或其他语言编写的,则您还可以修改 RunOptions 的 debug_options 字段以生成可离线检查的调试转储。要了解详情,请参阅原型定义。
调试远程运行的 tf-learn Estimator 和 Experiment
如果您在远程 TensorFlow 服务器上运行 Estimator,则您可以使用非交互式 DumpingDebugHook。例如:
# Let your BUILD target depend on "//tensorflow/python/debug:debug_py
# (You don't need to worry about the BUILD dependency if you are using a pip
# install of open-source TensorFlow.)
from tensorflow.python import debug as tf_debug
hooks = [tf_debug.DumpingDebugHook("/shared/storage/location/tfdbg_dumps_1")]
然后,可以按照与本文档前面部分介绍的 LocalCLIDebugHook 示例一样的方法使用此 hook。在训练和/或评估 Estimator 或 Experiment 期间,tfdbg 会创建具有以下名称格式的目录:/shared/storage/location/tfdbg_dumps_1/run_<epoch_timestamp_microsec>_<uuid>。每个目录对应一个 Session.run() 调用,而此调用会成为 fit() 或 evaluate() 调用的基础。您可以使用 tfdbg 提供的 offline_analyzer 加载这些目录并以离线方式在命令行界面中进行检查。例如:
python -m tensorflow.python.debug.cli.offline_analyzer
--dump_dir="/shared/storage/location/tfdbg_dumps_1/run_<epoch_timestamp_microsec>_<uuid>"
常见问题解答
问:lt 输出左侧的时间戳是否反映了非调试会话的实际性能?
答:否。调试程序在图中插入了其他特殊用途的调试节点来记录中间张量的值。这些节点减缓了图的执行。如果您对分析模型感兴趣,请查看:
- tfdbg 的分析模式:
tfdbg> run -p。 - tfprof 和 TensorFlow 的其他分析工具。
问:如何在 Bazel 中将 tfdbg 与我的 Session 关联起来?为什么我会看到“ImportError: cannot import name debug”这样的错误?
答:在您的 BUILD 规则中,声明依赖项 "//tensorflow:tensorflow_py" 和 "//tensorflow/python/debug:debug_py"。所包含的第一个依赖项让您即使没有调试程序支持也可以使用 TensorFlow;第二个用于启用调试程序。然后,在您的 Python 文件中,添加:
from tensorflow.python import debug as tf_debug
# Then wrap your TensorFlow Session with the local-CLI wrapper.
sess = tf_debug.LocalCLIDebugWrapperSession(sess)
问:tfdbg 是否可以帮助调试运行时错误(例如形状不匹配)?
答:可以。tfdbg 在运行时期间会拦截指令生成的错误,并在 CLI 中向用户显示具体错误以及一些调试说明。请查看下面的示例:
# Debugging shape mismatch during matrix multiplication.
python -m tensorflow.python.debug.examples.debug_errors
--error shape_mismatch --debug
# Debugging uninitialized variable.
python -m tensorflow.python.debug.examples.debug_errors
--error uninitialized_variable --debug
问:如何让 tfdbg 封装的会话或钩子仅通过主线程运行调试模式?
答:这是一个常见用例,其中 Session 对象同时在多个线程中使用。通常情况下,子线程负责后台任务,例如运行入列指令。您通常仅需要调试主线程(或者不太频繁地仅调试一个子线程)。您可以使用 LocalCLIDebugWrapperSession 的 thread_name_filter 关键字参数实现这种类型的线程选择性调试。例如,您要仅通过主线程进行调试,请按如下方式构造一个封装的 Session:
sess = tf_debug.LocalCLIDebugWrapperSession(sess, thread_name_filter="MainThread$")
以上示例的前提是 Python 中的主线程具有默认名称 MainThread。
问:我正在调试的模型非常大。tfdbg 转储的数据占满了磁盘的可用空间。我该怎么做?
答:出现以下任何情况,您都可能会遇到此问题:
- 模型具有很多中间张量
- 中间张量非常大
- 很多
tf.while_loop迭代
有三种可能的解决方案:
LocalCLIDebugWrapperSession和LocalCLIDebugHook的构造函数提供了一个关键字参数dump_root,用于指定 tfdbg 转储调试数据的路径。您可以使用此参数让 tfdbg 将调试数据转储到可用空间比较多的磁盘上。例如:
# For LocalCLIDebugWrapperSession
sess = tf_debug.LocalCLIDebugWrapperSession(dump_root="/with/lots/of/space")
# For LocalCLIDebugHook
hooks = [tf_debug.LocalCLIDebugHook(dump_root="/with/lots/of/space")]
确保 dump_root 指向的目录为空或不存在。 tfdbg 在退出之前会清理转储目录。
- 减小在运行期间使用的批次大小。
-
使用 tfdbg 的
run命令的过滤选项只查看图形中的特定节点。例如:tfdbg> run --node_name_filter .*hidden.*
tfdbg> run --op_type_filter Variable.*
tfdbg> run --tensor_dtype_filter int.*上面的第一个命令仅查看名称符合正则表达式格式
.*hidden.*的节点。上面的第二个命令仅查看名称符合格式Variable.*的操作。上面的第三个命令仅查看 dtype 符合格式int.*(例如int32)的张量。
问:为什么不能在 tfdbg CLI 中选择文本?
答:这是因为 tfdbg CLI 默认在终端中启用了鼠标事件。此 mouse-mask 模式会替换默认的终端交互,包括文本选择。您可以通过使用命令 mouse off 或 m off 来重新启用文本选择。
问:为什么我在调试如下代码时,tfdbg CLI 没有显示转储的张量?
a = tf.ones([10], name="a")
b = tf.add(a, a, name="b")
sess = tf.Session()
sess = tf_debug.LocalCLIDebugWrapperSession(sess)
sess.run(b)
答:您之所以没有看到转储数据,是因为执行的 TensorFlow 图中的每个节点都由 TensorFlow 运行时进行了常数折叠处理。在本示例中,a 是一个常数张量;因此,已获取的张量 b 其实也是一个常数张量。TensorFlow 的图优化将包含 a 和 b 的图折叠成单个节点,以加快图的未来运行速度,因此,tfdbg 不会生成任何中间张量转储。不过,如果 a 是一个 tf.Variable,如下例所示:
import numpy as np
a = tf.Variable(np.ones[10], name="a")
b = tf.add(a, a, name="b")
sess = tf.Session()
sess.run(tf.global_variables_initializer())
sess = tf_debug.LocalCLIDebugWrapperSession(sess)
sess.run(b)
则不会发生常数折叠,tfdbg 应显示中间张量转储。
问:我正在调试一个产生垃圾无穷数或 NaN 的模型。但是,我的模型中有一些节点已知会在输出张量中产生无穷值或 NaN,即使在完全正常的条件下也是如此。我如何在 run -f has_inf_or_nan操作期间跳过这些节点?
答:使用 --filter_exclude_node_names(简称为 -fenn)标记。例如,如果您知道您有一个名称符合正则表达式 .*Sqrt.* 的节点,无论模型是否正常运行,该节点都会产生无穷数或 NaN,那么您可以使用命令 run -f has_inf_or_nan -fenn .*Sqrt.*,将节点从无穷数/NaN-finding 运行中排除。
问:是否有用于 tfdbg 的 GUI?
答:有,TensorBoard 调试程序插件就是 tfdbg 的 GUI。它提供了诸如计算图检查、张量值实时可视化、张量连续性和条件性断点以及将张量关联到其图形构建源代码等功能,所有这些功能都在浏览器环境中运行。要开始使用,请访问相关 README 文件。
Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 3.0 License, and code samples are licensed under the Apache 2.0 License. For details, see our Site Policies. Java is a registered trademark of Oracle and/or its affiliates.
上次更新日期:七月 9, 2018
最后
以上就是乐观大白最近收集整理的关于tensorflow tfdbg 调试手段来自墙外TensorFlow 调试程序的全部内容,更多相关tensorflow内容请搜索靠谱客的其他文章。








发表评论 取消回复